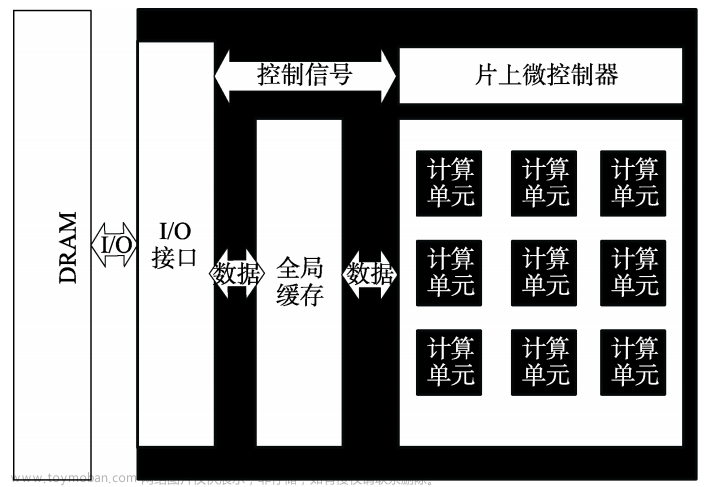
AutoFed:面向异构数据的联邦多模态自动驾驶的学习框架
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:面向异构数据的联邦学习在自动驾驶中的应用。
参考文献:Zheng T, Li A, Chen Z, et al. AutoFed: Heterogeneity-Aware Federated Multimodal Learning for Robust Autonomous Driving[J]. arXiv preprint arXiv:2302.08646, 2023.
背景介绍
自动驾驶技术正处于快速发展的阶段,目标是提供更高的安全性、更少的有害排放、更大的道路容量和更短的行程时间等广泛的好处。自动驾驶的核心是感知能力,即能够检测道路上的对象(如车辆、自行车、标志和行人等),这为路径规划和行动决策提供可解释的依据。正式来说,美国汽车工程师学会(SAE)要求3-5级自动驾驶系统能够在各种道路和天气条件下监控环境并检测对象。为达到这些目标,汽车上安装的多个传感器(如激光雷达、雷达和摄像头)可以协同工作,提供周边环境的互补和实时信息。文章来源:https://www.toymoban.com/news/detail-626689.html
为了充分利用不同传感器提供的丰富多模态信息,许多之前的工作采用了深度学习进行多模态融合和模式识别,以进行准确可靠的目标检测。 主流的目标检测方法基于两阶段法,其中首先生成感兴趣区域候选框,然后进行目标分类和边界框回归来细化候选框。尽管目标检测可以处理不同的视角,但本文专注于鸟瞰图,因为它以合理的低成本调解了不同传感模式之间的视角差异。但是,即使有这种成本降低,目标检测与基础学习任务(如分类)之间的根本区别仍导致其神经网络模型参数远远大于正常参数,使其训练难以收敛,更不用说我们还要训练多个分布式模型。文章来源地址https://www.toymoban.com/news/detail-626689.html
到了这里,关于概念解析 | AutoFed:面向异构数据的联邦多模态自动驾驶的学习框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!