使用Python爬取公众号的合集
前言
。。。最近老是更新关于博客的文章,很久没更新其他的了,然后写一下如何爬取微信公众号里面的图片吧!
先看看微信公众号的样子吧:

我爬取的是公众号的合集内容
讲解
首先用手机打开某个图片公众号的文章,然后复制链接用电脑打开,它的url为:
以下所展示的链接都是被我修改了的
https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=MzDg3MjY3g==&album_id=2646021169516584499&count=10&begin_msgid=2247483683&begin_itemidx=1&is_reverse=1&uin=&key=&pass_ticket=&wxtoken=&devicetype=&clientversion=&__biz=Mzg2MDg3MjY3Mg%3D%3D&appmsg_token=&x5=0&f=json
每个参数的作用
-
action: 操作类型,值为getalbum。 -
__biz: 公众号的唯一标识,值为MzDg3MjY3g==。 -
album_id: 相册的唯一标识,值为2646021169516584499。 -
count: 需要获取的相册数量,值为10。 -
begin_msgid: 开始的消息ID,值为2247483683。 -
begin_itemidx: 开始的项目索引,值为1。 -
is_reverse: 是否倒序,值为1。 -
uin: 用户uin,值为空。 -
key: 密钥,值为空。 -
pass_ticket: 通行证,值为空。 -
wxtoken: 微信令牌,值为空。 -
devicetype: 设备类型,值为空。 -
clientversion: 客户端版本,值为空。 -
appmsg_token: 文章令牌,值为空。 -
x5: x5参数,值为0。 -
f: 返回的数据格式,值为json。
爬取思路
可以看到文章开头的图片,公告号的每篇文章都是能跳转的,我们爬取图片肯定也是爬取跳转之后页面的图片,那么第一件事就是先获取所有文章的url。然后我的思路是将url爬取后保存到csv文件中,然后再从csv中读取url进一步解析图片的位置,然后下载图片。这就是整体思路。
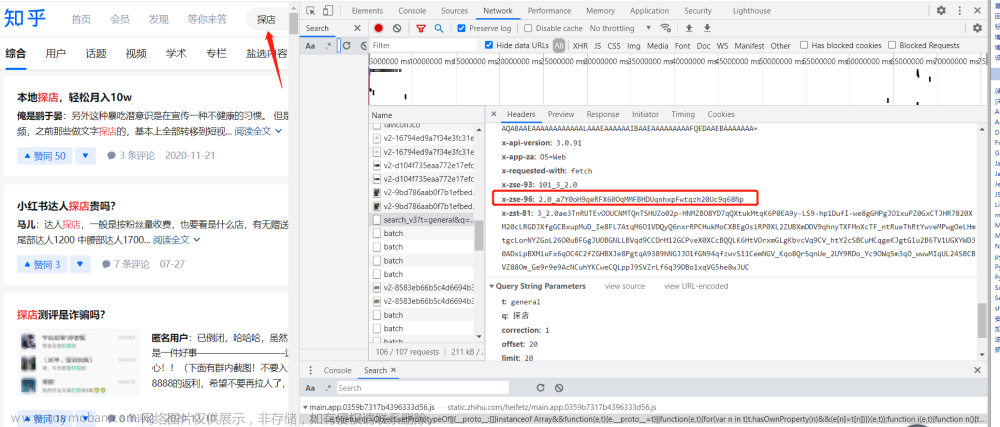
首先文章列表能够显示再网页上,那它必定是请求后端了的,那么请求后端我们就能拿到API接口,如图:

