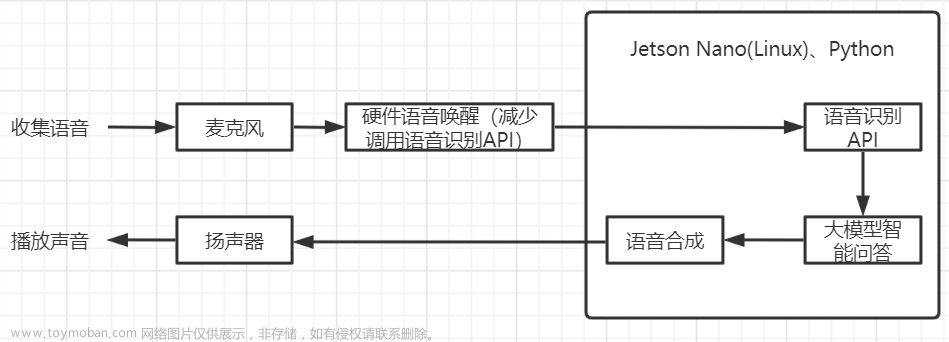
现有技术中实现一次性语音识别典型的流程时序,具体包括一下步骤:
■ MRCP Client发送INVITE消息给MRCP Server请求建立会话,携带MRCP Client侧的SDP;
■ MRCP Server回复200表示请求已经成功接受处理,携带MRCP Server侧的SDP;
■ MRCP Client随后发送ACK消息证实200消息已经收到,至此一个SIP会话成功建立;
■ MRCP Client发送RECOGNIZE消息给MRCP Server请求语音识别,按照MRCP协议规定的格式携带相关的语音识别控制参数,并且指定语法文件路径;
■ MRCP Server接收RECOGNIZE请求,编译语法文件,回复200消息给MRCP Client;
■ MRCP Client此时开始根据之前协商好的SDP,开始源源不断的发送RTP语音流给MRCP Server;
■ MRCP Server接收RTP语音流,当检测到用户开始说话时,发送START-OF-INPUT事件;
■ 当MRCP Server根据语法文件定义得到识别结果时,通过RECOGNITION-COMPLETE事件返回识别结果;
■ MRCP Client发送BYE消息给MRCP Server结束会话;
■ MRCP Server发送200消息给MRCP Client确认结束;
■ MRCP Client通过上述流程获得MRCP Server提供的一次完整语音识别能力。
电话渠道的语音流采样率一般是8k 16bit,这种语音识别的准确率远远低于app等渠道采集音频的识别率。再加上人在打电话时说话方式相对随意,导致语音识别部分成为了影响电话机器人能力和效果的重要瓶颈。
实现语音合成典型的流程时序,具体包括一下部分:
■ SPEAK:向服务器端提供文本,启动语音合成(c→s)
■ STOP:如果服务器正在语音合成资源,则停止语音合成与语音流(c→s)
■ PAUSE:通知服务器资源暂停语音合成与语音流(c→s)。
■ RESUME:通知暂停的语音合成资源继续进行语音合成与语音流(c→s)
■ CONTROL:更改语音合成资源相关参数,从而影响合成的语音流(c→s)。
■ SPEAK-COMPLETE: SPEAK请求已经成功处理(s→c)。
■ SPEECH-MARKER:服务器正在处理语音标签时,遇到请求消息头字段 Speech Marker中标记的tag(s→c)。
■ BARGE-IN-OCCURRED:客户端检测到barg-in-able事件或DTMF数字时,发送该消息通知服务器(c→s)。文章来源:https://www.toymoban.com/news/detail-627669.html
现在主流厂商为了使通话效果尽可能模拟真人外呼,除了涉及业务接口调用的数据查询使用了TTS,基本采取整句录音的方式。文章来源地址https://www.toymoban.com/news/detail-627669.html
到了这里,关于智能语音机器人语音识别系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!