背景
高并发接口,引入redis作为缓存之后,运行一段时间发现redis各个节点在高峰时段的访问量严重不均衡,有的节点访问量7000次/s,有的节点访问量500次/s
此种现象虽然暂时不影响系统使用,但是始终是个安全隐患,随着业务量逐年上涨,风险留给未来,并非一个合格码农的职业操守。必须得看看究竟是何种情况。
思考
想要优化,得现有一番思考,先得想想究竟有哪些情况会产生这种现象,才能去逐步排查,而不能盲目就去动手。
可能的原因:
- 数据倾斜:如果某些键的访问频率较高,而这些键又恰好分布在某几个节点上,就会导致节点的访问不均衡。这可能是因为数据分布不均匀,或者业务逻辑导致某些键的访问频率较高。
- 网络问题:网络延迟或带宽限制可能导致某些节点的访问速度较慢,从而使访问不均衡。
- 客户端连接问题:如果某些客户端连接到了某个特定节点,而其他节点上的客户端较少,就会导致节点的访问不均衡.
- 业务逻辑问题:是否是因为业务逻辑原因导致的频繁访问同一批数据
- 是否存在热key
验证
有了上述思考,就要开始去逐一排查可能的原因
1.数据倾斜排查:检查数据在节点之间的分布情况,通过查看Redis的CPU、内存指标,并未发现某个节点的负载明显高于其他节点
2.网络问题:通过监测网络延迟或带宽限制相关情况,并未发现有此种情况
3.客户端连接问题:检查客户端连接到Redis节点的方式,如果发现某些节点受到过多的请求压力,可以考虑采用负载均衡策略,将请求均匀分散到不同的节点上;通过相关检查,并未发现此类问题
4.业务逻辑问题:分析Redis访问相关业务代码及定时任务,并未发现有重复访问的逻辑存在
5.是否存在热key:通过运维获取高峰时段的访问日志,进行统计分析,
(1) 热key有两类:网点映射+以业务账号维度的数据
(2)redis访问不均衡的原因:不同客户下单高峰分布在一天不同时间段,高频访问在不同时间分布在不同节点上
方案
通过三种策略来确保redis各节点的访问均衡
1.本地缓存策略
将将要缓存的数据根据业务形态分为两类:
(1)网点类的常用数据直接缓存在本地
(2)对于高峰时期高频访问的数据,引入缓存组件Caffeine,设置相关的策略
设置大小为1M
EXPIRE_AFTER_WRITE_TIME(60s)
EXPIRE_AFTER_ACCESS_TIME(10s)
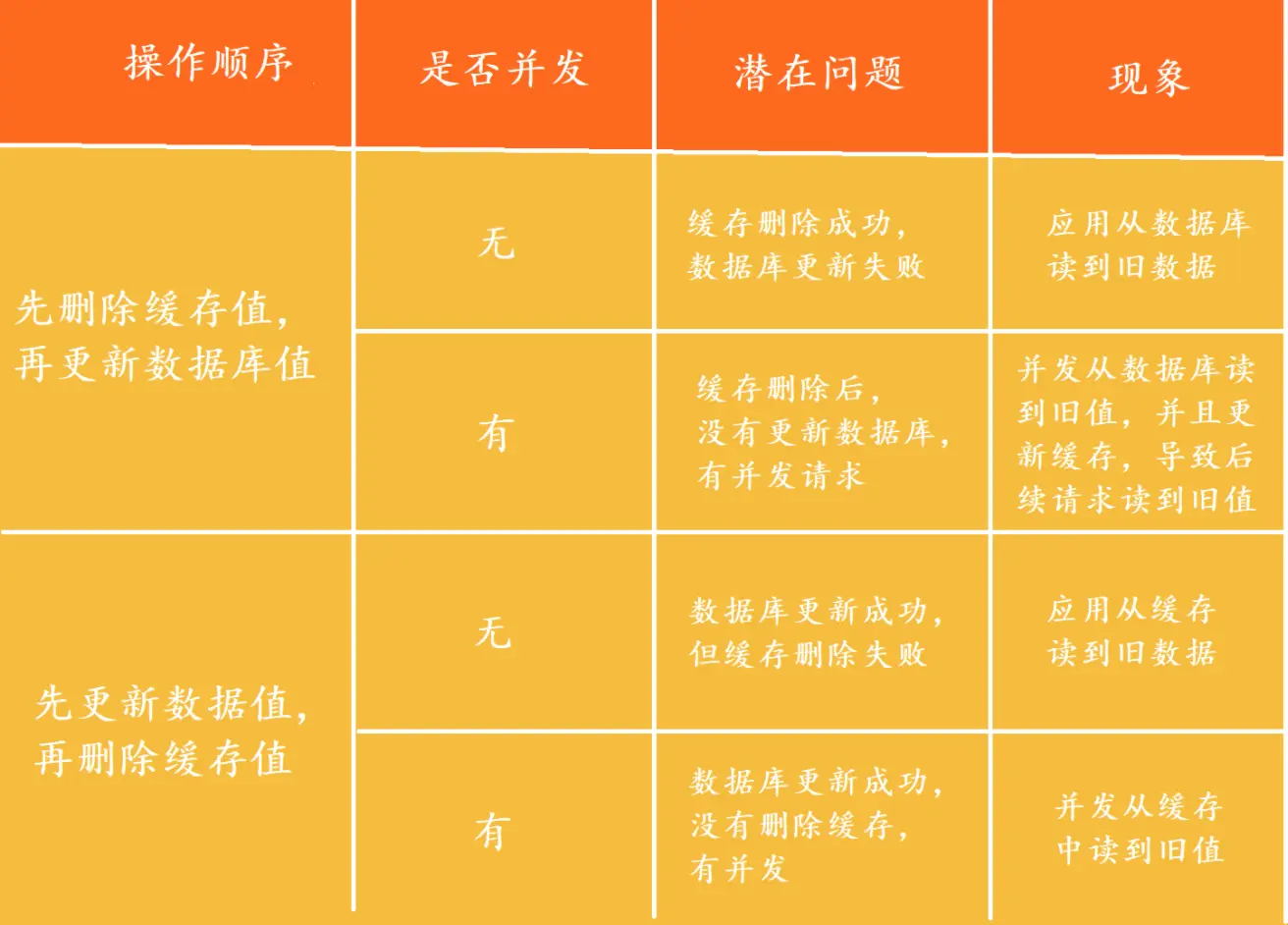
2.节点一致性策略
使用发布-订阅模式(Pub-Sub)来实现更新通知机制; 当 Redis 中的数据更新时,Redis 可以发布一个更新通知,各节点的本地缓存订阅这个通知,并根据通知更新本地缓存
3.异常解决方案
(1)异常日志记录
(2)间隔2min重试机制
(3)重试后异常告警机制
(4)数据定时同步(兜底): DB->redis、redis->本地缓存
下图为存储与访问缓存的逻辑图:

效果
经过上述方案的实施,最终实现了:
1.redis各节点的访问量在全时段实现了均衡态
2.redis的各节点的整体QPS也下降了10%
3.像双十一双十二高峰时段接口也是稳稳的
本地缓存原理及方案选取原因
本地缓存是指将数据存储在应用程序的本地内存中,以提高数据的读取速度和访问效率。本地缓存的本质是通过将常用或热点数据保存在内存中,避免了每次访问都需要从远程或磁盘存储中读取数据的开销。
本地缓存的工作原理如下:
1.数据加载:当应用程序第一次访问某个数据时,如果该数据还未被缓存,则从远程或磁盘存储中加载数据,并将其保存在本地缓存中。