可以看到也是成功获取到了接口,然后里面返回的列表就是网页中展示的文章列表了,这就非常好办了。我们只需要请求这个接口就能获取到所有文章的url了,然后微信公众号合集内容的规则就是,获取最后一条数据的消息ID是下一条数据开始的消息ID,所以当我们爬取到一个列表,假如这个列表有10条数据,那么第10条数据的msgid就是下一次请求的begin_msgid,这样就能获取11-20的数据,依次内推就能获取所有文章了,之前试过想一次性获取全部文章,好像不太行,所以用一个循环然后去修改begin_msgid参数发送请求就行了。
开爬
爬取文章url
需要用到的库
import requests
import json
import csv
import time
参数上面已经讲过了就不讲了。
请求头的Referer和Cookie,用浏览器的开发工具(F12)找到文章请求,然后就能获取到。
# 设置请求参数
url = 'https://mp.weixin.qq.com/mp/appmsgalbum'
# 设置请求参数
params = {
'action': 'getalbum',
'__biz': 'MzDg3MjY3g==',
'album_id': '2646021169516584499',
'count': 10,
'is_reverse': 1, # 为倒叙也就是从第一篇文章开始
'uin': '',
'key': '',
'pass_ticket': '',
'wxtoken': '',
'devicetype': '',
'clientversion': '',
'__biz': 'MzDg3MjY3g==',
'appmsg_token': '',
'x5': 0,
'f': 'json'
}
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': '',
'Host': 'mp.weixin.qq.com',
'Accept-Encoding': 'gzip, deflate',
'Cookie': ''
}
分段展示代码
# 设置请求频率限制
MAX_REQUESTS_PER_MINUTE = 10
REQUEST_INTERVAL = 60 / MAX_REQUESTS_PER_MINUTE
# 发送请求,获取第一页相册内容
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = json.loads(response.text)
album = data['getalbum_resp']['article_list']
last_msgid = album[-1]['msgid'] # 获取最后一张图片的消息ID 用作下次请求的begin_msgid
else:
print('获取相册内容失败:', response.status_code)
# 循环发送请求,获取所有相册内容
result = []
while True:
params['begin_msgid'] = last_msgid
params['begin_itemidx'] = 1
print(url)
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
data = json.loads(response.text)
album = data['getalbum_resp']['article_list']
if len(album) == 0:
break # 如果相册为空,则退出循环
for photo in album:
# 获取url和title
url2 = photo['url']
title = photo['title']
result.append({'url': url2, 'title': title})
# 保存到csv文件中
with open('blogimg3.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=['url', 'title'])
writer.writerow({'url': url2, 'title': title})
# 控制请求频率
time.sleep(REQUEST_INTERVAL)
last_msgid = album[-1]['msgid'] # 获取最后一张图片的消息ID,用于下一次请求
else:
print('获取相册内容失败:', response.status_code)
break
ok 然后坐等爬取完成,我这里是做了请求限制了的,如果想爬快一点把限制删掉就行了。
文章爬取结果


也是爬取完成了,但是爬完之后会报KeyError: 'article_list'的错误,这个无关紧要,因为已经请求到最后数据之后的请求了,导致获取不到这个article_list的json数据了。

然后看到上面的图片是254个内容,但是爬取的链接只有244条,数据缺失了几条,但是程序也没出现问题,所以就不管了,也就几条数据,不影响,毕竟找出问题得花大量的时间。
爬取图片
上面只是爬取了文章的url,现在要进入文章爬取图片了。
首先,需要用到的库
import csv
import requests
from lxml import etree
import os
from urllib.parse import urlparse
import time
然后爬取图片的思路就是解析我们之前爬取的文章url,通过遍历文章url,去使用xpath去匹配文章里面的图片就行了,第一次爬取出现了点小问题,后面会讲。
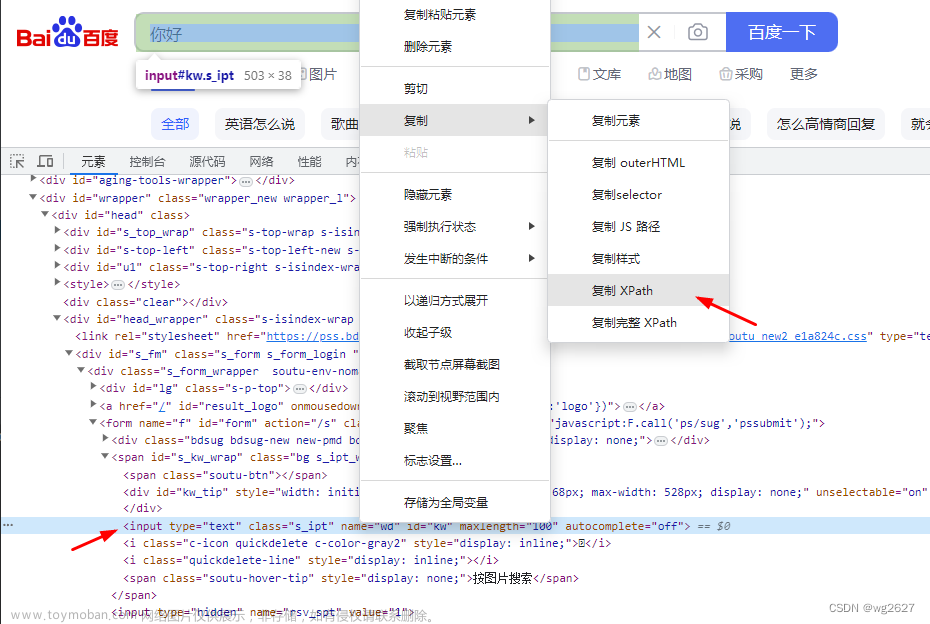
关于Xpath获取
偷懒方式如下:

