导入所需的库
import numpy as np
%matplotlib widget
import matplotlib.pyplot as plt
from plt_logistic_loss import plt_logistic_cost, plt_two_logistic_loss_curves, plt_simple_example
from plt_logistic_loss import soup_bowl, plt_logistic_squared_error
from lab_utils_common import plot_data, sigmoid, dlc
plt.style.use('./deeplearning.mplstyle')
1. 平方差能否用于逻辑回归?
在前面的线性回归中,我们使用的是 squared error cost function,带有一个变量的squared error cost 为:
J
(
w
,
b
)
=
1
2
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
(1)
J(w,b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2 \tag{1}
J(w,b)=2m1i=0∑m−1(fw,b(x(i))−y(i))2(1)
其中,
f
w
,
b
(
x
(
i
)
)
=
w
x
(
i
)
+
b
(2)
f_{w,b}(x^{(i)}) = wx^{(i)} + b \tag{2}
fw,b(x(i))=wx(i)+b(2)
squared error cost有一个很好的性质,就是对cost求导会得到最小值。
soup_bowl()

这个cost函数在线性回归中表现得很好,当然,它也适用于逻辑回归。然而, f w b ( x ) f_{wb}(x) fwb(x)现在有一个非线性的部分,即sigmoid函数: f w , b ( x ( i ) ) = s i g m o i d ( w x ( i ) + b ) f_{w,b}(x^{(i)}) = sigmoid(wx^{(i)} + b ) fw,b(x(i))=sigmoid(wx(i)+b)。接下来,我们尝试使用squared error cost在以前博客的样例中,此时包括sigmod。
训练数据:
x_train = np.array([0., 1, 2, 3, 4, 5],dtype=np.longdouble)
y_train = np.array([0, 0, 0, 1, 1, 1],dtype=np.longdouble)
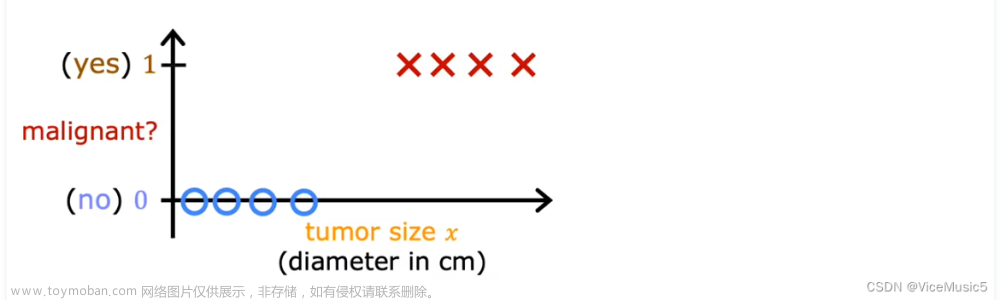
plt_simple_example(x_train, y_train)

现在,用squared error cost 绘制cost的曲面图:
J
(
w
,
b
)
=
1
2
m
∑
i
=
0
m
−
1
(
f
w
,
b
(
x
(
i
)
)
−
y
(
i
)
)
2
J(w,b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2
J(w,b)=2m1i=0∑m−1(fw,b(x(i))−y(i))2
其中,
f
w
,
b
(
x
(
i
)
)
=
s
i
g
m
o
i
d
(
w
x
(
i
)
+
b
)
f_{w,b}(x^{(i)}) = sigmoid(wx^{(i)} + b )
fw,b(x(i))=sigmoid(wx(i)+b)
plt.close('all')
plt_logistic_squared_error(x_train,y_train)
plt.show()

虽然这产生了一个非常有趣的曲面图,但上面的曲面并不像线性回归的“汤碗”那么光滑。逻辑回归需要一个更适合其非线性性质的cost函数。
2. 逻辑损失函数loss
逻辑回归使用更适合分类任务的Loss函数,其中目标是0或1而不是任何数字。
注意:Loss是单个示例与其目标值之差的度量,而Cost是训练集上损失的度量。
定义:
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)})
loss(fw,b(x(i)),y(i)) 是单个数据点的cost:
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
=
{
−
log
(
f
w
,
b
(
x
(
i
)
)
)
if
y
(
i
)
=
1
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
if
y
(
i
)
=
0
\begin{equation} loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) = \begin{cases} - \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) & \text{if $y^{(i)}=1$}\\ \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) & \text{if $y^{(i)}=0$} \end{cases} \end{equation}
loss(fw,b(x(i)),y(i))={−log(fw,b(x(i)))log(1−fw,b(x(i)))if y(i)=1if y(i)=0
f w , b ( x ( i ) ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) fw,b(x(i)) 是模型的预测值, y ( i ) y^{(i)} y(i) 是目标值.
