当 OpenAI 于 2022 年 11 月发布 ChatGPT 时,引发了人们对人工智能和机器学习的新一波兴趣。 尽管必要的技术创新已经出现了近十年,而且基本原理的历史甚至更早,但这种巨大的转变引发了各种发展的“寒武纪大爆炸”,特别是在大型语言模型和生成 transfors 领域。 一些怀疑论者认为,这些模型是 “随机鹦鹉”,只能生成他们所接受训练的内容的排列。 有些人认为这些模型是 “黑匣子”,超出了人类理解范围,甚至可能是“黑魔法”,其工作原理完全深奥。
我对在语义搜索背景下使用机器学习模型的可能性感到特别兴奋。 Elasticsearch 是一家基于 Apache Lucene 的高级搜索和分析引擎。 充分了解倒排索引、评分算法、语言分析的特殊性等所有复杂性,我偶然发现的一些例子看起来几乎就像……是的,“黑魔法”。
在我们深入研究 Python 代码之前,我想回顾一下历史。 正如我发现的,机器学习或人工智能主题的困难之一是大量高度具体的术语,并且缺乏关于技术如何工作的直观心理模型。 例如,如果我通过说它们是 “密集向量(dense vectors)” 来解释上一段中的术语 “嵌入(embeddings)”,那就无济于事了 —— 不仅你的眼睛会变得呆滞,而且我还必须解释两个术语,而不是解释其中的一个。
词汇和语义搜索(lexical and semantic search)
事实上,用数字表示语言元素是传统全文检索的基础。 现代倒排索引与传统索引(或书后索引)之间的主要区别在于,倒排索引存储的信息不仅仅是术语的出现。 它还跟踪它们在文档中的位置和出现的频率。 这已经允许某些算术运算,例如短语搜索(phrase search,搜索以特定顺序出现的术语)和邻近搜索(查找出现在彼此一定数量的位置内的术语)。
使用这些数字,特别是文档中术语出现的频率,以及整个文档集合中术语的总体频率,是对搜索结果进行评分的传统方法 TF-IDF(术语频率 vs 逆文档频率)公式和更复杂的公式,如 BM-25。 简而言之,某个术语在特定文档中出现的频率越高,该文档在相关文档列表中的排名就越高。 相反,特定术语在整个集合中出现的频率越高,该文档在列表中的排名就越少。 将有关术语的统计信息存储在集合中可以实现比简单查找(例如 “此特定文档包含此特定单词”)更复杂的操作。
传统的 “词汇(lexical)” 搜索和 “语义(semantic)” 搜索之间的根本区别在于,词汇搜索只能找到包含查询中存在的确切术语的文档。 我们所说的 “术语” 是指搜索引擎识别为具有相同含义的单词的变体。 当然,像 Elasticsearch 这样的现代搜索引擎拥有复杂的工具,可以将 “words” 转换为 “terms”,从简单的工具(如删除大写)到更高级的工具,如词干提取(删除后缀、walking ⇒ walk)、词形还原(将不同的屈折形式减少为基本的,worst ⇒ bad),或同义词。 这些有助于扩大查询范围(并找到更多相关文档)。
然而,即使进行了这些转换,如果文档中缺少这些特定术语,你也无法使用 “a domestic animal which catches mice” 之类的查询来搜索 “cat”。 另一方面,大型语言模型非常有能力为这样的 “间接” 查询检索文档。 这并不是因为它以天真的拟人化的方式 “理解” 了那个特定的短语。 这是因为它理解与不同想法相对应的不同符号系统:人类语言。 在这个系统中,占据最接近符号 “a domestic animal which catches mice” 的位置的概念,是的,是猫的概念。
