文章来源地址https://www.toymoban.com/news/detail-627451.html
文章来源:https://www.toymoban.com/news/detail-627451.html
到了这里,关于Netty使用和常用组件辨析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了Netty使用和常用组件辨析。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
文章来源地址https://www.toymoban.com/news/detail-627451.html
文章来源:https://www.toymoban.com/news/detail-627451.html
到了这里,关于Netty使用和常用组件辨析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!
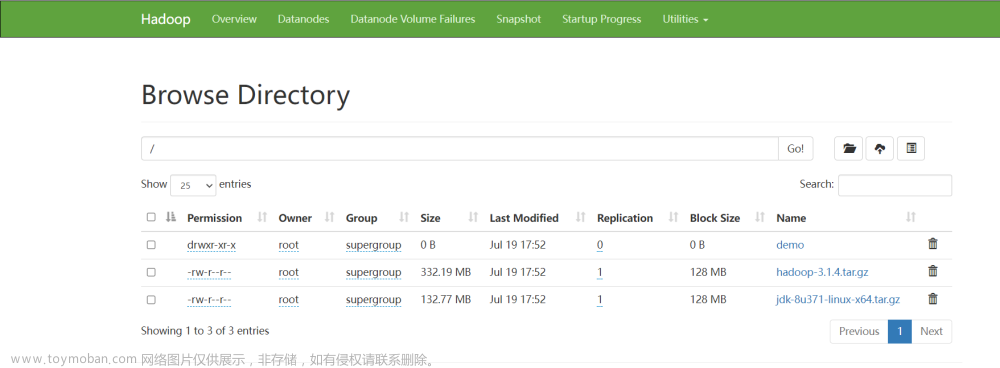
存储整个HDFS集群的元数据(metaData) —— 整个集群中存储的目录和文件的索引 管理整个HDFS集群 接收客户端的请求 负责节点的故障转移 存储数据,是以block块的形式进行数据的存放。 默认情况下block块的大小是128M。 blocksize大小的计算公式: 寻址时间:下载文件时找到文件
![聊聊分布式架构06——[NIO入门]简单的Netty NIO示例](https://imgs.yssmx.com/Uploads/2024/02/726605-1.png)
目录 Java NIO和Netty NIO比较 Java NIO: Netty: Netty NIO中的主要模块 Transport(传输层) Buffer(缓冲区) Codec(编解码器) Handler(处理器) EventLoop(事件循环) Bootstrap和Channel(引导和通道) Future和Promise(异步编程) Netty示例 服务端时序图 服务端代码 客户端时序图 客户端代码

常见序列化和反序列化协议有XML、JSON、protobuf,相比于其他protobuf更有优势: 1、protobuf是二进制存储的,xml和json都是文本存储的。故protobuf占用带宽较低 2、protobuf不需要存储额外的信息。 json如何存储数据?键值对。例:Name:”zhang san”, pwd: “12345”。 protobuf存储数据的方式
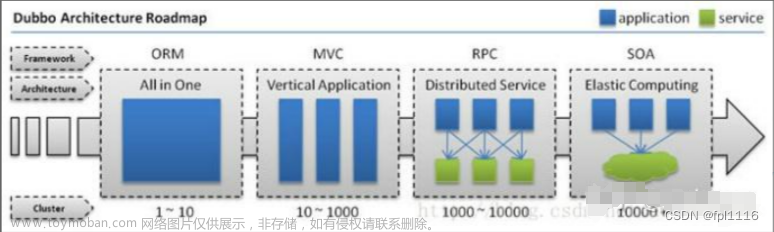
Dubbo是一个 分布式服务框架 ,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的,只有在分布式的时候,才有dubbo这样的分布式服务框架的需求。其本质上是个远程服务调用

专栏集锦,大佬们可以收藏以备不时之需 Spring Cloud实战专栏:https://blog.csdn.net/superdangbo/category_9270827.html Python 实战专栏:https://blog.csdn.net/superdangbo/category_9271194.html Logback 详解专栏:https://blog.csdn.net/superdangbo/category_9271502.html tensorflow专栏:https://blog.csdn.net/superdangbo/category_869

自定义注解实现通用分布式锁组件。 Redisson官网:https://redisson.org/ Redisson是一个基于Redis的工具包,可以帮助开发人员更轻松地使用Redis,功能非常强大。将JDK中很多常见的队列、锁、对象都基于Redis实现了对应的分布式版本并提供高级的分布式锁,分布式集合,分布式对象,
上文我们已经介绍Hadoop中HDFS分布式存储组件 今天我们来学习Hadoop生态中另两大组件Mapreduce和YARN Map阶段 : 将数据拆分到不同的服务器后执行Maptask任务,得到一个中间结果 Reduce阶段 : 将Maptask执行的结果进行汇总,按照Reducetask的计算 规则获得一个唯一的结果 我们在MapReduce计算框
安装和配置详解 本文介绍的 Zookeeper 是以 3.2.2 这个稳定版本为基础,最新的版本可以通过官网 http://hadoop.apache.org/zookeeper/ 来获取, Zookeeper 的安装非常简单,下面将从单机模式和集群模式两个方面介绍 Zookeeper 的安装和配置。 单机模式

·计算:对数据进行处理,使用统计分析等手段得到需要的结果 ·分布式计算:多台服务器协同工作,共同完成一个计算任务 分布式计算常见的2种工作模式 分散-汇总(MapReduce就是这种模式) 中心调度-步骤执行(大数据体系的Spark、Flink等是这种模式) MapReduce是“分散-汇总”模
网关作为流量的入口,常用功能包括路由转发、权限校验、限流控制。 bootstrap.yml nacos config 导入的依赖 详细的后面在介绍