f w , b ( x ( i ) ) = g ( w ⋅ x ( i ) + b ) f_{\mathbf{w},b}(\mathbf{x}^{(i)}) = g(\mathbf{w} \cdot\mathbf{x}^{(i)}+b) fw,b(x(i))=g(w⋅x(i)+b) ,其中 g g g 是 sigmoid 函数.
这个损失函数的定义特点在于使用了两条不同的曲线。一个用于目标为0或( y = 0 y=0 y=0)的情况,另一个用于目标为1 ( y = 1 y=1 y=1)的情况。这些曲线结合起来为损失函数提供了帮助,即当预测与目标匹配时为零,当预测与目标不同时 l o s s loss loss 值迅速增加。
plt_two_logistic_loss_curves()

综合起来,曲线类似于平方差损失的二次曲线。注意,x轴是
f
w
,
b
f_{\mathbf{w},b}
fw,b,是sigmoid的输出。sigmoid 输出严格在0到1之间。
上面的损失函数可以简写为:
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
=
(
−
y
(
i
)
log
(
f
w
,
b
(
x
(
i
)
)
)
−
(
1
−
y
(
i
)
)
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) = (-y^{(i)} \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - y^{(i)}\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right)
loss(fw,b(x(i)),y(i))=(−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))
可以将方程分成两部分:
当
y
(
i
)
=
0
y^{(i)} = 0
y(i)=0 时,左边的项被消除:
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
0
)
=
(
−
(
0
)
log
(
f
w
,
b
(
x
(
i
)
)
)
−
(
1
−
0
)
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
=
−
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
\begin{align} loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), 0) &= (-(0) \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - 0\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \\ &= -\log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \end{align}
loss(fw,b(x(i)),0)=(−(0)log(fw,b(x(i)))−(1−0)log(1−fw,b(x(i)))=−log(1−fw,b(x(i)))
当
y
(
i
)
=
1
y^{(i)} = 1
y(i)=1 时, 右边的项被消除:
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
1
)
=
(
−
(
1
)
log
(
f
w
,
b
(
x
(
i
)
)
)
−
(
1
−
1
)
log
(
1
−
f
w
,
b
(
x
(
i
)
)
)
=
−
log
(
f
w
,
b
(
x
(
i
)
)
)
\begin{align} loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), 1) &= (-(1) \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - 1\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right)\\ &= -\log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \end{align}
loss(fw,b(x(i)),1)=(−(1)log(fw,b(x(i)))−(1−1)log(1−fw,b(x(i)))=−log(fw,b(x(i)))
所以,我们可以通过这个新的逻辑损失函数得到一个包含所有样例的损失函数。
上面示例的损失与参数曲线为:
plt.close('all')
cst = plt_logistic_cost(x_train,y_train)

这条曲线非常适合梯度下降。它没有局部极小值或不连续点。需要注意的是,它不像平方差损失那样呈现“碗”状。绘制cost和log cost来说明,当cost较小时,曲线有一个斜率并继续下降。
3. 损失函数cost
导入数据集
X_train = np.array([[0.5, 1.5], [1,1], [1.5, 0.5], [3, 0.5], [2, 2], [1, 2.5]]) #(m,n)
y_train = np.array([0, 0, 0, 1, 1, 1]) #(m,)
训练数据绘图可视化:
fig,ax = plt.subplots(1,1,figsize=(4,4))
plot_data(X_train, y_train, ax)
# Set both axes to be from 0-4
ax.axis([0, 4, 0, 3.5])
ax.set_ylabel('$x_1$', fontsize=12)
ax.set_xlabel('$x_0$', fontsize=12)
plt.show()

前面介绍了一个样例的逻辑 loss 函数,这里我们根据 loss 计算包括所有样例的cost 。
对于逻辑回归,cost 函数表示为:
J
(
w
,
b
)
=
1
m
∑
i
=
0
m
−
1
[