匹配图片url函数 download_images
def download_images(url):
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Referer': '',
'Host': 'mp.weixin.qq.com',
'Accept-Encoding': 'gzip, deflate',
'Cookie': ''
}
# 发送请求
response = requests.get(url, headers=headers)
# 解析HTML
html = etree.HTML(response.text)
# 获取图片
img_elements = html.xpath('//*[@id="js_content"]/section/section[4]/p/img/@data-src')
if len(img_elements) == 0:
img_elements = html.xpath('//*[@id="js_content"]/section/section[4]/p/span/img/@data-src')
print(img_elements)
# 下载图片
for url in img_elements:
print(f"下载图片:{url}")
download_image(url, 'blogimg4_1')
**下载图片函数 **download_image
# 下载
def download_image(url, img_dir):
# 解析url
parsed_url = urlparse(url).path
wx_fmt = parsed_url.split('/')[1].split('_')[1]
# 获取文件名
filename = url.split('/')[-2] + '.' + wx_fmt
# 发送请求
response = requests.get(url)
# 保存图片
with open(os.path.join(img_dir, filename), 'wb') as f:
f.write(response.content)
main方法
if __name__ == '__main__':
with open('blogimg3_1.csv',newline='',encoding='utf-8') as f:
# 读取csv文件内容
reader = csv.reader(f)
# 遍历每一行
for row in reader:
# 提取第一列的url
url = row[0]
# 发送请求
try:
download_images(url)
except Exception as e:
print(f'Error: {e}')
continue
time.sleep(2)
图片爬取结果

可以看到有个别图片没有正常显示,那是因为这个公众号最新的文章图片url和之前不一样,我也是爬完才发现,虽然才几张图片,但是得优化一下
第一次爬取,爬到了1333张图片

优化下载图片代码
download_image函数:
# 解析url
parsed_url = urlparse(url)
path_parts = parsed_url.path.split('/')
# 判断链接特征并提取参数值
if 'wx_fmt' in parsed_url.query:
wx_fmt = parsed_url.query.split('=')[1]
# 获取文件名
filename = path_parts[-2] + '.' + wx_fmt
elif 'mmbiz_jpg' in path_parts:
filename = os.path.splitext(path_parts[2])[0] + '.jpg'
elif 'mmbiz_png' in path_parts:
filename = os.path.splitext(path_parts[2])[0] + '.png'
# 发送请求
response = requests.get(url)
# 保存图片
with open(os.path.join(img_dir, filename), 'wb') as f:
f.write(response.content)
优化之后也是没有出现图片无法显示的情况,然后爬取了1368张图片。

声明
文章出现的代码只用于学习,不会影响公众号正常运行,如有侵权,联系站长删除。
爬取下来的图片将不会保存,望知~
QQ邮箱:1767992919@qq.com
结尾
公众号是没有反爬机制的,所以爬取下来很容易,不过公众号放的图片都不够高清,但是也还是能看。如果也想学习学习如何爬取的,可以关注公众号私信我,找我要链接。如果有更好的图片网站,也可以私信我~文章来源:https://www.toymoban.com/news/detail-628261.html
 文章来源地址https://www.toymoban.com/news/detail-628261.html
文章来源地址https://www.toymoban.com/news/detail-628261.html
到了这里,关于使用Python爬取公众号的合集内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!