一、不同格式数据读取及转换
使用索引方式,返回结果为DataFrame格式
dataset = pd.read_csv('SNP.csv',encoding='gbk',index_col=0)
X_features = dataset.iloc[:,1:2050]
y_label = dataset.iloc[:, 0]
将数据集分为特征矩阵X和目标变量y,返回结果为DataFrame格式
X = dataset.drop('LABEL', axis=1)
y = dataset['LABEL']
另外一种将数据转化为numpy的格式为
features = [x for x in dataset.columns if x not in ['LABEL']]
# split data into X and y
Xf = dataset[features].values
yf = dataset[['LABEL']].values
feature_names=list(features)
二、数据预处理
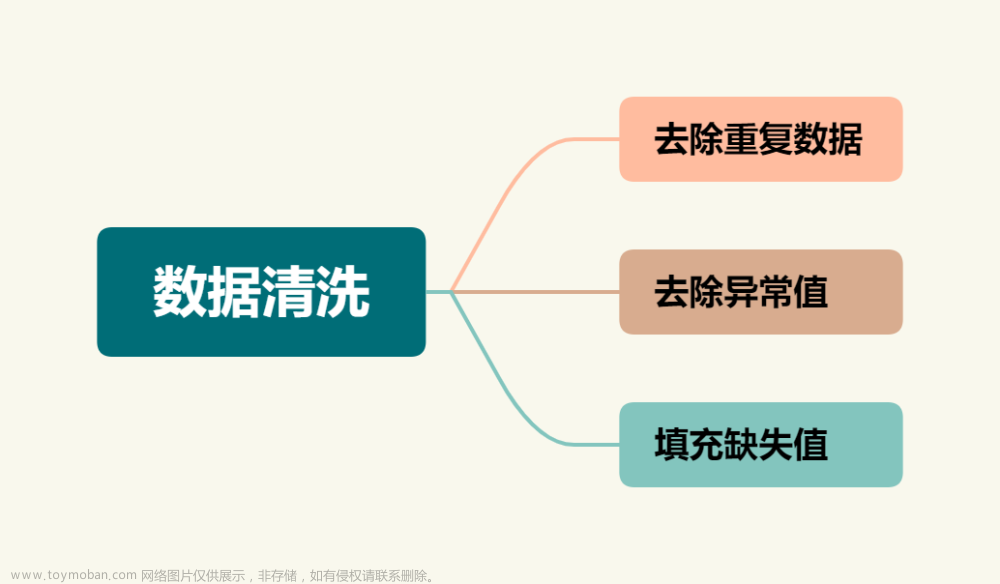
1、去重
df = df.drop_duplicates().reset_index(drop=True)
2、删除某一列
df2=df2.drop(cols,axis=1)
3、删除两行
df.drop(index=[0, 1])
4、date转字符串
from datetime import datetime, date, time
d = date.fromisoformat('2018-09-22')
t = time.fromisoformat('16:28:22')
dt = datetime.fromisoformat('2018-09-22')
sdate = pd.to_datetime(ds).strftime('%Y-%m-%d')
st = "2019-01-20 00:00:00"
dt = datetime.datetime.strptime(st, '%Y-%m-%d %H:%M:%S')
st = "2019-01-20"
dt = datetime.datetime.strptime(st, '%Y-%m-%d')
start=pd.to_datetime('2017-01-01')
5、修改类型
train['tf_status'] = t1['tf_status'].astype(np.int64)
6、修改日期类型
df['ds'] = pd.to_datetime(df['ds'])
7、修改字段名
df.rename(columns={'#studentid':'studentid'}, inplace = True)
8、加年月
df['year']=df.datetime.apply(lambda x: x.year)
df['month'] = df.datetime.apply(lambda x: x.month)
df['year'] = df['year'].astype(np.int64)
df['month'] = df['month'].astype(np.int64)
9、 删除字段
df.drop([‘#id’], axis=1, inplace=True)
10、 查看数据中顶部10%的数据
print(df.weeks.quantile(np.arange(.9,1,.01)))
11、设置索引
df = df.set_index([‘hetongdetailid’])
12、判断空值
print(“在 cat 列中总共有 %d 个空值.” % df[‘cat’].isnull().sum())
print(“在 review 列中总共有 %d 个空值.” % df[‘review’].isnull().sum())
df[df.isnull().values==True]
df = df[pd.notnull(df[‘review’])]
13、排序
df.sort_values(by=“x1”,ascending= False)
14、 模糊查询
df_remark_tf[df_remark_tf[“content_method”].str.contains(keystring)]
15、修改字段类型
df_appraise[‘deptid’] = df_appraise[‘deptid’].astype(np.int64)
16、修改数据
(https://blog.csdn.net/zhangchuang601/article/details/79583551)
df.loc[1,[‘name’,‘age’]] = [‘bb’,11]
df.iloc[1,2] = 19#修改某一无
df.loc[df[df.htid.isin(ids)].index,“y”]=1
17、保存数据库
df.to_sql(name=‘predict’,con=mysql_engine,if_exists = ‘replace’)
