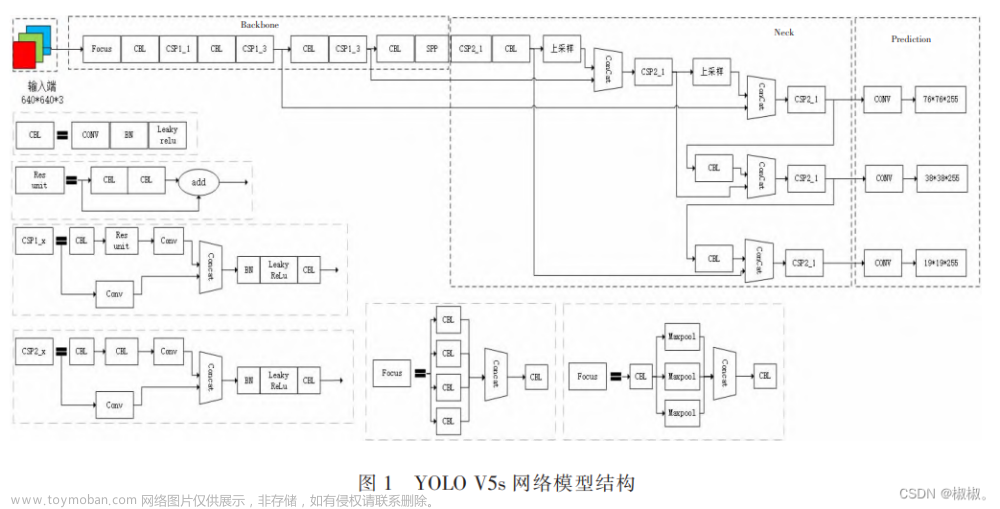
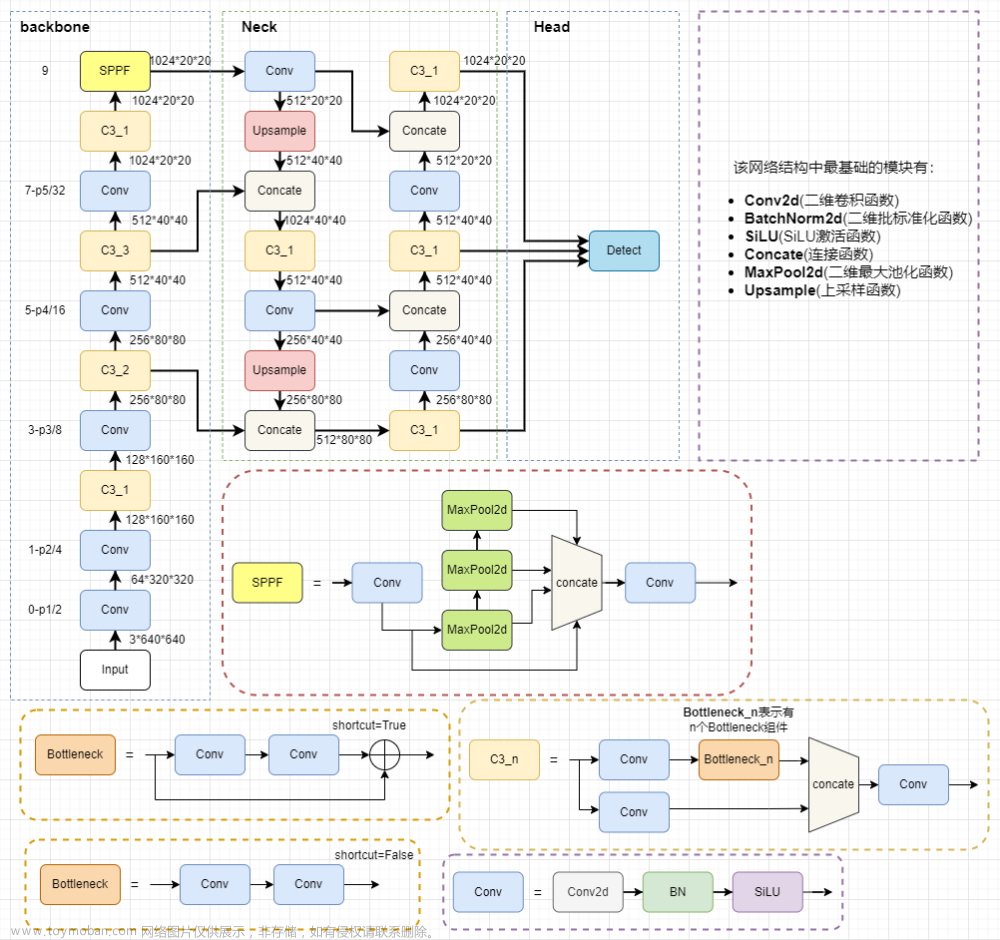
前言
在我之前的文章中,写过一种对于微小目标的检测策略,即将大图裁成多个小图,每个小图分别进行检测,最后将所有的检测结果进行叠加,统一使用NMS进行滤除。但是经过实验,该方法的效果并不是非常明显。
SAHI也采用了类似切片检测的思路,不同的是其采用了更多策略,并将其封装成了一个检测框架,支持 Detectron2,MMDetection和YOLOv5。
论文标题:Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection
论文地址:https://arxiv.org/abs/2202.06934
仓库地址:https://github.com/obss/sahi