因此,在语义搜索中,搜索结果的相关性是由系统内的语义接近度决定的,而不仅仅是关键字匹配,无论多么复杂。 顾名思义,“词汇搜索” 的行为非常类似于在字典(词典)中搜索单词定义:如果你知道要搜索的单词,那么它会非常有效。 否则,你不妨读整本字典。
使用 Elasticsearch 进行语义搜索
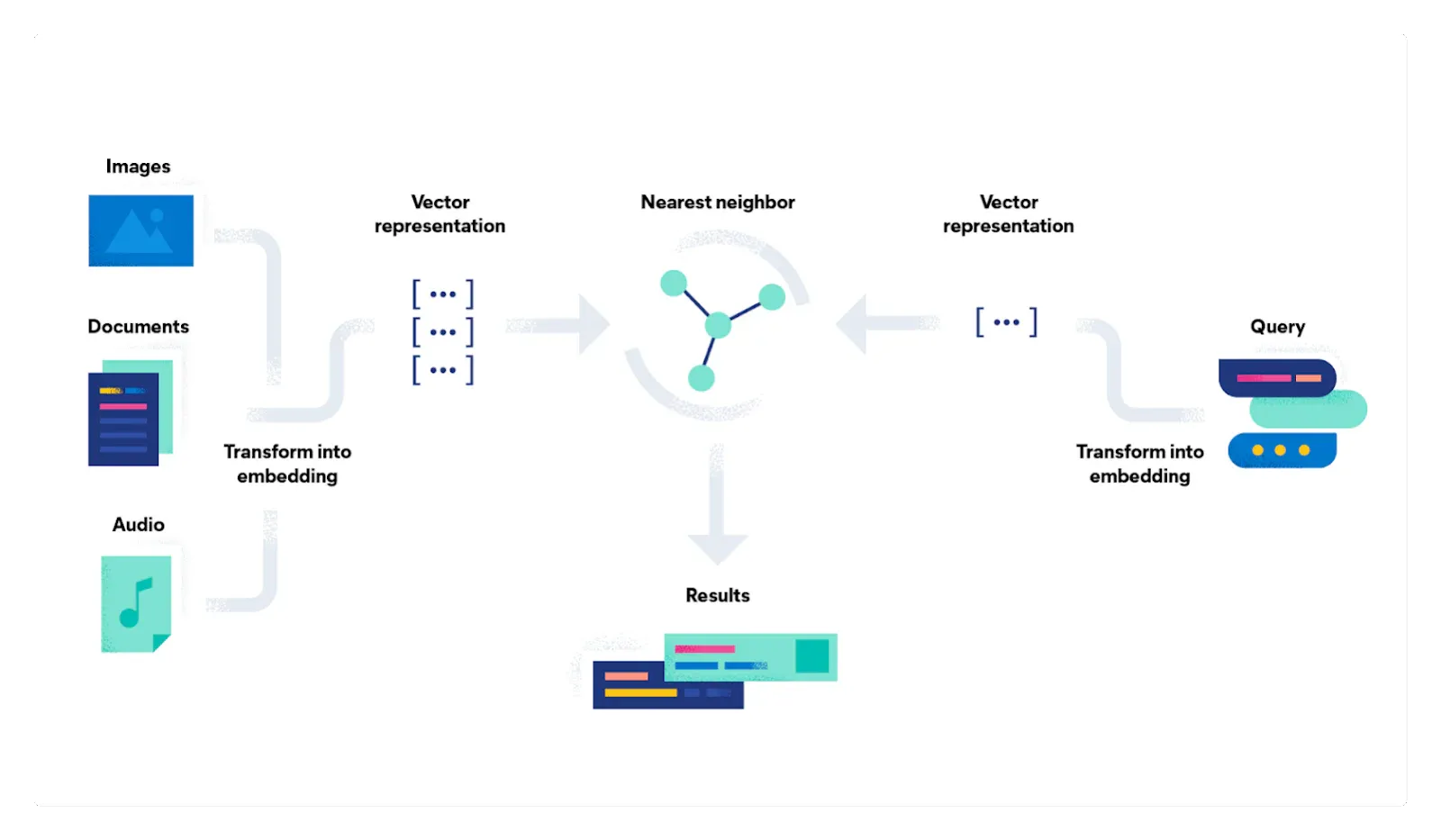
有趣的是,语义搜索的支持基础设施多年来一直是 Elasticsearch 的一部分 —— dense_vector 映射字段在 2019 年 4 月发布的 7.0 版本中引入。几个月后发布的 7.3 版本增加了对指定维度的支持 type 并将预定义函数引入到 script_score 查询中,从而能够计算文档的相似度分数。 2022 年 2 月发布的 8.0 版本进一步改进了dense_vector 实现,并添加了 “Approximate Nearest Neighbor - 近似最近邻” 搜索端点,有效地将关键组件捆绑在一起以全面实现语义搜索,包括在集群内运行第三方模型的能力。 在最新版本 8.8 中,Elastic 不仅专注于改进其 AI 功能的通信以响应当前的兴趣浪潮,而且还添加了一些增强功能,例如在密集向量字段中增加更高的维度,从而允许存储大型嵌入像 OpenAI 开发的语言模型一样,并提供了一个自定义的内置模型,即 Elastic Learned Sparse Encoder。
在本博客的其余部分中,我想演示如何使用 Sentence Transformers中的模型,使用 James Briggs 文章中的查询。 希望你会看到 Elasticsearch 是一个非常强大的向量数据库,具有用于执行相似性搜索的高效且方便的 API。
但首先,我想谈谈 “向量” 这个术语。 (你可能已经注意到,我在开头段落中使用了三次 “dense_vector” 一词。)如果你像我一样没有数学背景,那么向量这个词和概念一开始可能会让人感到害怕。 当通常的解释是向量是 “具有大小和方向的对象” 时,这并没有帮助,因为很难在人类语言的背景下为这样的对象提出合理的心理模型。 一个更有用的模型可能是将 “向量空间” 中的向量视为坐标。
由于语义是由符号在共享符号系统中的 “位置” 给出的,所以我们可以给出这个位置的 “坐标”。 此外,我们可以使用这些坐标的数字表示,从而开启算术运算的可能性。 这种数字表示通常称为嵌入。 如果我们抛开数学理论,物理表示就是一个十进制数列表:[0.01, 0.05, -0.04, 0.06, -0.1, ...]。 列表的长度称为维度,每个维度代表含义的特定特征。
让我们使用由达姆施塔特技术大学 Ubiquitous Knowledge Processing Lab 提供的 Sentence Transformers 框架中的免费、开源、预训练模型来仔细研究其机制。
文本嵌入 - Text embeddings
为了更好地理解嵌入是语义搜索(以及其他自然语言处理任务)的基础,让我们从 Hugging Face 加载模型并使用它来生成几个单词的嵌入。 但首先,让我们安装必要的库并设置我们的环境。
%pip -q install \
python-dotenv ipywidgets tqdm humanize \
