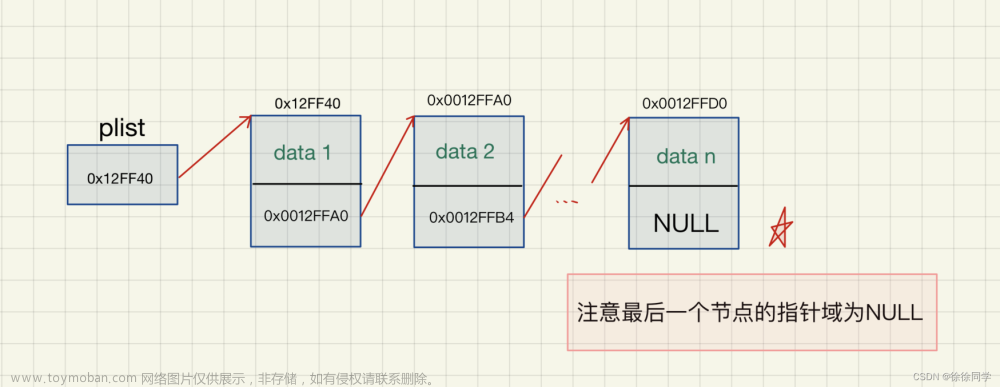
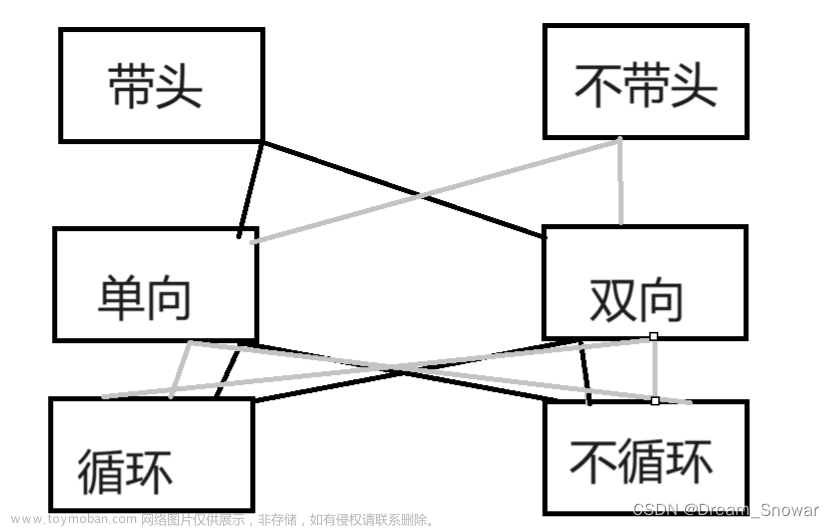
题型一(线性表的存储结构)
1、线性表的顺序存储结构是一种()存储结构。
A、顺序存取
B、随机存取
C、索引存取
D、散列存取
解析:(B)顺序存储结构的可以实现随机存取,可以在O(1)内通过首地址和元素序号找到元素,每个元素占用最少的存储空间,其存储密度高,但只能使用相邻的一块存储单元,从而可能会产生较多的外部碎片。
2、一个顺序表所占的存储空间大小与()无关。
A、表的长度
B、元素的存放顺序
C、元素的类型
D、元素中各字段的类型
解析:(B)
顺序存储结构中把逻辑上相邻的元素存储在物理位置上也相邻的存储单元里,元素之间的关系由存储单元的邻接关系来体现,设sizeof(ElemType)是每个数据元素所占用的存储空间大小,即该顺序表的存储空间大小=表长×sizeof(元素类型),所以与元素的存放顺序无关。
3、若一个线性表最常用的操作是在表尾插入元素和删除表头元素,则采用()存储结构最节省时间。
A、仅有头指针的单链环
B、仅有尾指针的单链环
C、单链表
D、双链表
解析:(B)
单链表在插入/删除元素遍历寻找元素位置时,只能从表头遍历到表尾;虽然双链表可以来回遍历,但若在表尾插入/删除一个元素时仍需遍历整个链表;仅有头指针的单链环中,当在链表中的第一个位置进行插入/删除操作很方便,但若在表尾插入/删除一个元素时,也只能从表头遍历到表尾。
题型二(链表的判空条件)
1、单链表L(带头结点)和单链表L(不带头结点)为空的判断条件为()。
A、L==NULL,L ==NULL
B、L→next == NULL,L ==NULL
C、L→next != NULL,L ==NULL
D、L!= NULL,L ==NULL
解析:(B)带头结点的单链表中,由于带有头结点,首先要通过malloc()函数分配一个头结点L,如下:
L=(LNode *)malloc(sizeof(LNode)); //分配一个头结点
当头结点之后暂时还没有任何结点,表示空链表,即L→next=NULL。
不带头结点的单链表中,由于不带头结点,可直接将单链表置为空,即L ==NULL。
2、双链表L(带头结点)和单链表L(不带头结点)为空的判断条件为()。
A、L==NULL,L ==NULL
B、L→next == NULL,L ==NULL
C、L→next != NULL,L ==NULL
D、L!= NULL,L ==NULL
解析:(B)带头结点的双链表中,与带头结点和不带头结点的单链表一样,也是要先分配一个带头结点的单链表,所以其判断空表的条件一样,也是L→next=NULL和L ==NULL。
3、带头结点head的单向循环链表L为空的判断条件是()和不带头结点head的单向循环链表L为空的判断条件是()。
A、L ==NULL,L ==head→next
B、L ==L,L ==NULL
C、L ==head→next,L ==NULL
D、L ==NULL,L ==NULL
解析:(C)
循环单链表可以实现从任一个结点访问链表中的任何结点,在带头结点的循环单链表中,若L == head→next时,循环单链表为空;在不带头结点的循环单链表中,若L ==NULL时,循环单链表为空。
4、带头结点head的双向循环链表L为空的判断条件是()和不带头结点head的双向循环链表L为空的判断条件是()。
A、head→prior == head&&head→nex t ==head,head ==NULL
B、head ==NULL,head→prior == head&&head→nex t ==head
C、head ==NULL,head ==NULL
D、head→next=head→prior,head→next=head→prior
解析:(A)带头结点的双向循环链表,若head→prior == head&&head→next ==head时,则该双链表为空。(即其头结点的prior和next域都指向其本身时为空)
不带头结点的双向循环链表,当head为空时,表明此双向循环无头结点链表为空,即head==NULL。
题型三(单链表的建立)
1、对于一个具有n个元素的线性表,建立其单链表的时间复杂度为()。
A、O(1)
B、O(n)
C、O(log2n)
D、O(n2)