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
]
(1)
J(\mathbf{w},b) = \frac{1}{m} \sum_{i=0}^{m-1} \left[ loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) \right] \tag{1}
J(w,b)=m1i=0∑m−1[loss(fw,b(x(i)),y(i))](1)
其中,
-
l
o
s
s
(
f
w
,
b
(
x
(
i
)
)
,
y
(
i
)
)
loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)})
loss(fw,b(x(i)),y(i)) 是一个单独数据点的cost,即:
l o s s ( f w , b ( x ( i ) ) , y ( i ) ) = − y ( i ) log ( f w , b ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w , b ( x ( i ) ) ) (2) loss(f_{\mathbf{w},b}(\mathbf{x}^{(i)}), y^{(i)}) = -y^{(i)} \log\left(f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) - \left( 1 - y^{(i)}\right) \log \left( 1 - f_{\mathbf{w},b}\left( \mathbf{x}^{(i)} \right) \right) \tag{2} loss(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))(2)
其中,m是数据集中训练样例的数量。
f
w
,
b
(
x
(
i
)
)
=
g
(
z
(
i
)
)
z
(
i
)
=
w
⋅
x
(
i
)
+
b
g
(
z
(
i
)
)
=
1
1
+
e
−
z
(
i
)
\begin{align} f_{\mathbf{w},b}(\mathbf{x^{(i)}}) &= g(z^{(i)})\tag{3} \\ z^{(i)} &= \mathbf{w} \cdot \mathbf{x}^{(i)}+ b\tag{4} \\ g(z^{(i)}) &= \frac{1}{1+e^{-z^{(i)}}}\tag{5} \end{align}
fw,b(x(i))z(i)g(z(i))=g(z(i))=w⋅x(i)+b=1+e−z(i)1(3)(4)(5)
其代码描述为:
compute_cost_logistic算法在所有的样例上循环,计算每个样例的损失并相加。
变量 X 和 y 不是标量,而是shape分别为( m , n m, n m,n) 和 ( m m m) 的矩阵。其中 n n n 是特征的数量, m m m 是训练样例的数量.
def compute_cost_logistic(X, y, w, b):
"""
Computes cost
Args:
X (ndarray (m,n)): Data, m examples with n features
y (ndarray (m,)) : target values
w (ndarray (n,)) : model parameters
b (scalar) : model parameter
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b
f_wb_i = sigmoid(z_i)
cost += -y[i]*np.log(f_wb_i) - (1-y[i])*np.log(1-f_wb_i)
cost = cost / m
return cost
测试一下:
w_tmp = np.array([1,1])
b_tmp = -3
print(compute_cost_logistic(X_train, y_train, w_tmp, b_tmp))
输出为:0.3668667864055175
附录
lab_utils_common.py 源码:文章来源:https://www.toymoban.com/news/detail-626796.html
"""
lab_utils_common
contains common routines and variable definitions
used by all the labs in this week.
by contrast, specific, large plotting routines will be in separate files
and are generally imported into the week where they are used.
those files will import this file
"""
import copy
import math
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import FancyArrowPatch
from ipywidgets import Output
np.set_printoptions(precision=2)
dlc = dict(dlblue = '#0096ff', dlorange = '#FF9300', dldarkred='#C00000', dlmagenta='#FF40FF', dlpurple='#7030A0')
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0'
dlcolors = [dlblue, dlorange, dldarkred, dlmagenta, dlpurple]
plt.style.use('./deeplearning.mplstyle')
def sigmoid(z):
"""
Compute the sigmoid of z
Parameters
----------
z : array_like
A scalar or numpy array of any size.