pandas numpy matplotlib altair \
datasets sentence-transformers \
elasticsearch
%load_ext dotenv
%dotenv
from tqdm.notebook import tqdm as notebook_tqdm让我们下载并初始化全 MiniLM-L6-v2 模型。
from sentence_transformers import SentenceTransformer
MODEL_ID="all-MiniLM-L6-v2"
model = SentenceTransformer(MODEL_ID)
print("Model dimensions:", model.get_sentence_embedding_dimension())
正如我们所看到的,该模型有 384 个维度。 这是模型向量空间的 “大小”。 它并不是特别大 —— 许多当前模型的嵌入有数千个维度,但对于我们的目的来说已经足够了。 让我们编码,即。 为单词 “cat” 创建嵌入:
embeddings_for_cat = model.encode("cat")
print(list(embeddings_for_cat)[:5] + ["..."]) 请注意,输出被截断为前 5 个值,以免一长串数字淹没显示。 (另请注意,将此模型用于单个单词只是说明性的,因为它针对句子进行了优化。对于单词嵌入,使用 Word2Vec 或 GloVe 等模型更为典型。)
请注意,输出被截断为前 5 个值,以免一长串数字淹没显示。 (另请注意,将此模型用于单个单词只是说明性的,因为它针对句子进行了优化。对于单词嵌入,使用 Word2Vec 或 GloVe 等模型更为典型。)
让我们编码一个不同的单词 “dog”:
embeddings_for_dog = model.encode("dog")
print(list(embeddings_for_dog)[:5] + ["..."])
输出说明了为此类文本编码提出合理的心理模型是多么具有挑战性:作为人类,我们很好地掌握了符号 “cat” 或 dog” 与其代表的家畜之间的关系。很难很好地理解这样的数字表示。
然而,如前所述,数字表示具有明显的优势 —— 我们可以对值进行数学运算。 在这种情况下,我们可以尝试在散点图中将它们可视化。 让我们将列表包装在 Pandas dataframe 中,这样我们就可以在 Jupyter 笔记本中显示时利用其丰富的格式,并在后续步骤中利用其数据操作功能。
import pandas as pd
df = pd.DataFrame(embeddings_for_cat, columns=["embedding"])
df
我们可以使用内置的绘图功能来显示简单的图表:
df.reset_index().plot.scatter(x="index", y="embedding");
该图表只为我们提供了非常抽象的数据 “图片”; 基本上,值的粗略分布(在 -0.15 到 0.23 的范围内)。
就其本身而言,这些数字毫无意义。 当我们将语言理论视为 “不同符号的系统” 时,这实际上是预料之中的。 任何一个词单独存在都没有意义; 它的意义来自于与系统中其他词的关系。 那么,如果我们尝试想象 “cat” 和 “dog” 这两个词呢?
