微软认知服务
在csdn上面看到有微软认知服务的试用,之前正好因为一些需求,接触到了这块的一些东西,正好总结一下,之前使用的是国外的账号,这个登录以后看到是国内世纪互联运营的国内的azure,在识别这块应该针对中文方面有更好的适配
0元试用微软 Azure人工智能认知服务,精美礼品大放送(https://bbs.csdn.net/topics/601636817)
提供了下面的服务
使用Azure认知服务免费提供的AI服务(包括语音转文本、文本转语音、语音翻译、文本分析、文本翻译、语言理解)
我们来一个个的试用提供的功能
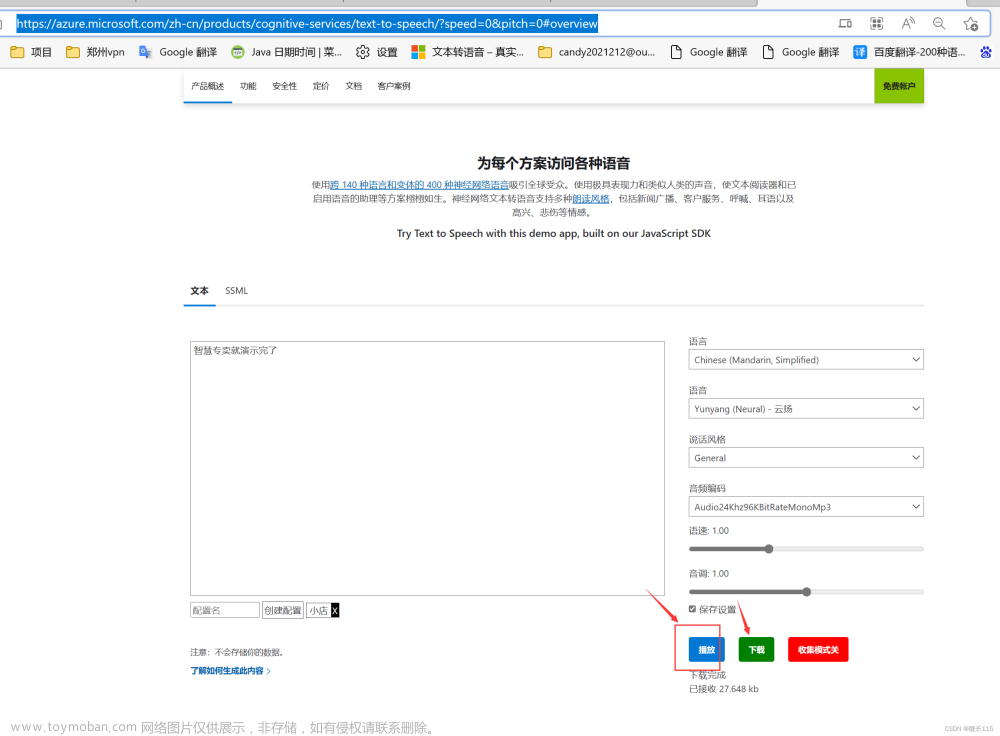
语音转文本
语音转文本的需求之前遇到过,看视频教程的时候,如果能够提前拿到整个声音的文字的内容,然后大概的过一遍,这样看视频的时候就更好了,就跟我们读书的时候,老师讲教材的内容,我们看重点关注的地方,而不用讲完了还在想刚刚漏了什么
还有个需求就是开会的时候,可以录下来,然后把会议记录转成文字的,虽然目前有很多硬件设备能够完成这个,但是拿个手机就可以录是最方便的,然后再处理下形成文字的版本
有新的电影,字幕还没有出来,想看下,自己做字幕,还有很多方面的,应用,需要实现的就是把一段语音转换成文本




服务就部署完成了
转到服务
这里就是这个服务的节点了,那个密钥与终结点就是后面需要用的一些信息
官方有一些参考手册,但是很多坑可能不会写出来,这里我用我能够跑通的进行记录,比如在centos7和centos8上面的python的sdk就有问题,但是ubuntu就没有问题,这里我们用ubuntu的环境做测试
安装和导入语音sdk
sdk就是一些封装好的东西,我们去调用就行,这个地方我对python的熟悉一些就使用python去操作
环境使用的是ubuntu18
pip3 install azure-cognitiveservices-speech
对音频有一定的要求
root@ubuntu-virtual-machine:~/rec# file voice.wav
voice.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 48000 Hz
root@ubuntu-virtual-machine:~/rec# file whatstheweatherlike.wav
whatstheweatherlike.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 16000 Hz
注意开头静音控制文章来源:https://www.toymoban.com/news/detail-627673.html
import azure.cognitiveservices.speech as speechsdk
def from_file():
speech_config = speechsdk.SpeechConfig(subscription="xxxxxxxxxxxxx",endpoint="https://chinaeast2.api.cognitive.azure.cn/sts/v1.0/issuetoken")
speech_config.speech_recognition_language="zh-cn"
#audio_input = speechsdk.AudioConfig(filename="whatstheweatherlike.wav")
audio_input = speechsdk.AudioConfig(filename="voice.wav")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_input)
result = speech_recognizer.recognize_once_async().get()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(result.text))
elif result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(result.no_match_details))
elif result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = result.cancellation_details
print("Speech Recognition canceled: {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(cancellation_details.error_details))
print(result.text)
from_file()
提供音频的例子
准备找个新闻联播的来识别
注意开头不能静音太久,会有问题,应该有参数控制文章来源地址https://www.toymoban.com/news/detail-627673.html
到了这里,关于微软认知服务-语音识别相关的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!