一、 Apollo 6.0激光雷达感知模块
1.1 激光雷达简介

感知模块检测效果:
左边为摄像头拍摄图像,激光雷达感知不依赖左边CAMERA,而是点云数据对应的效果图(黄色上方数字为Tracking ID)
主车红灯时的激光点云检测效果图
1.2 激光雷达感知模块

车道线给CAMERA提供一个标定参考,使得camera检测出来的障碍物从2维转化为3维的信息,因为此标定的参考,转化将更为精确;最后才做camera的目标跟踪。
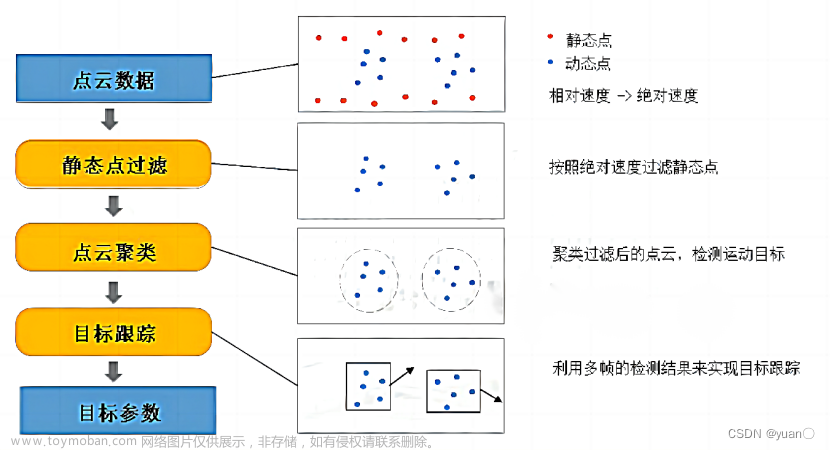
首先从LIDER拿到点云数据,进行预处理,比如:去掉一些异常值的点(空值点,异常大的值或者截取一定范围内的点云数据);接着对点云做目标检测(输出障碍物,带有位置信息的障碍物);再对障碍物做目标跟踪,结合前几帧的信息根据Tracking ID判断障碍物的速度和朝向;最后再融合其它传感器,障碍物信息结果进行输出。
感知特点:全新算法,检测精准(PointPillars)
毫秒感知,实时可靠(10hz输出)
1.3 3D障碍物检测流程

左边为一个点云图,对其编码后转化为算法更容易理解更抽象的特征;再由网络/模型对左边提取出关键特征,再解码为我们需要的障碍物2维框,右图里绿色的框(框包围住了障碍物)。
二 、基于PointPillars的激光雷达点云检测算法
2.1 基于Voxel的3D目标检测

先前方法将点云数据转化为BEV(BirdsEyeView)再进行处理,实质是压缩后进行处理(有损压缩,并非原始数据处理),那么为了提升效果就需要结合多传感器共同提高效果;而Voxel则不需要,点云分割为小格子,直接对点云数据做处理,通过LIDAR的数据结合神经网络层提取特征图。
但是Voxel需要进行三维卷积,耗时,占内存。
较之VoxelNet,去掉了3维卷积,简化为2维卷积,精度速度都更高效。
最大区别:点云转化为BEV的过程,PointPillars并非分割为小格子,而是按照xy平面网格划分为竖立的柱子,
2.2 PointPillars模型原理讲解

PFE是对VFE的一种简化。VFE得到global特征后会再复制一份与原始数据进行拼接。
2.3 PointPillars的改进
2.3.1 损失函数

Focal loss提出是为了缓解分类任务正负样本比例不均衡,α和γ为两个超参数,需要预先设定来调整损失函数的效果;但是用加权softmax函数后泛化性更好,检测效果也有所改善(其实就是对不同的类别加不同的权重)
2.3.2. Pillar特征编码

即PFE。此处改进在拿到点特征的时候,这个点云包含改点xy坐标和激光雷达反射率,也可以包含其他特征;先对xy做一个radius替换,初步变换,再进行下续操作;
为何用radius替换点特征呢
原点即为激光雷达传感器,x为车正前方,y为车正左方。
降了一维。
RPN是把点云转化为BEV特征图后的一个网络,用来输出最后的检测框和类别。
通过预先在网格点上设定好初始检测框,然后对应到特征图(通过卷积层得到的特征图)上面,通过后续处理得到候选框包含目标的概率分布值和候选框包含目标其目标对应的类别的概率分数,最后从候选框中选出模型要输出的目标。
Proposals 候选框:anchor, 2维检测里边,同一个目标在不同拍摄角度在图像里的尺寸不一(近则大,远则小),所以设定不同的anchor来进行匹配。
对点云做检测,右侧为检测后的图,
点云里边同一种目标经常是大小,甚至长宽高比例相似,比如图例的小轿车大小接近,就可以设定初始大小值为anchor初始值,
点云直接的距离是真实物理大小,和图像有区别,不需要考虑multi-direction(图像是因为有不同的像素尺寸)。
在3维的点云目标检测转化为BEV的目标检测任务之后,其实anchor,也就是起初设定的那些框只需要考虑在俯视图视角下目标的朝向即可,但有些目标,比如行人,俯视图下长宽比接近1:1,这种类别只需设定1个anchor即可,不需要多角度,同traffic coin交通锥桶,而卡车就需要2个anchor。但并非多个anchor效果更好,实验表明,结果差不多但耗时计算更多。
2.3.3 Multi-anchor&multi-head
另一个改进:

个头较大类别(小轿车、卡车、公交车、工程车)和个头较小类别(行人、自行车、摩托车、交通锥桶、路障)。
神经网络的输出叫做Head,包含:类别概率得分,框本身参数回归值boundingbox(中心点的xy坐标,框的长宽高,以及在xy平面上与x轴正方向的夹角)以及车头朝向(朝前还是朝后)。
随着卷积层的深入,每一层的特征会更加抽象,会包含越来越global的特征,SmallHead利用两个卷积块,LargeHead利用3个卷积块(尺寸较大,需要更为global的特征,也包括需要进行维度调整)。
好处:从local到global的信息都有,包含更为丰富的特征和语义信息,使得最终检测的大小长宽高朝向都更为精确。
三 、PointPillars模型的部署和优化
3.1 PointPillars模型的部署

均为现成API。
3.2 实时inference的加速优化

6个步骤:
1)点云预处理;
2)去除超过预先设定点云范围;
3)PFE;
4)pillar特征按照原先pillar在xy平面上的位置映射回去;
5)RPN输出障碍物;
6)候选框筛选部分输出(或设定概率分数值阈值,小于该值的不予输出)。
Cuda:英伟达出的并行加速语言,
ONNX-TensorRT
PFE用两个部分:第一层是个转换点(radius)过程,不需要训练,对比会节省掉近乎一般时间。
补充:
高精地图






采集车(激光雷达+摄像头,一定时间进行扫描):单张图片和单帧点云拼接为全局3D世界,再转化为俯视图识别车道线等;元素识别;


道路上某个时刻几十米范围内的单帧数据;拼接后得到完整3D世界;点云正上方得到俯视图。

左边动态物体先略掉,再进行识别;文章来源:https://www.toymoban.com/news/detail-625443.html
 文章来源地址https://www.toymoban.com/news/detail-625443.html
文章来源地址https://www.toymoban.com/news/detail-625443.html
到了这里,关于Apollo官方课程算法解读笔记——激光雷达感知模块、基于PointPillars的激光雷达点云检测算法、PointPillars模型的部署和优化模型的部署和优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!