Returns
-------
g : array_like
sigmoid(z)
"""
z = np.clip( z, -500, 500 ) # protect against overflow
g = 1.0/(1.0+np.exp(-z))
return g
##########################################################
# Regression Routines
##########################################################
def predict_logistic(X, w, b):
""" performs prediction """
return sigmoid(X @ w + b)
def predict_linear(X, w, b):
""" performs prediction """
return X @ w + b
def compute_cost_logistic(X, y, w, b, lambda_=0, safe=False):
"""
Computes cost using logistic loss, non-matrix version
Args:
X (ndarray): Shape (m,n) matrix of examples with n features
y (ndarray): Shape (m,) target values
w (ndarray): Shape (n,) parameters for prediction
b (scalar): parameter for prediction
lambda_ : (scalar, float) Controls amount of regularization, 0 = no regularization
safe : (boolean) True-selects under/overflow safe algorithm
Returns:
cost (scalar): cost
"""
m,n = X.shape
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b #(n,)(n,) or (n,) ()
if safe: #avoids overflows
cost += -(y[i] * z_i ) + log_1pexp(z_i)
else:
f_wb_i = sigmoid(z_i) #(n,)
cost += -y[i] * np.log(f_wb_i) - (1 - y[i]) * np.log(1 - f_wb_i) # scalar
cost = cost/m
reg_cost = 0
if lambda_ != 0:
for j in range(n):
reg_cost += (w[j]**2) # scalar
reg_cost = (lambda_/(2*m))*reg_cost
return cost + reg_cost
def log_1pexp(x, maximum=20):
''' approximate log(1+exp^x)
https://stats.stackexchange.com/questions/475589/numerical-computation-of-cross-entropy-in-practice
Args:
x : (ndarray Shape (n,1) or (n,) input
out : (ndarray Shape matches x output ~= np.log(1+exp(x))
'''
out = np.zeros_like(x,dtype=float)
i = x <= maximum
ni = np.logical_not(i)
out[i] = np.log(1 + np.exp(x[i]))
out[ni] = x[ni]
return out
def compute_cost_matrix(X, y, w, b, logistic=False, lambda_=0, safe=True):
"""
Computes the cost using using matrices
Args:
X : (ndarray, Shape (m,n)) matrix of examples
y : (ndarray Shape (m,) or (m,1)) target value of each example
w : (ndarray Shape (n,) or (n,1)) Values of parameter(s) of the model
b : (scalar ) Values of parameter of the model
verbose : (Boolean) If true, print out intermediate value f_wb
Returns:
total_cost: (scalar) cost
"""
m = X.shape[0]
y = y.reshape(-1,1) # ensure 2D
w = w.reshape(-1,1) # ensure 2D
if logistic:
if safe: #safe from overflow
z = X @ w + b #(m,n)(n,1)=(m,1)
cost = -(y * z) + log_1pexp(z)
cost = np.sum(cost)/m # (scalar)
else:
f = sigmoid(X @ w + b) # (m,n)(n,1) = (m,1)
cost = (1/m)*(np.dot(-y.T, np.log(f)) - np.dot((1-y).T, np.log(1-f))) # (1,m)(m,1) = (1,1)
cost = cost[0,0] # scalar
else:
f = X @ w + b # (m,n)(n,1) = (m,1)
cost = (1/(2*m)) * np.sum((f - y)**2) # scalar
reg_cost = (lambda_/(2*m)) * np.sum(w**2) # scalar
total_cost = cost + reg_cost # scalar
return total_cost # scalar
def compute_gradient_matrix(X, y, w, b, logistic=False, lambda_=0):
"""
Computes the gradient using matrices
Args:
X : (ndarray, Shape (m,n)) matrix of examples
y : (ndarray Shape (m,) or (m,1)) target value of each example
w : (ndarray Shape (n,) or (n,1)) Values of parameters of the model
b : (scalar ) Values of parameter of the model
logistic: (boolean) linear if false, logistic if true
lambda_: (float) applies regularization if non-zero
Returns
dj_dw: (array_like Shape (n,1)) The gradient of the cost w.r.t. the parameters w
dj_db: (scalar) The gradient of the cost w.r.t. the parameter b
"""
m = X.shape[0]
y = y.reshape(-1,1) # ensure 2D
w = w.reshape(-1,1) # ensure 2D
f_wb = sigmoid( X @ w + b ) if logistic else X @ w + b # (m,n)(n,1) = (m,1)
