一、Spark是什么
- Spark 是用于大规模数据处理的统一分析引擎。
- 可以对结构化、半结构化、非结构化等各种类型的数据数据结构进行自定义计算。
- 也支持Python、Java、Scala、R以及SQL语言去开发应用程序计算数据。

Spark借鉴了MapReduce思想发展而来,保留了其分布式并行计算得优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
二、运行架构
Spark框架的核心是一个计算引擎,整体来说,它采用了标准的master-slave的结构
图所示:展示了一个Spark执行时的基本架构,图中的Driver表示master,负责管理整个集群中的作业任务调度。图中的Executor则是slave,负责实际执行任务。 Spark运行架构由三个主要组件组成:Driver节点、Cluster Manager和Executor节点。
Spark运行架构由三个主要组件组成:Driver节点、Cluster Manager和Executor节点。
- Driver节点是应用程序的入口点,它负责解析用户的应用程序代码,并将任务划分成一系列的任务(stage),以及在集群上为任务安排调度。Driver节点负责管理各个任务之间的依赖关系,并将它们转换成一个可执行的物理执行计划(DAG)
- Cluster Manager负责在集群中为应用程序分配资源。它可以是Standalone,YARN或Mesos等。
- Executor节点负责在工作节点上执行任务。每个Executor都运行在自己的JVM进程中,并且为应用程序分配了一定数量的内存和CPU资源。Executor在运行过程中负责接收和执行任务。
三、核心组件
3.1、Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。
Driver在Spark作业执行时主要负责:
- 将用户程序转化为作业(job)
- 在Executor之间调度任务(task)
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
事实上,我们无法描述Driver的定义,因为在整个编程过程中没有看到任何有关Driver到的字眼,所以简单理解,所谓的Driver就是驱使整个应用运行起来的程序,也称为:Driver类。
3.1、Executor
Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在Spark作业中运行具体任务(Task),任务彼此之间相互独立。Spark应用启动时,Executor节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在。如果Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他的Executor节点上继续运行。
Executor有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
- 它们通过自身的块管理(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
3.2、Master&Worker
Spark集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master和Worker,这里的Master是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于Yarn环境中的RM,而Worker,也是进程,一个Worker运行在及群众的一台服务器上,由Master分配资源对数据进行并行的处理和计算,类似于Yarn环境中的NM。
3.3、ApplicationMaster
在Spark on Yarn模式下,ApplicationMaster是一个管理运行在YARN集群上的SparkApplication的核心组件。当用户提交一个SparkApplication时,YARN ResourceManager会为该Application分配一个ApplicationMaster。
ApplicationMaster负责以下任务:
- 申请和分配资源:ApplicationMaster向YARN ResouceManager请求资源,例如CPU和内存。在申请资源时,它会考虑当前集群资源的可用性和已经申请的资源。一旦资源被分配,ApplicationMaster会通过Spark Driver向集群中的Executor发起任务。
- 监控任务:一旦Executor启动,ApplicationMaster会持续监控Executor的状态,并在Executor失效或异常退出时进行处理。
- 与Driver通信:ApplicationMaster与Spark Driver之间通过RPC协议通信,用于任务的调度,监控以及结果的收集。
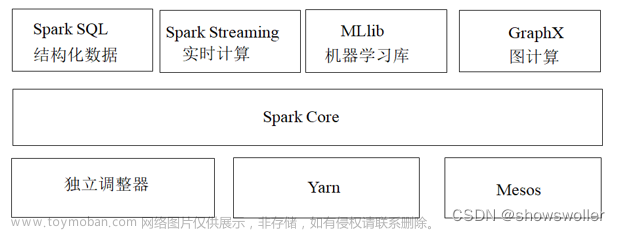
四、核心模块