让我们创建一个新的 dataframe,使用 “cat” 和 “dog” 作为索引并将嵌入压缩到单个列。
df = pd.DataFrame(
[
[embeddings_for_cat],
[embeddings_for_dog],
],
index=["cat", "dog"], columns=["embeddings"]
)
df
为了绘制数据,我们需要进行一些转换:
# Add a new column to store the original index values (0-383) for each embedding
df["position"] = [list(range(len(df.embeddings[i]))) for i in df.index]
# Convert the `embeddings` and `position` columns from "wide" to "long" format
df_exploded = df.explode(["embeddings", "position"])
# Convert the index into a regular column
df_exploded = df_exploded.reset_index()
# Rename columns for more clarity
df_exploded = df_exploded.rename(columns={"index": "animal", "embeddings": "embedding"})
# Add a new column with numerical values mapped from the `animal` column values
df_exploded["color"] = df_exploded["animal"].map({"cat": 1, "dog": 2})
df_exploded
现在我们可以绘制转换后的数据:
(df_exploded
.plot
.scatter(x="position", y="embedding", c="color", colormap="tab10")
.collections[0].colorbar.remove())
像这样的简单可视化似乎不会有太大帮助。 然而,它强调了多维向量空间的一个基本困难。 作为人类,我们非常有能力在 2D 或 3D 空间中可视化物体。 更多维度根本不是我们能够有效想象的东西,更不用说 “绘制” 了。
我们可以使用的一个技巧是减少维度,在本例中从 384 维减少到 2 维。(再次强调:我们能够做到这一点是因为我们正在处理语言的数字表示。)有很多算法可以用于 这样做 - 我们将使用主成分分析 (principal component analysis - PCA),因为它在 scikit-learn 包中很容易获得,并且适用于小型数据集。 (有关使用 t-SNE 和 UMAP 算法的示例,请参阅 Plotly 包文档中的一篇优秀文章。)
import numpy as np
from sklearn.decomposition import PCA
# Drop the `position` column as it's no longer needed
df.drop(columns=["position"], inplace=True, errors="ignore")
# Convert embeddings to a 2D array and display their shape
print("Embeddings shape:", np.stack(df["embeddings"]).shape)
# Initialize the PCA reducer to convert embeddings into arrays of length of 2
reducer = PCA(n_components=2)
# Reduce the embeddings, store them in a new dataframe column and display their shape
df["reduced"] = reducer.fit_transform(np.stack(df["embeddings"])).tolist()
print("Reduced embeddings shape:", np.stack(df["reduced"]).shape)
df
正如我们所看到的,减少的嵌入只有两个维度,因此我们可以使用 Vega-Altair 包将它们绘制在笛卡尔平面上作为 x 和 y 坐标。 让我们创建一个函数,以便稍后重用代码。
import altair as alt
def scatterplot(
data: pd.DataFrame,
tooltips=False,
labels=False,
width=800,
height=200,
) -> alt.Chart:
base_chart = (
alt.Chart(data)
.encode(
alt.X("x", scale=alt.Scale(zero=False)),
alt.Y("y", scale=alt.Scale(zero=False)),
)
.properties(width=width, height=height)
)
if tooltips:
base_chart = base_chart.encode(alt.Tooltip(["text"]))
circles = base_chart.mark_circle(
size=200, color="crimson", stroke="white", strokeWidth=1