err = f_wb - y # (m,1)
dj_dw = (1/m) * (X.T @ err) # (n,m)(m,1) = (n,1)
dj_db = (1/m) * np.sum(err) # scalar
dj_dw += (lambda_/m) * w # regularize # (n,1)
return dj_db, dj_dw # scalar, (n,1)
def gradient_descent(X, y, w_in, b_in, alpha, num_iters, logistic=False, lambda_=0, verbose=True):
"""
Performs batch gradient descent to learn theta. Updates theta by taking
num_iters gradient steps with learning rate alpha
Args:
X (ndarray): Shape (m,n) matrix of examples
y (ndarray): Shape (m,) or (m,1) target value of each example
w_in (ndarray): Shape (n,) or (n,1) Initial values of parameters of the model
b_in (scalar): Initial value of parameter of the model
logistic: (boolean) linear if false, logistic if true
lambda_: (float) applies regularization if non-zero
alpha (float): Learning rate
num_iters (int): number of iterations to run gradient descent
Returns:
w (ndarray): Shape (n,) or (n,1) Updated values of parameters; matches incoming shape
b (scalar): Updated value of parameter
"""
# An array to store cost J and w's at each iteration primarily for graphing later
J_history = []
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
w = w.reshape(-1,1) #prep for matrix operations
y = y.reshape(-1,1)
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_db,dj_dw = compute_gradient_matrix(X, y, w, b, logistic, lambda_)
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
J_history.append( compute_cost_matrix(X, y, w, b, logistic, lambda_) )
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters / 10) == 0:
if verbose: print(f"Iteration {i:4d}: Cost {J_history[-1]} ")
return w.reshape(w_in.shape), b, J_history #return final w,b and J history for graphing
def zscore_normalize_features(X):
"""
computes X, zcore normalized by column
Args:
X (ndarray): Shape (m,n) input data, m examples, n features
Returns:
X_norm (ndarray): Shape (m,n) input normalized by column
mu (ndarray): Shape (n,) mean of each feature
sigma (ndarray): Shape (n,) standard deviation of each feature
"""
# find the mean of each column/feature
mu = np.mean(X, axis=0) # mu will have shape (n,)
# find the standard deviation of each column/feature
sigma = np.std(X, axis=0) # sigma will have shape (n,)
# element-wise, subtract mu for that column from each example, divide by std for that column
X_norm = (X - mu) / sigma
return X_norm, mu, sigma
#check our work
#from sklearn.preprocessing import scale
#scale(X_orig, axis=0, with_mean=True, with_std=True, copy=True)
######################################################
# Common Plotting Routines
######################################################
def plot_data(X, y, ax, pos_label="y=1", neg_label="y=0", s=80, loc='best' ):
""" plots logistic data with two axis """
# Find Indices of Positive and Negative Examples
pos = y == 1
neg = y == 0
pos = pos.reshape(-1,) #work with 1D or 1D y vectors
neg = neg.reshape(-1,)
# Plot examples
ax.scatter(X[pos, 0], X[pos, 1], marker='x', s=s, c = 'red', label=pos_label)
ax.scatter(X[neg, 0], X[neg, 1], marker='o', s=s, label=neg_label, facecolors='none', edgecolors=dlblue, lw=3)
ax.legend(loc=loc)
ax.figure.canvas.toolbar_visible = False
ax.figure.canvas.header_visible = False
ax.figure.canvas.footer_visible = False
def plt_tumor_data(x, y, ax):
""" plots tumor data on one axis """
pos = y == 1
neg = y == 0
ax.scatter(x[pos], y[pos], marker='x', s=80, c = 'red', label="malignant")
ax.scatter(x[neg], y[neg], marker='o', s=100, label="benign", facecolors='none', edgecolors=dlblue,lw=3)
ax.set_ylim(-0.175,1.1)