解析:(B)
单链表的建立过程是将每个结点逐个插入到单链表中,每次插入操作的时间复杂度为O(1),若单链表规模为n,所以建立单链表的时间复杂度为n×O(1)=O(n)。
题型四(顺序表的操作)
1、(填空)在一个长度为n的顺序表中第i个元素(1≤i≤n)之前插入元素时,需向后移动________个元素,删除第i个元素(1≤i≤n)需向前移动________个元素。
解析:n-i+1;n-i
2、在顺序表中插入一个元素的时间复杂度为(),删除一个元素的时间复杂度为()。
A、O(n),O(1)
B、O(1),O(n)
C、O(1),O(1)
D、O(n),O(n)
解析:(D)
顺序表插入操作和删除操作实际上都是元素的移动,即在一个表长为n的顺序表中的i位置上操作和删除一个元素,需要进行元素移动的次数为n-i次,操作和删除操作的平均元素移动次数分别为n/2、(n-1)/2次,故时间复杂度都为O(n)。
3、在线性表的下列存储结构中,读取元素花费时间最少的是()。
A、顺序表
B、单链表
C、双向链表
D、循环链表
解析:(A)
由于顺序表在O(1)时间访问线性表中第i个数据元素,所以其读取元素花费时间最少。
题型五(单链表的操作)
1、在单链表中在结点后插入一个结点的时间复杂度为()、在结点前插入一个结点的时间复杂度为()。
A、O(n),O(1)
B、O(1),O(n)
C、O(1),O(1)
D、O(n),O(n)
解析:(A)后插操作,其时间开销主要在于查找第i-1个元素,即O(n),将新结点的指针域指向下一个结点,同时将该结点与前一个结点连接即可。
前插操作,也是将新结点的指针域指向下一个结点,该结点与前一个结点连接,然后通过一个中间变量将上一个结点的数据域与该结点交换即可,从而使时间复杂度达到O(1)。
2、在单链表中删除第i个结点的时间复杂度为(),若将删除结点 * p的操作转换为删除结点 * p的后继结点来实现,其时间复杂度为()。
A、O(n),O(n)
B、O(1),O(n)
C、O(1),O(1)
D、O(n),O(1)
解析:(D)
删除结点操作也是主要在于查找第i-1个元素,即O(n)。
若将删除结点 * p的操作转换为删除结点 * p的后继结点来实现,将下一个结点的指针域指向上一个结点,在交换数据域后,将* q结点从单链表中断开并释放该结点即可,这样的时间复杂度为O(1)。
3、(填空)对于一个具有n个结点的有序单链表,向其中插入一个新结点仍保持有序的时间复杂度为_________。
解析:O(1)
对于一个具有n个结点的有序单链表,向其中插入一个新结点仍保持有序的时间复杂度为O(n)。首先要找到一个大于或小于某结点的直接前驱结点p,在p后插入结点,查找所需时间为O(n),插入所需时间为O(1)。
题型六(双链表的操作)
1、在一个双链表中,在p结点之后插入一个结点q的操作是()。
A、q→prior=p;p→next=q;p→next→prior=q;q→next=p→next
B、q→next=p→next;p→next=q;q→prior=p;p→next→prior=q
C、p→next=q;q→prior=p;q→next=p→next;p→next→prior=q
D、q→prior=p;p→next=q;q→next=p→next;p→next→prior=q
解析:(B)
如下图,操作①(q→next=p→next)、②(p→next=q)的目的是将要插入的结点q的prior、next域与两边的结点连接起来:
2、在一个双链表中,在p结点之前插入一个结点q的操作是()。
A、p→prior=q;q→next=p;p→prior→next=q;q→prior=p→prior
B、q→prior=p→prior;p→prior→next=q;q→next=p;p→prior=q→next
C、q→next=p;p→next=q;q→prior→next=q;q→next=p
D、p→prior→next=q;q→next=p;q→prior=p→prior;p→prior=q
解析:(D)
如下图,操作①(p→prior→next=q)、②(q→next=p)的目的是将要插入的结点q的prior、next域与两边的结点连接起来:
3、在一个双链表中,删除表中结点p的后继结点q的操作顺序是()。
①p→next=q→next;
②q→next→prior=p;
③free(q);
A、①②③
B、②①③