)
if labels:
labels = base_chart.mark_text(
fontSize=13,
align="left",
baseline="bottom",
dx=5,
).encode(text="text")
chart = circles + labels
else:
chart = circles
return chartsource = pd.DataFrame(
{
"text": df.index,
"x": df["reduced"].apply(lambda x: x[0]).to_list(),
"y": df["reduced"].apply(lambda x: x[1]).to_list(),
}
)
scatterplot(source, labels=True)
好的。 该图表相当平庸 —— 只有两个圆圈,随机放置在画布上。 我们可能期望这些标记会彼此靠近地显示;但事实并非如此。 毕竟,猫和狗有很多共同的特征。 然而,在语言作为一个系统的前提下,我们有限的 “系统” 只包含两个词:“cat” 和 “dog”。
作为人类,我们可能会认为这些标志密切相关:它们都代表有四足的毛茸茸的动物,通常作为宠物饲养,都是哺乳动物属的食肉动物,等等。 但这种直觉来自于我们语言的一个非常大的系统,其中有许多其他概念占据着不同的位置。 引用索绪尔的话,“这些概念纯粹是差异性的,不是由它们的积极内容来定义,而是由它们与系统其他术语的关系来消极定义”。
然后,让我们尝试向集合中添加更多单词,看看图片是否会以有意义的方式发生变化。
words = ["cat", "dog", "table", "chair", "pizza", "pasta", "asymptomatic"]
# Create a new dataframe
df = pd.DataFrame(
[[model.encode(word)] for word in words],
columns=["embeddings"],
index=words,
)
# Perform dimensionality reduction
df["reduced"] = reducer.fit_transform(np.stack(df["embeddings"])).tolist()
df 
让我们再次显示散点图。
source = pd.DataFrame(
{
"text": df.index,
"x": df["reduced"].apply(lambda x: x[0]).to_list(),
"y": df["reduced"].apply(lambda x: x[1]).to_list(),
}
)
scatterplot(source, labels=True) 
好多了! 我们可以清楚地看到相关词的三个 “集群”,dog ⇔ cat,pizza ⇔ pasta,chair ⇔ table。 我们还可以看到,除了这三个集群之外,“asymptomatic”一词是单独存在的。
这是人工智能的 “黑魔法” 吗? 并不真的是。 全 MiniLM-L6-v2 模型已经在 Reddit、Stack Exchange、维基百科、Quora 和其他来源的大量人类编写的文本上进行了训练。 因此,它确实具有这些词的含义,几乎字面上 “嵌入” 在它生成的 384 维向量中。
装载数据集
通过更好、更实际地理解文本嵌入的工作原理和原理,我们可以回到本博客的最初动机:使用 Elasticsearch 而不是 Pinecone,重新创建 James Briggs 文章中的语义搜索示例。
我们将使用 Hugging Face 的 datasets 包来加载 Quora 数据。 它是一个非常复杂的数据 “包装器”,它提供了方便的功能,例如下载文件的内置缓存和高效的处理功能,我们将使用这些功能来操作数据。
Hugging Face 数据集主要面向为模型训练提供数据,因此它们被分为 train、test、validation 等 split。 我们的特定数据集只有 train split 部分。 让我们加载它并显示有关数据集的一些元数据。
import humanize
import datasets
dataset = datasets.load_dataset("quora", split="train")
print("Description:", dataset.info.description, "\n")
print("Homepage:", dataset.info.homepage)
print("Downloaded size:", humanize.naturalsize(dataset.info.download_size))
print("Number of examples:", humanize.intcomma(dataset.info.splits["train"].num_examples))
print("Features:", dataset.info.features)
正如我们所看到的,该数据集包含超过 400,000 个 “question pairs”。 我们来看看前五条记录。
dataset[:5]
该数据集的主要重点是为重复检测提供可靠的数据:
我们的第一个数据集与识别重复问题的问题有关。
Quora 的一个重要产品原则是,每个逻辑上不同的问题都应该有一个问题页面。 举一个简单的例子,查询“美国人口最多的州是哪个?” 和“美国哪个州人口最多?” 不应该单独存在于 Quora 上,因为两者背后的意图是相同的。 (...)
我们今天发布的数据集将使任何人都有机会根据实际的 Quora 数据来训练和测试语义等价模型。 (...)