18、生成日期
dt = datetime.datetime(year, month, 1)
19、查看顶部10%数据分布
print(movie_rating_count[‘totalRatingCount’].quantile(np.arange(.9,1,.01)))
三、数据可视化
#-------plotly.express-------------------------
1、折线图
import plotly.express as px
fig = px.line(df, x=‘date’, y=‘y_true’,
labels={‘date’:‘日期’, ‘y_true’:‘话务量’},
markers=True)
fig.update_xaxes(tickformat = “%Y-%m-%d”, hoverformat = “%Y-%m-%d”)
fig.update_layout(title_text=“热线部门日业务量趋势图”, title_x=0.5)
fig.update_traces(marker=dict(size=3)) #控制点的大小
fig.show()
2、散点图
fig = px.scatter(df, x=“真实订单量”, y=“真实金额”,hover_data=[‘did’,‘日期’])
fig.update_traces(marker=dict(size=4)) #点的大小
fig.show()
四、虚拟环境配置与安装
------------------更新pip命令----------------------------------------
python -m pip install --upgrade pip
如果升级失败,明明执行的就是pip升级命令,但是最后一句提示用一样的代码升级。其实是权限问题,小伙伴们按下面的代码升级即可!!!在代码后面加上 --user表示信任:
python-m pip install–upgrade pip --user
-------------搭建虚拟环境-----------------------------
1、 创建虚拟环境
conda create --name yourenvname python=3.8
2、 进入虚拟环境
conda activate yourenvname
3、退出虚拟环境
conda deactivate
4、 删除虚拟环境
conda remove -n py39 --all
5、在jupyter notebook中添加虚拟环境
python -m ipykernel install --user --name yourenvname --display-name “display-name”
6、在jupyter notebook里面添加虚拟环境
cmd进入虚拟环境(torch_env)
activate torch_env
pip install ipykernel ipython
回车
python kernel install --user --name torch_env
回车
再次进入jupyter notebook
右上角,new,即可选择需要的虚拟环境。
5.另外,如果需要在指定文件夹中打开jupyter notebook,只需要打开文件夹所在位置,点击搜索框左边的位置框,输入cmd,再输入jupyter notebook,即可将路径设为自己需要的。
在jupyter 中删除虚拟环境
jupyter kernelspec uninstall myenv
7、pip install 镜像安装
pip install package_name -i https://pypi.tuna.tsinghua.edu.cn/simple
五 、其他
1、nohup command &
例如 nohup jupyter notebook &
2、找到进程PID(关闭在前面后台执行的进程的步骤,首先找到其进程PID)
ps -ef | grep xxxx
ps -ef 查看本机所有的进程;grep xxxx代表过滤找到条件xxxx的项目
3、kill掉进程
kill -9 具体的PID
-------------打开指定端口-------------------------------------
firewall-cmd --zone=public --add-port=8504/tcp --permanent
firewall-cmd --reload文章来源:https://www.toymoban.com/news/detail-627696.html
netstat -ntlp //查看当前所有tcp端口·
netstat -ntulp |grep 8888 //查看所有1935端口使用情况文章来源地址https://www.toymoban.com/news/detail-627696.html
到了这里,关于常用数据处理方式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!