ax.set_ylabel('y')
ax.set_xlabel('Tumor Size')
ax.set_title("Logistic Regression on Categorical Data")
ax.figure.canvas.toolbar_visible = False
ax.figure.canvas.header_visible = False
ax.figure.canvas.footer_visible = False
# Draws a threshold at 0.5
def draw_vthresh(ax,x):
""" draws a threshold """
ylim = ax.get_ylim()
xlim = ax.get_xlim()
ax.fill_between([xlim[0], x], [ylim[1], ylim[1]], alpha=0.2, color=dlblue)
ax.fill_between([x, xlim[1]], [ylim[1], ylim[1]], alpha=0.2, color=dldarkred)
ax.annotate("z >= 0", xy= [x,0.5], xycoords='data',
xytext=[30,5],textcoords='offset points')
d = FancyArrowPatch(
posA=(x, 0.5), posB=(x+3, 0.5), color=dldarkred,
arrowstyle='simple, head_width=5, head_length=10, tail_width=0.0',
)
ax.add_artist(d)
ax.annotate("z < 0", xy= [x,0.5], xycoords='data',
xytext=[-50,5],textcoords='offset points', ha='left')
f = FancyArrowPatch(
posA=(x, 0.5), posB=(x-3, 0.5), color=dlblue,
arrowstyle='simple, head_width=5, head_length=10, tail_width=0.0',
)
ax.add_artist(f)
plt_logistic_loss.py 源码:文章来源地址https://www.toymoban.com/news/detail-626796.html
"""----------------------------------------------------------------
logistic_loss plotting routines and support
"""
from matplotlib import cm
from lab_utils_common import sigmoid, dlblue, dlorange, np, plt, compute_cost_matrix
def compute_cost_logistic_sq_err(X, y, w, b):
"""
compute sq error cost on logicist data (for negative example only, not used in practice)
Args:
X (ndarray): Shape (m,n) matrix of examples with multiple features
w (ndarray): Shape (n) parameters for prediction
b (scalar): parameter for prediction
Returns:
cost (scalar): cost
"""
m = X.shape[0]
cost = 0.0
for i in range(m):
z_i = np.dot(X[i],w) + b
f_wb_i = sigmoid(z_i) #add sigmoid to normal sq error cost for linear regression
cost = cost + (f_wb_i - y[i])**2
cost = cost / (2 * m)
return np.squeeze(cost)
def plt_logistic_squared_error(X,y):
""" plots logistic squared error for demonstration """
wx, by = np.meshgrid(np.linspace(-6,12,50),
np.linspace(10, -20, 40))
points = np.c_[wx.ravel(), by.ravel()]
cost = np.zeros(points.shape[0])
for i in range(points.shape[0]):
w,b = points[i]
cost[i] = compute_cost_logistic_sq_err(X.reshape(-1,1), y, w, b)
cost = cost.reshape(wx.shape)
fig = plt.figure()
fig.canvas.toolbar_visible = False
fig.canvas.header_visible = False
fig.canvas.footer_visible = False
ax = fig.add_subplot(1, 1, 1, projection='3d')
ax.plot_surface(wx, by, cost, alpha=0.6,cmap=cm.jet,)
ax.set_xlabel('w', fontsize=16)
ax.set_ylabel('b', fontsize=16)
ax.set_zlabel("Cost", rotation=90, fontsize=16)
ax.set_title('"Logistic" Squared Error Cost vs (w, b)')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
def plt_logistic_cost(X,y):
""" plots logistic cost """
wx, by = np.meshgrid(np.linspace(-6,12,50),
np.linspace(0, -20, 40))
points = np.c_[wx.ravel(), by.ravel()]
cost = np.zeros(points.shape[0],dtype=np.longdouble)
for i in range(points.shape[0]):
w,b = points[i]
cost[i] = compute_cost_matrix(X.reshape(-1,1), y, w, b, logistic=True, safe=True)
cost = cost.reshape(wx.shape)
fig = plt.figure(figsize=(9,5))
fig.canvas.toolbar_visible = False
fig.canvas.header_visible = False
fig.canvas.footer_visible = False
ax = fig.add_subplot(1, 2, 1, projection='3d')
ax.plot_surface(wx, by, cost, alpha=0.6,cmap=cm.jet,)
ax.set_xlabel('w', fontsize=16)
ax.set_ylabel('b', fontsize=16)
ax.set_zlabel("Cost", rotation=90, fontsize=16)
ax.set_title('Logistic Cost vs (w, b)')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax = fig.add_subplot(1, 2, 2, projection='3d')