— Kornél Csernai,第一个 Quora 数据集发布:Question Pairs
因此,数据集包含问题对,这些问题对被标记为重复或不重复。 让我们使用数据集包的实用程序来选择和过滤数据,显示一些重复问题的示例。
(dataset
.select(range(1000))
.filter(lambda record: record["is_duplicate"])[:3])
有点矛盾的是,数据集不包含 “美国人口最多的州是哪个?” 的问题。 文章中提到。
dataset.filter(lambda record: "What is the most populous state in the USA?" in record["questions"]["text"])[:]
让我们从清理和转换数据集开始,这样我们就可以将各个问题作为单独的文档加载到 Elasticsearch 中。
首先,我们将删除 is_duplicate 列并 “展平” questions 属性,即。 将其展开为单独的列。
print("Original dataset:", dataset, "\n")
# Remove the `is_duplicate` column
dataset = dataset.remove_columns("is_duplicate")
# Flatten the dataset
dataset = dataset.flatten()
print("Transformed dataset:", dataset, "\n")
dataset[:5]
我们对结构进行了一些改进,但问题文本字段中仍然有两个问题。 为了有效地索引问题,最好将每个问题存储为单独的行。 我们将使用包提供的强大的 map() 功能,扩展 questions.id 和 questions.text 列。
# Expand the values from the lists into separate lists
def expand_values(batch):
ids = []
texts = []
for id_list, text_list in zip(batch["questions.id"], batch["questions.text"]):
ids.extend(id_list)
texts.extend(text_list)
return {"id": ids, "text": texts}
# Run the "expand_values" function for batches of rows in the dataset
dataset = dataset.map(
expand_values,
batched=True,
remove_columns=dataset.column_names,
desc="Expand Questions",
)
print("Transformed dataset:", dataset, "\n")
dataset[:5]
数据集包含两倍的行数,因为每个问题现在都存储为单独的行。
下一步是删除重复的问题。 我们没有使用 is_duplicate 列进行重复数据删除,因为我们仍然希望对所有问题建立索引,即使它们在语义上相同(“How can I be a good geologist?” 与 “What should I do to be a great geologist?”)。 我们只是想删除文本完全相同的问题。 我们将再次使用 map() 函数。
# Create a Python set to keep track of processed questions
seen = set()
# Remove rows with exactly the same text value
def remove_duplicate_rows(batch):
global seen
output = {"id": [], "text": []}
for id, text in zip(batch["id"], batch["text"]):
if text not in seen:
seen.add(text)
output["id"].append(id)
output["text"].append(text)
return output
# Run the "remove_duplicate_rows" function for batches of rows in the dataset
dataset = dataset.map(
remove_duplicate_rows,
batched=True,
batch_size=1000,
remove_columns=dataset.column_names,
desc="Remove Duplicates",
)
dataset
该数据集现在包含 537,362 个独特的问题。
我们将使用之前用 “cat” 和 “dog” 演示的相同方法为这些问题生成文本嵌入。 稍后,我们会将它们索引到 Elasticsearch 中,以便使用称为“近似最近邻居(appoximate nearest neigbors)” 的专门查询类型来查找语义相似的文档。
让我们再次使用 map() 方法处理数据集。
import time
%env TOKENIZERS_PARALLELISM=true
# Compute embeddings for batches of question text
def compute_embeddings(batch):
return { "embeddings": model.encode(sentences=batch["text"]) }
try:
start = time.perf_counter()
dataset = dataset.map(
compute_embeddings,
batched=True,
batch_size=1000,
desc="Compute Embeddings",
)
except KeyboardInterrupt:
print("Creating text embeddings interrupted by the user...")
print(
"Dataset with embeddings:", dataset,
f"(duration: {humanize.precisedelta(time.perf_counter() - start)})",
"\n")
# Print a sample of the embeddings for first question
print(list(dataset[:1]["embeddings"][0][:5]) + ["..."]) 
正如你所看到的,这是一个资源密集型操作,在配备 M1 Max 芯片的 Apple 笔记本上可能需要 16 多分钟。 要保留带有嵌入的完整数据集,请使用 save_to_disk() 方法。
索引数据到 Elasticsearch
在下一步中,我们将创建一个具有特定映射的 Elasticsearch 索引,用于将嵌入存储在密集向量字段类型中,并将问题文本存储在常规文本字段中,并使用英语分析器进行处理。
如果你想尝试自己运行这些示例,你需要一个 Elasticsearch 集群。 使用此存储库中提供的 Docker Compose 文件在本地启动集群。你可以参考如下的两篇文章来创建自己的 Elasticsearch 及 Kibana:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择使用 Elastic Stack 8.x 的安装手册来进行安装。在默认的情况下,Elasticsearch 的安装是带有 https 的安全访问。
import os
from elasticsearch import Elasticsearch
INDEX_NAME = "quora-with-embeddings-v1"
# es = Elasticsearch(hosts=os.getenv("ELASTICSEARCH_URL"), request_timeout=300)
CERT_FINGERPRINT="bd0a26dc646ef1cb3cb5e132e77d6113e1b46d56ee390dd3c6f0b2d2b16962c4"
es = Elasticsearch( ['https://localhost:9200'],
basic_auth = ('elastic', 'h6y=vgnen2vkbm6D+z6-'),