C、③②①
D、③①②
解析:(A)
如下图:
4、在一个双链表中,删除表中结点q的操作是()。
A、q→next→prior=q→prior;q→prior→next=q;free(q)
B、q→prior→next=q→next;q→next→prior=q→prior;free(q)
C、free(q);q→next→prior=q;q→next=q→next→next
D、free(q);q→next=q→prior→prior;q→prior=q→prior→prior
解析:(B)
如下图:
题型七(循环单链表的操作)
1、非空的循环单链表head的尾结点p满足()。
A、p→link == head
B、p→link == NULL
C、p == NULL
D、p == head
解析:(A)
当p指针的link域指向head头指针时表示p指针指向的元素是尾元素,即当p == head满足条件,如下图循环单链表:
2、某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用()存储方式最节省时间。
A、单链表
B、仅有头指针的单循环链表
C、双链表
D、仅有尾指针的单循环链表
解析:(D)
选择仅有尾指针的单循环链表时,当在最后插入结点和删除第一个结点的时间复杂度都为O(1),所以选择D选项。而仅有头指针的单循环链表中,在最后插入结点则需要遍历整个链表,即需要O(n)的时间。
题型八(循环双链表的操作)
1、在一个以h为头指针的双向循环链表中,指针p所指的元素是尾元素的条件是()。
A、p == h
B、h→rlink == p
C、p→llink == h
D、p→rlink == h
解析:(D)
当p指针的rlink域指向h头指针时表示p指针指向的元素是尾元素,即当p→rlink == h满足条件,如下图循环双链表:
2、设一个链表最常用的操作是在末尾插入结点和删除尾结点,则选用()最节省时间。
A、单链表
B、单循环链表
C、带尾指针的单循环链表
D、带头结点的双循环链表
解析:(D)
当在末尾插入结点和删除尾结点时,若采用带尾指针的单循环链表,则末尾插入结点,由于尾指针R→next即为头指针,对表头和表尾只需要O(1)的时间复杂度,而删除尾结点时需要遍历整个链表,时间复杂度为O(n)。带头结点的双循环链表实现这两种都是O(1)的时间复杂度。
3、对于双向循环链表,在p指针所指的结点之后插入s指针所指结点的操作应为()。
A、p->right=s、s->left=p、p->right->left=s、s->right=p->right;
B、p->right=s、、p->right->left=s、s->left=p、s->right=p->right;
C、s->left=p、s->right=p->right、p->right=s、p->right->left=s;
D、s->left=p、s->right=p->right、p->right->left=s、p->right=s;
解析:(D)
双链表在p指向的结点前或结点后插入结点都可以,A选项和B选项中p->right=s语句执行后*p的原后继结点断链。
题型九(静态链表)
1、静态链表中指针表示的是()。
A、下一元素的地址
B、内存储器的地址
C、下一元素在数组中的位置
D、左链或右链指向的元素的地址
解析:(C)
静态链表中指针是通过结点的数组下标表示,它是借助数组来描述链式结构的。
2、静态链表与动态链表相比,其缺点是()。
A、插入、删除时需移动较多数据
B、有可能浪费较多存储空间
C、不能随机存取
D、以上都不是文章来源:https://www.toymoban.com/news/detail-628709.html
解析:(B)
静态链表要定义一个一维数组空间,借助数组来描述链式结构,每个数组元素有两个分量,一是数据元素的值,二是指针。指针指向下一个元素在数组中的位置 (下标),插入和删除操作时只需修改指针,而不需要不移动数据,这一点与动态链表相同。静态链表不能随机存取。另外,若定义的数组太大,有可能浪费较多的存储空间。文章来源地址https://www.toymoban.com/news/detail-628709.html
到了这里,关于【数据结构】——线性表的相关习题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!