ax.plot_surface(wx, by, np.log(cost), alpha=0.6,cmap=cm.jet,)
ax.set_xlabel('w', fontsize=16)
ax.set_ylabel('b', fontsize=16)
ax.set_zlabel('\nlog(Cost)', fontsize=16)
ax.set_title('log(Logistic Cost) vs (w, b)')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
plt.show()
return cost
def soup_bowl():
""" creates 3D quadratic error surface """
#Create figure and plot with a 3D projection
fig = plt.figure(figsize=(4,4))
fig.canvas.toolbar_visible = False
fig.canvas.header_visible = False
fig.canvas.footer_visible = False
#Plot configuration
ax = fig.add_subplot(111, projection='3d')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_rotate_label(False)
ax.view_init(15, -120)
#Useful linearspaces to give values to the parameters w and b
w = np.linspace(-20, 20, 100)
b = np.linspace(-20, 20, 100)
#Get the z value for a bowl-shaped cost function
z=np.zeros((len(w), len(b)))
j=0
for x in w:
i=0
for y in b:
z[i,j] = x**2 + y**2
i+=1
j+=1
#Meshgrid used for plotting 3D functions
W, B = np.meshgrid(w, b)
#Create the 3D surface plot of the bowl-shaped cost function
ax.plot_surface(W, B, z, cmap = "Spectral_r", alpha=0.7, antialiased=False)
ax.plot_wireframe(W, B, z, color='k', alpha=0.1)
ax.set_xlabel("$w$")
ax.set_ylabel("$b$")
ax.set_zlabel("Cost", rotation=90)
ax.set_title("Squared Error Cost used in Linear Regression")
plt.show()
def plt_simple_example(x, y):
""" plots tumor data """
pos = y == 1
neg = y == 0
fig,ax = plt.subplots(1,1,figsize=(5,3))
fig.canvas.toolbar_visible = False
fig.canvas.header_visible = False
fig.canvas.footer_visible = False
ax.scatter(x[pos], y[pos], marker='x', s=80, c = 'red', label="malignant")
ax.scatter(x[neg], y[neg], marker='o', s=100, label="benign", facecolors='none', edgecolors=dlblue,lw=3)
ax.set_ylim(-0.075,1.1)
ax.set_ylabel('y')
ax.set_xlabel('Tumor Size')
ax.legend(loc='lower right')
ax.set_title("Example of Logistic Regression on Categorical Data")
def plt_two_logistic_loss_curves():
""" plots the logistic loss """
fig,ax = plt.subplots(1,2,figsize=(6,3),sharey=True)
fig.canvas.toolbar_visible = False
fig.canvas.header_visible = False
fig.canvas.footer_visible = False
x = np.linspace(0.01,1-0.01,20)
ax[0].plot(x,-np.log(x))
ax[0].set_title("y = 1")
ax[0].set_ylabel("loss")
ax[0].set_xlabel(r"$f_{w,b}(x)$")
ax[1].plot(x,-np.log(1-x))
ax[1].set_title("y = 0")
ax[1].set_xlabel(r"$f_{w,b}(x)$")
ax[0].annotate("prediction \nmatches \ntarget ", xy= [1,0], xycoords='data',
xytext=[-10,30],textcoords='offset points', ha="right", va="center",
arrowprops={'arrowstyle': '->', 'color': dlorange, 'lw': 3},)
ax[0].annotate("loss increases as prediction\n differs from target", xy= [0.1,-np.log(0.1)], xycoords='data',
xytext=[10,30],textcoords='offset points', ha="left", va="center",
arrowprops={'arrowstyle': '->', 'color': dlorange, 'lw': 3},)
ax[1].annotate("prediction \nmatches \ntarget ", xy= [0,0], xycoords='data',
xytext=[10,30],textcoords='offset points', ha="left", va="center",
arrowprops={'arrowstyle': '->', 'color': dlorange, 'lw': 3},)
ax[1].annotate("loss increases as prediction\n differs from target", xy= [0.9,-np.log(1-0.9)], xycoords='data',
xytext=[-10,30],textcoords='offset points', ha="right", va="center",
arrowprops={'arrowstyle': '->', 'color': dlorange, 'lw': 3},)
plt.suptitle("Loss Curves for Two Categorical Target Values", fontsize=12)
plt.tight_layout()
plt.show()
到了这里,关于【机器学习】Cost Function for Logistic Regression的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!