概述
自然语言处理(NLP)的正式定义:是一个使用计算机科学、人工智能(AI)和形式语言学概念来分析自然语言的研究领域。不太正式的定义表明:它是一组工具,用于从自然语言源(如web页面和文本文档)获取有意义和有用的信息。
NLP工具的实现一般是基于机器学习与深度学习、其它算法(Lucene Core);基于前两者的实现是比较流行且持续在探索演进。
NLP任务概述
NLP需要一组任务的组合,如下列举所示:
分词
文本可以分解为许多不同类型的元素,如单词、句子和段落(称为词或词项),并可选地对这些词执行附加处理;这种额外的处理可以包括词干提取、词元化(也称为词形还原)、停用词删除、同义词扩展和文本转换为小写。而分词一般都是基于各种分词器;比如Lucene、基于机器学习与深度学习的框架。
文本断句
文本断句也可以理解为文本识别。即识别句子(即断句);此项功能是有用的,原因有很多。一些NLP任务,如词性标注和实体提取,是针对单个句子的。对话式的应用程序还需要识别单独的句子。为了使这些过程正确工作,必须正确地确定句子边界。
将文本分割成语句也称为语句边界消歧(Sentence Boundary Disambiguation,SBD)。文本断句的常用方法包括使用一组规则或训练一个模型来检测它们。
特征工程
即用特征表示文本。特征工程在NLP应用开发中起着至关重要的作用,这对于机器学习非常重要,特别是在基于预测的模型中。它是利用领域知识将原始数据转换成特征的过程,从而使机器学习算法能够工作。特征使我们能够更集中地查看原始数据。一旦确定了特征,就进行特征选择以减少数据的维数。常用的框架及算法:
- n-gram
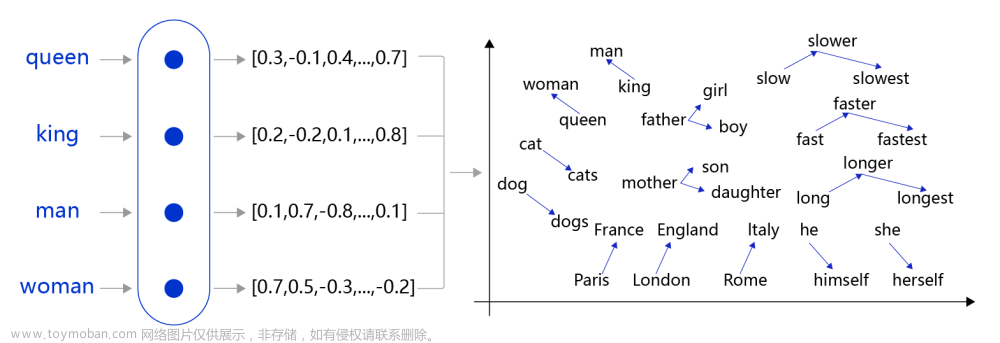
- 词嵌入
- Glove
- word2Vec
- 降维
- 主成分分析
- t-SNE
命名实体识别
识别人和事物的过程称为命名实体识别(NER)。实体(诸如人物和地点等)与具有名称的类别相关联,而这些名称识别了它们是什么。
NER过程涉及两个任务:
- 实体检测
- 实体分类
检测是指在文本中找到实体的位置。一旦找到它,确定被发现的实体是什么类型非常重要。这两个任务完成后,其结果可以用来解决其他任务,如搜索和确定文本的含义。例如,任务可能包括从电影或书评识别名字,并帮助找到可能感兴趣的其他电影或书籍。提取位置信息有助于对附近的服务提供参考。
词性标注
标注是将描述分配给词项或部分文本的过程。此描述称为标签。词性标注是将词性标签分配给词项的过程。这个过程是检测词性的核心。
一般的标注过程包括标记文本、确定可能的标签和解决歧义标签。算法用于进行词性标识(标注)。一般有两种方法。
- 基于规则:基于规则的标注器使用一组规则、单词词典和可能的标签。当一个单词有多个标签时可以使用这些规则。规则通常使用单词的上下文来选择标签。
- 基于随机域:基于随机域的标注器要么是基于马尔可夫模型,要么是基于线索的,使用决策树或最大熵。马尔可夫模型是有限状态机,其中每个状态都有两个概率分布。其目的是为句子找到最优的标签序列。还可以使用隐马尔可夫模型(Hidden Markov Model,HMM)。在这些模型中,状态转换是不可见的。
对句子进行适当的标注可以提高后续处理任务的质量,可用于许多后续任务,如问题分析、文本情感分析等。
分类
分类涉及为文本或文档中找到的信息分配标签。当过程发生时,这些标签可能已知,也可能未知。当标签已知时,这个过程称为分类。当标签未知时,该过程称为聚集。
文本分类用于多种目的:垃圾邮件检测、著作权归属、情感分析、年龄和性别识别、确定文档的主题、语言识别等。
有两种基本的文本分类技术:
- 基于规则的分类
- 有监督的机器学习
基于规则的分类使用单词和其他属性的组合,这些属性是根据专家精心设计的规则组织起来的。这些方法非常有效,但是创建它们是一个非常耗时的过程。有监督的机器学习(Supervised machine learning,SML)采用一组带注释的训练文档来创建模型。该模型通常称为分类器。有许多不同的机器学习技术,包括朴素贝叶斯、支持向量机(Support Vector Machine,SVM)和k近邻算法等。
关系提取
关系提取是标识文本中存在的关系的过程。
实体之间(例如句子的主语和它的宾语、其他实体,或者它的行为之间)存在各种关系。我们可能还想确定关系并以结构化的形式呈现它们。我们可以使用这些信息来显示结果,以供人们立即使用,或者格式化关系,以便更好地将它们用于后续任务。
提取的关系可以用于多种目的,包括:
- 建立知识库
- 创建目录
- 产品搜索
- 专利分析
- 股票分析
- 情报分析
有许多可用的技术来提取关系。可分为如下几种:文章来源:https://www.toymoban.com/news/detail-628913.html
- 手工方式
- 监督方法
- 半监督方法或无监督方法
- 引导方法
- 远程监督方法
- 无监督的方法
参考
《Java自然语言处理(原书第2版)》文章来源地址https://www.toymoban.com/news/detail-628913.html
到了这里,关于聊聊自然语言处理NLP的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!