ssl_assert_fingerprint = CERT_FINGERPRINT,
http_compress = True )
if not es.indices.exists(index=INDEX_NAME):
es.indices.create(
index=INDEX_NAME,
mappings={
"properties": {
"text": {
"type": "text",
"analyzer": "english",
},
"embeddings": {
"type": "dense_vector",
"dims": model.get_sentence_embedding_dimension(),
"index": "true",
"similarity": "cosine",
},
}
},
)
print(f"Created Elasticsearch index at {os.getenv('ELASTICSEARCH_URL')}/{INDEX_NAME}?pretty")
else:
print(f"Skipping index creation, index already exists")更多关于如何连接到 Elasticsearch 集群的知识,请参阅文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。你也可以参考文章 “Elasticsearch:如何将整个 Elasticsearch 索引导出到文件 - Python 8.x”。

我们可以在在 Kibana 中进行查看:

现在我们准备好对数据建立索引了。 我们将使用 Elasticsearch 客户端的 parallel_bulk() 帮助器,因为它是加载数据的最方便的方式:它通过在多个线程中运行客户端来优化进程,并且它接受 Python 迭代器(iterable)或生成器(generator),从而提供 用于索引大型数据集的高级接口。 我们将使用数据集的 to_iterable_dataset() 方法将其转换为生成器。 这种转换对于大型数据集尤其有益,因为它允许更节省内存的处理。
import os
import time
from elasticsearch.helpers import parallel_bulk
if es.count(index=INDEX_NAME)["count"] >= len(dataset):
print("Skipping indexing, data already indexed.")
else:
progress = notebook_tqdm(unit="docs", total=len(dataset))
indexed = 0
start = time.perf_counter()
# Remove the "id" column and convert the dataset to generator
iterable_dataset = dataset.remove_columns(["id"]).to_iterable_dataset()
try:
print(f"Indexing dataset to [{INDEX_NAME}]...")
for ok, result in parallel_bulk(
es,
iterable_dataset,
index=INDEX_NAME,
thread_count=os.cpu_count()//2,
):
indexed += 1
progress.update(1)
print(f"Indexed [{humanize.intcomma(indexed)}] documents in {humanize.precisedelta(time.perf_counter() - start)}")
except KeyboardInterrupt:
print(f"Indexing interrupted by the user, indexed [{humanize.intcomma(indexed)}] documents in {humanize.precisedelta(time.perf_counter() - start)}")
好的! 看起来我们的文档已成功建立索引。 让我们使用 Cat Indices API 检查索引,显示文档数量和磁盘上索引的大小。
res = es.cat.indices(index=INDEX_NAME, format="json")
print(
f"Index [{INDEX_NAME}] contains [{humanize.intcomma(res.body[0]['docs.count'])}] documents",
f"and uses [{res.body[0]['pri.store.size'].upper()}] of disk space"
)
搜索数据
至此,我们终于可以使用 Elasticsearch 来搜索数据了。
我们将定义实用函数来包装搜索请求并以格式化的 Pandas 数据帧返回结果。 我们将使用匹配查询进行词法搜索,使用 knn 选项进行语义搜索。
import pandas as pd
# Lexical search with the `match` query
def search_keywords(query, size=10):
res = es.search(
index=INDEX_NAME,
query={"match": {"text": query}},
size=size,
source_includes=["text", "embeddings"],
)
return pd.DataFrame(
[
{"text": hit["_source"]["text"], "embeddings": hit["_source"]["embeddings"], "score": hit["_score"]}
for hit in res["hits"]["hits"]
]
)
# Semantic search with the `knn` option
# https://www.elastic.co/guide/en/elasticsearch/reference/current/search-search.html#search-api-knn
def search_embeddings(query, size=10):
res = es.search(
index=INDEX_NAME,
knn={
"field": "embeddings",
"query_vector": model.encode(query, normalize_embeddings=True),
"k": size,
"num_candidates": 1000,
},
size=size,
source_includes=["text", "embeddings"],
)
return pd.DataFrame(
[
{"text": hit["_source"]["text"], "embeddings": hit["_source"]["embeddings"], "score": hit["_score"]}
for hit in res["hits"]["hits"]
]
)
# Returns the dataframe without the "embeddings" column and with a formatted "score" column
def styled(df):
return (df[["score", "text"]]
.style
.set_table_styles([dict(selector="th,td", props=[("text-align", "left")])])
.hide(axis="index")
.format({"score": "{:.3f}"})
.background_gradient(subset=["score"], cmap="Greys"))
# Add the utility function to the dataframe class
pd.DataFrame.styled = styled让我们使用原始文章中的查询 “Which city has the highest population in the world?” 来执行词法搜索。
search_keywords("Which city has the highest population in the world?")