- Spark Core:Spark的基础组件,提供了分布式任务调度、内存管理、错误恢复和存储系统的交互等功能
- Spark SQL:Spark的结构化数据处理组件,支持SQL查询和与外部数据源的集成,还提供了DataFrame和DataSet API,用于以编程方式处理结构化数据。
- Spark Streaming:Spark的流处理组件,支持以近实时的方式处理流式数据。
- MLlib:Spark的机器学习库,提供了常见的机器学习算法和工具。
- GraphX:Spark的图计算库,提供了图处理算法和工具。
五、核心概念
5.1、Executor
- 在Spark中,Executor是运行在集群节点上的工作进程,用于执行任务和计算数据。每个应用程序都会在集群上启动一些Executor,这些Executor会在需要的时候启动或停止,以适应应用程序的负载。
- 每个Executor都是一个JVM进程,它们之间是互相独立的,不共享内存,通过网络进行通信。Executor从Driver接收任务,然后将任务分配给自己的线程池进行执行。在执行过程中,Executor可以从Driver处请求数据,并在处理完数据后将结果返回给Driver
- Executor的数量和大小可以通过配置文件进行设置,具体的设置会根据应用程序的需求而不同。Executor的数量和大小决定了应用程序的并行度和吞吐量,因此需要根据实际情况进行调整。
修改应用程序相关启动参数
| 名称 | 说明 |
|---|---|
| –num-executors | 配置Executor的数量 |
| –executor-memory | 配置每个Executor的内存大小 |
| –executor-cores | 配置每个Executor的虚拟CPU core数量 |
5.2、并行度(Parallelism)
在Spark中,并行度(Parallelism)指的是在同一时间内可以同时处理的任务数量。在Spark中,并行度可以通过调整分区(partition)数来控制。一个RDD的分区数决定了该RDD能够被同时处理的任务数量进而影响Spark作业的执行效率。
如果RDD中的分区数量小于集群中的CPU核心数量,则可能无法充分利用集群中的CPU核心数量,则可以导致任务键频繁地发生切换,从而也会降低Spark作业的执行效率。
因此,对于一个RDD,我们需要根据数据的规模、处理复杂度、计算资源等因素来确定合适的分区数,以充分利用集群中的资源,提高Spark作业的执行效率。可以通过repartition()和coalesce()等方法来调整RDD的分区数。
5.3、有向无环图(DAG)

在Spark中,DAG代表着一个有向无环图(Directed Acyclic Graph),它被用来表示Spark中的各种数据转换和动作操作。DAG中的节点代表着数据源(如RDD)、中间转换操作(如map、filter等)和行动操作(如count、collect等),代表着依赖关系。
当Spark应用程序执行时,每个RDD都可以看作一个节点,RDD之间的依赖关系可以看作边。Spark通过构建DAG来进行作业调度,以确定哪些任务需要在哪个节点上执行。Spark通过构建DAG来进行作业调度,以确定哪些任务需要在哪个节点上执行。Spark会将DAG拆分为多个阶段(stage),每个阶段包含一组可以并行执行的任务。每个阶段都有一个特定的数据划分和计算任务,通常涉及一个或多个父RDD到一个或多个子RDD的转换。
在DAG执行过程中,Spark会先执行所有父RDD的所有任务,然后再执行子RDD的任务,以确保数据在计算过程中的正确传递。Spark使用DAG调度器来确定如何拆分为DAG为多个阶段,并将任务分配给可用的执行器节点,以实现高效的任务并行执行。
六、提交流程

6.1、Yarn Client模式
Client模式将用于监控和调度的Driver模块在客户端执行,而不是Yarn中,所以一般用于测试文章来源:https://www.toymoban.com/news/detail-629266.html
- Driver在任务提交的本地机器上运行。
- Dirver启动后会和ResourceManager通讯申请启动ApplicationMaster。
- ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,负责向ResourceManager申请过Executor内存。
- ResouceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Dirver开始执行main函数。
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
6.2、Yarn Cluster模式
Cluster模式将用于监控和调度的Driver模块启动在Yarn集群资源中执行。一般应用于实际生产环境。文章来源地址https://www.toymoban.com/news/detail-629266.html
- 在Yarn Cluster模式下,任务提交后会和ResouceManager通讯申请启动ApplicationMaster。
- 随后ResouceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
- Driver启动后向ResouceManager申请Executor内存,ResouceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程。
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数。
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
到了这里,关于Spark运行架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!