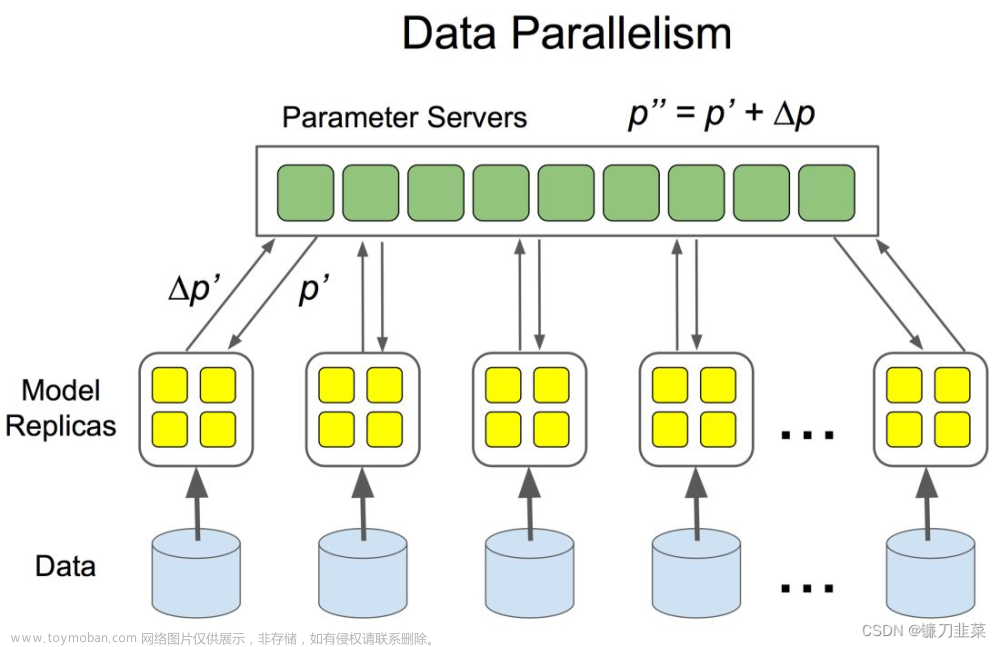
问题
这是为那些将从服务器接收渐变的员工提供的培训功能,在计算权重和偏差后,将更新的渐变发送到服务器。代码如下:
def train():
"""Train CIFAR-10 for a number of steps."""
g1 = tf.Graph()
with g1.as_default():
global_step = tf.contrib.framework.get_or_create_global_step()
# Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate loss.
loss = cifar10.loss(logits, labels)
grads = cifar10.train_part1(loss, global_step)
only_gradients = [g for g,_ in grads]
only_vars = [v for _,v in grads]
placeholder_gradients = []
#with tf.device("/gpu:0"):
for grad_var in grads :
placeholder_gradients.append((tf.placeholder('float', shape=grad_var[0].get_shape()) ,grad_var[1]))
feed_dict = {}
for i,grad_var in enumerate(grads):
feed_dict[placeholder_gradients[i][0]] = np.zeros(placeholder_gradients[i][0].shape)
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
train_op = cifar10.train_part2(global_step,placeholder_gradients)
class _LoggerHook(tf.train.SessionRunHook):
"""Logs loss and runtime."""
def begin(self):
self._step = -1
self._start_time = time.time()
def before_run(self, run_context):
self._step += 1
return tf.train.SessionRunArgs(loss) # Asks for loss value.
