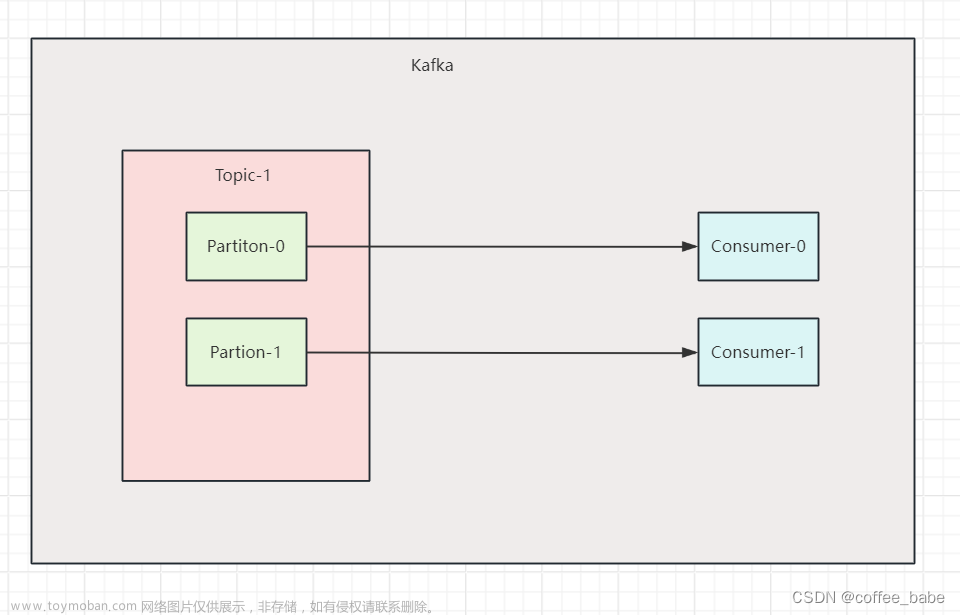
针对某个TOPIC只有几个分区积压的场景,可以采用以下方法进行排查:
-
消息生产是否指定key?
如果指定了消息key,那么消息会指定生产到hash(key)的分区中。如果指定了key,那么有下列几种可能:文章来源:https://www.toymoban.com/news/detail-628735.html
- 生产该key的消息体内容与消息处理逻辑是否有与其他分区不同
- 该key处理逻辑代码中是否有处理异常,导致偏移量无法正常提交
- 该key消息量大小比其他分区多:不指定消息key,使Kafka分区之间的数据均匀分布
-
如果不指定key的场景:文章来源地址https://www.toymoban.com/news/detail-628735.html
- 订阅该TOPIC的消费组中消费者有多少个?每个消费组负责多少个分区?如果消费者个数过少,比如说有50个分区,但只有3个消费者,那么一个消费者平均要消费16个分区。这种情况可以尝试增加消费者个数,如果使用的是spring-kafka,可以尝试增加concurrency=4/8
- 是否有消费者频繁Rebalance情况发生,导致偏移量无法提交?如果有,可以参考https://blog.csdn.net/weixin_43180484/article/details/131031640?spm=1001.2014.3001.5502进行排查
- 吞吐量不够,消费速度赶不上
- 尝试增加fetch.min.bytes参数(建议调整值1~100000)
- 增加消费者个数
- 生产端增加消息压缩:compress.type=lz4
到了这里,关于Kafka分区消息积压排查指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!