引言
在我们接触大规模的数据集时,数据的数量往往会让人望而却步。数据分析、机器学习等领域的专业人员需要对这些数据进行处理,以便更好地理解数据,以及利用数据进行预测。然而,处理大规模数据的计算成本往往非常高,这时候,就需要引入下采样(Downsampling)的技术了。
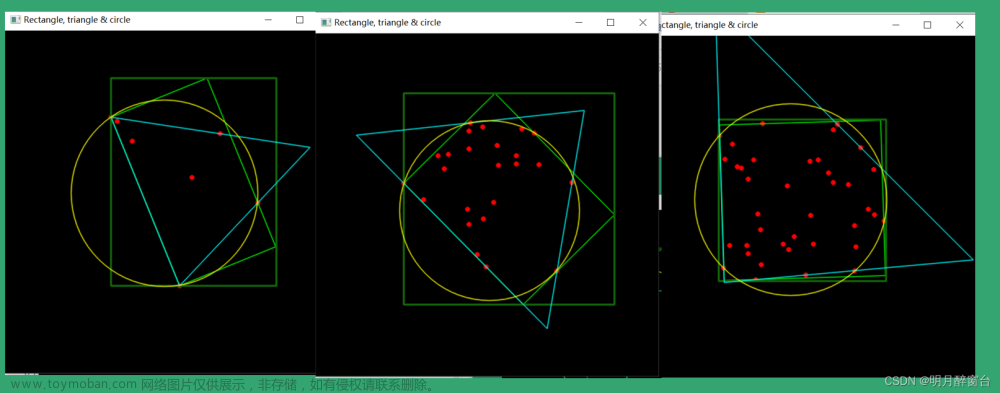
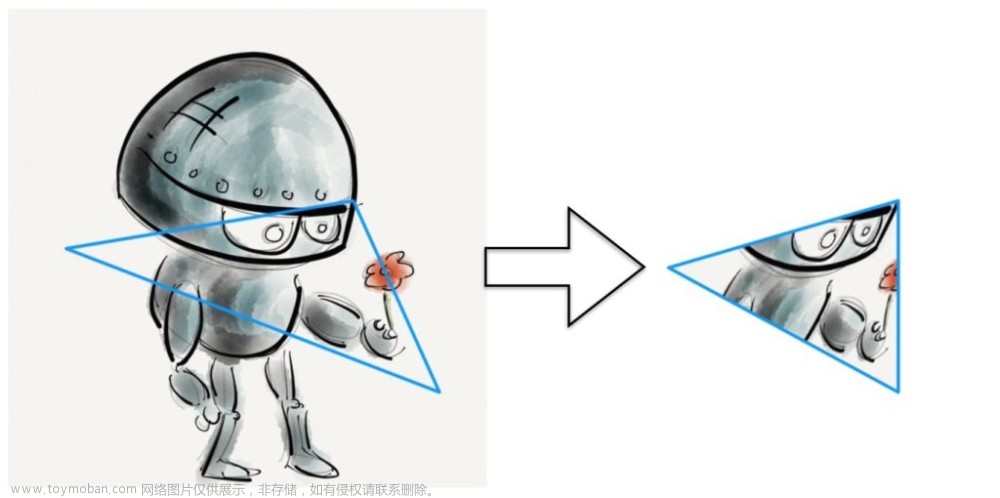
下采样是一种降低数据规模的技术,简单来说,就是在大规模的数据中选取一部分代表性的数据来进行后续的分析和计算。其中,最大三角形三桶(Largest Triangle Three Buckets,简称LTTB)是一种非常高效的下采样技术。该方法不仅降低了数据规模,而且能够尽可能地保留原始数据的特性。
本文将深入解析LTTB算法,并在Python环境中实现该算法,向大家展示如何处理大规模数据。
数据预处理和Python环境设置
要开始实现我们的LTTB算法,首先我们需要一些数据。我们会使用Python的Numpy库生成一些模拟数据,并使用Matplotlib库进行可视化。
首先,让我们安装和导入需要的库。文章来源:https://www.toymoban.com/news/detail-625272.html
!pip install numpy matplotlib
import numpy as np
import matplotlib.pyplot as plt
接下来&文章来源地址https://www.toymoban.com/news/detail-625272.html
到了这里,关于使用Python实现高效数据下采样:详解最大三角形三桶(LTTB)算法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!