2.数据访问:当应用程序再次访问同样的数据时,首先从本地缓存中查找数据。如果数据存在于缓存中,则直接返回缓存的数据,避免了从远程或磁盘存储中读取的开销。
3.缓存更新:当数据发生变化时,需要更新缓存中的数据,以保持缓存和存储中的数据一致性。可以通过手动或自动的方式更新缓存,例如定时刷新缓存、监听数据变更事件等。
本地缓存的优势包括快速访问、低延迟、减轻了远程或磁盘存储的负载等。它适用于那些访问频率较高、数据相对稳定的场景,可以大大提高应用程序的性能和响应速度。
但是需要注意的是,本地缓存也存在一些问题,如缓存过期、缓存一致性、内存管理等。开发者需要根据具体的应用场景和需求,合理配置和管理本地缓存,以充分发挥其优势同时避免潜在的问题。
传统缓存组件方案:
FIFO:按照数据最早进入缓存的顺序进行替换。即,先进入缓存的数据先被替换掉。FIFO策略简单直观,但可能导致缓存命中率较低,因为最早进入缓存的数据可能不一定是最常用的数据。
LRU:根据数据最近被访问的时间进行替换。即,最长时间未被访问的数据会被替换掉。LRU策略基于“时间局部性”原理,认为最近被访问的数据更有可能在将来被访问,因此替换最久未被访问的数据。但实现LRU策略需要维护访问数据的顺序,可能带来一定的开销。
LFU:根据数据被访问的频率进行替换。即,最不经常被访问的数据会被替换掉。LFU策略基于“访问局部性”原理,认为最常被访问的数据更有可能在将来继续被访问,因此替换最不经常被访问的数据。但实现LFU策略需要维护数据的访问频率,可能带来更大的开销。
Caffeine 一个高性能、高命中率、接近最优的本地缓存,被称为”新一代缓存“或”现代缓存之王。
脱胎于Guava Cache , 结合LRU+LFU的优势,使用一种W-TinyLFU的算法结构
从Spring5开始,Caffeine将取代Guava Cache成为Spring默认的缓存组件
Caffeine是一个基于Java的内存缓存库,与其他缓存组件相比,它具有以下几个优势:
- 高性能:Caffeine被设计成高性能的缓存库,它使用了多种优化技术来提供快速的缓存访问,包括使用本地内存和原生数据结构,避免了不必要的开销。
- 低延迟:Caffeine的设计目标之一是提供低延迟的缓存访问。它采用了基于时间戳的缓存失效策略和预先加载机制,以减少对外部资源的依赖和等待时间。
- 强大的功能:Caffeine提供了丰富的功能,包括缓存过期、缓存加载、缓存刷新、缓存移除等。它支持异步加载和自定义缓存策略,可以根据具体需求进行灵活配置。
- 内存管理:Caffeine提供了细粒度的内存管理功能,可以设置缓存的最大大小、最大条目数、过期时间等。它还支持缓存的自动回收和大小基于权重的淘汰策略,可以有效地管理内存。
- 易于使用:Caffeine提供了简单易用的API,可以方便地创建和管理缓存。它还提供了详细的文档和示例代码,以帮助开发者快速上手和集成。
Caffeine在性能、延迟、功能和内存管理等方面都具有优势,适用于对缓存性能要求较高的场景。它可以作为Java应用程序的缓存解决方案,提供快速、可靠和灵活的缓存支持。文章来源:https://www.toymoban.com/news/detail-626665.html
文章来源地址https://www.toymoban.com/news/detail-626665.html
到了这里,关于一次redis缓存不均衡优化经验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!