效果概览
首先看论文里给出的这张图片,左图是原始预测效果,中间是经过SAHI预测效果,右图是经过SAHI再微调的检测效果。
可以看到,对小目标检测增强的效果还是比较明显的。
再来看数据

如表所示,经过SAHI之后,整体AP均有所提升。不过同样需要注意的是对于大目标(AP50l),经过SAHI之后,AP反而有所下降。个人猜测可能是因为切片太小导致大目标被分割。
注:这里小目标的定义是宽度小于图像宽度的1%。
原理简析
论文很短,原理也并不复杂,整体原理可以由这幅图来囊括。

上图表示切片辅助微调的过程,在原始图片提取出一些补丁块,然后将里面的部分进行放大(如图中红框所示),相当于一种数据增强。
下图表示切片辅助推断的过程,将图片裁成一块块,分别进行预测,然后用NMS统一进行过滤。
隐藏标签
由于小目标密集时,标签会发生重叠和遮挡。因此最佳方式是不显示标签,仅显示检测框。
Sahi没有像YOLOv5-6.x版本那样,预留了两个接口hide-label、hide-conf隐藏标签和置信度。看到有人在官方仓库提了这个issue,但作者直接回复不支持。。
其实改起来也很简单,无非是需要修改库源码。
首先如果是采用setup.py安装的方式,会发现安装的库文件是一个不可修改的egg文件,首先需要将其解压,提取出其中的sahi文件夹,放置在相应site-packages中。

通过阅读源码可以发现,绘图函数放在了utils/cv.py文件中。

因此,只需要将cv.py中的add bunding box text下面的内容注释掉即可。

测试效果
下面就来实际测试一下,测试代码根据官方的示例进行修改,加载本地模型。
from sahi.model import Yolov5DetectionModel
from sahi.predict import get_sliced_prediction
model_path = 'dota_best.pt'
# 使用的YOLOv5检测模型,使用gpu加速,置信度0.25
detection_model = Yolov5DetectionModel(
model_path=model_path,
confidence_threshold=0.25,
device="cuda:0"
)
# slice_height/slice_width 切片高宽
# overlap_height_ratio/overlap_width_ratio 切片间重合度
result = get_sliced_prediction(
"data/dota_img/P2826.png",
detection_model,
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2
)
# 保存检测图片
result.export_visuals(export_dir="result/")
测试图片我选择了Dota-test数据集中的一张,模型选择训练好的YOLOv5l6.pt.
直接预测结果:
经过SAHI的效果:
乍一看区别并不大,原始的模型就已经取得了可观的结果。
那么再放大来看看细节对比,这里选取右上角的一块局部区域,如下图所示,左侧为直接检测结果,右侧为经SAHI之后的结果。文章来源:https://www.toymoban.com/news/detail-628879.html

可以看到,原始检测结果中,处于房子阴影部分的车辆,以及被树枝遮挡的车辆并无法被检测出来;而经过SAHI处理之后,这部分也能够被检测出来,说明SAHI确实是有效的算法。文章来源地址https://www.toymoban.com/news/detail-628879.html
到了这里,关于【目标检测】SAHI: 切片辅助推理和微调小目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!