我们可以立即观察到大多数结果与我们的查询不太相关。 除了 “Which is the most populated city in the world.?” 等项目之外。 和 “What are the most populated cities in the world?”,大多数结果与 “most populated city” 的概念几乎没有关系。 我们还可以观察默认评分算法如何增强问题开头的短语 “Which city (…)”,尽管文本的其余部分不相关(历史建筑的数量、生活水平等)。
让我们使用相同的查询执行语义搜索,看看是否得到不同的结果。
search_embeddings("Which city has the highest population in the world?")
很明显,这些结果与我们的查询概念更加相关。 词汇搜索中最相关的结果返回在顶部,接下来的几个结果几乎与 “most populated city” 概念同义,例如。 “largest city” 或 “biggest city”。 另请注意,“Which is the largest city in the world by area?” 结果列在与国家(而非城市)相关的结果之后。 这是非常令人期待的:我们的查询是关于人口规模,而不是面积。
让我们尝试一些意想不到的事情。 让我们重新措辞该查询,使其不包含匹配文档中的任何重要关键字,省略限定词 “which”,将 “city” 替换为“urban location”,将 “highest population” 替换为 “excessive concentration of homo sapiens” ,诚然是一个非常不自然的短语。 (此重新表述的所有功劳均归于詹姆斯·布里格斯(James Briggs),请参阅原始文章的特定版本。)
search_embeddings("Urban locations with the highest concentration of homo sapiens")
也许令人惊讶的是,我们得到的结果大多与我们的查询相关,尤其是在列表顶部,即使我们的查询是故意构造的,查询术语和文档术语之间没有直接重叠。 这有力地展示了语义搜索的最强点。
让我们尝试使用词法搜索执行相同的查询。
search_keywords("Urban locations with the highest concentration of homo sapiens")
我们没有得到与我们的查询相关的结果。 根据我们对词汇搜索和语义搜索之间差异的理解,这应该不足为奇。 事实上,这种效应有一个技术描述,词汇不匹配,即查询术语与文档术语相差太大。 即使前面提到的词干提取或词形还原等术语操作也无法防止这种不匹配。 传统上,解决方案是向搜索引擎提供同义词列表。 然而,这很快就会变得复杂,因为最终我们需要提供完整的同义词库。 (此外,由于评分算法通常的工作方式,在计算每个结果的分数时,它无法区分单词及其同义词。)
让我们回到原来的查询,使用稍微不同的措辞,看看我们是否可以可视化嵌入和结果,类似于我们使用 “cat” 和 “dog” 等单词进行的演示。
df = search_embeddings("What is the most populated city in the world?")
df
我们需要使用 explode() 数据帧方法再次将数据帧从 “宽” 格式转换为 “长” 格式。
# Store the original index values (0-9) as position
df["position"] = [list(range(len(df.embeddings[i]))) for i in df.index]
# Convert the `embeddings` and `position` columns from "wide" to "long" format
source = df.explode(["embeddings", "position"])
# Rename the `embeddings` column to `embedding`
source = source.rename(columns={ "embeddings": "embedding"})
source
让我们使用 Vega-Altair 创建每个结果的嵌入 “热图”。
import altair as alt
alt.Chart(
source
).encode(
alt.X("position:N", title="").axis(labels=False, ticks=False),
alt.Y("text:N", title="", sort=source["score"].unique()).axis(labelLimit=300, tickWidth=0, labelFontWeight="bold"),
alt.Color("embedding:Q").scale(scheme="goldred").legend(None),
).mark_rect(
width=3
).properties(width=alt.Step(3), height=alt.Step(25))
尽管进行 “reading from tea leaves” 类型的分析存在轻微风险,但我们仍然可以辨别图表中的特定模式。 请注意前三个结果的视觉模式非常相似。 第四个结果在某种程度上打破了这种模式,也许是因为它是关于人口最多的国家而不是城市。 同样,与面积最大城市相关的两个结果形成了独特的视觉模式。文章来源:https://www.toymoban.com/news/detail-625805.html
然而,和以前一样,我们可以看到理解具有大量维度的可视化是多么具有挑战性。 让我们再次尝试降低维度,并将结果绘制在二维平面上。文章来源地址https://www.toymoban.com/news/detail-625805.html
到了这里,关于Elasticsearch:语义搜索 - Semantic Search in python的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!