def after_run(self, run_context, run_values):
if self._step % FLAGS.log_frequency == 0:
current_time = time.time()
duration = current_time - self._start_time
self._start_time = current_time
loss_value = run_values.results
examples_per_sec = FLAGS.log_frequency * FLAGS.batch_size / duration
sec_per_batch = float(duration / FLAGS.log_frequency)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), self._step, loss_value,
examples_per_sec, sec_per_batch))
with tf.train.MonitoredTrainingSession(
checkpoint_dir=FLAGS.train_dir,
hooks=[tf.train.StopAtStepHook(last_step=FLAGS.max_steps),
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement, gpu_options=gpu_options)) as mon_sess:
global port
while not mon_sess.should_stop():
gradients = mon_sess.run(only_gradients,feed_dict = feed_dict)
# pickling the gradients
send_data = pickle.dumps(gradients,pickle.HIGHEST_PROTOCOL)
# finding size of pickled gradients
to_send_size = len(send_data)
# Sending the size of the gradients first
send_size = pickle.dumps(to_send_size, pickle.HIGHEST_PROTOCOL)
s.sendall(send_size)
# sending the gradients
s.sendall(send_data)
recv_size = safe_recv(17, s)
recv_size = pickle.loads(recv_size)
recv_data = safe_recv(recv_size, s)
gradients2 = pickle.loads(recv_data)
#print("Recevied gradients of size: ", len(recv_data))
feed_dict = {}
for i,grad_var in enumerate(gradients2):
feed_dict[placeholder_gradients[i][0]] = gradients2[i]
res = mon_sess.run(train_op, feed_dict=feed_dict)
但是当我运行这段代码时,工作进程在运行了一些步骤之后神秘地终止(killed)。这是输出:
Connecting to port 16001
Downloading cifar-10-binary.tar.gz 100.0% Successfully downloaded cifar-10-binary.tar.gz 170052171 bytes. WARNING:tensorflow:From
cifar10_train2.py:217: The name tf.gfile.Exists is deprecated. Please
use tf.io.gfile.exists instead.W1206 14:32:34.514134 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:217: The name tf.gfile.Exists is deprecated. Please
use tf.io.gfile.exists instead.WARNING:tensorflow:From cifar10_train2.py:218: The name
tf.gfile.DeleteRecursively is deprecated. Please use
tf.io.gfile.rmtree instead.W1206 14:32:34.515784 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:218: The name tf.gfile.DeleteRecursively is
deprecated. Please use tf.io.gfile.rmtree instead.WARNING:tensorflow:From cifar10_train2.py:219: The name
tf.gfile.MakeDirs is deprecated. Please use tf.io.gfile.makedirs
instead.W1206 14:32:34.521829 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:219: The name tf.gfile.MakeDirs is deprecated.
Please use tf.io.gfile.makedirs instead.WARNING:tensorflow:From cifar10_train2.py:108:
get_or_create_global_step (from
tensorflow.contrib.framework.python.ops.variables) is deprecated and
will be removed in a future version. Instructions for updating: Please
switch to tf.train.get_or_create_global_step W1206 14:32:35.968658
140128687093568 deprecation.py:323] From cifar10_train2.py:108:
get_or_create_global_step (from
tensorflow.contrib.framework.python.ops.variables) is deprecated and
will be removed in a future version. Instructions for updating: Please
switch to tf.train.get_or_create_global_step WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:346:
string_input_producer (from tensorflow.python.training.input) is
deprecated and will be removed in a future version. Instructions for
updating: Queue-based input pipelines have been replaced bytf.data.
Usetf.data.Dataset.from_tensor_slices(string_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs). Ifshuffle=False, omit
the.shuffle(...). W1206 14:32:35.973685 140128687093568
deprecation.py:323] From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:346:
string_input_producer (from tensorflow.python.training.input) is
deprecated and will be removed in a future version. Instructions for
updating: Queue-based input pipelines have been replaced bytf.data.
Usetf.data.Dataset.from_tensor_slices(string_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs). Ifshuffle=False, omit
the.shuffle(...). WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:278:
input_producer (from tensorflow.python.training.input) is deprecated
and will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.from_tensor_slices(input_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs). Ifshuffle=False, omit
the.shuffle(...). W1206 14:32:35.978900 140128687093568
deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:278:
input_producer (from tensorflow.python.training.input) is deprecated
and will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.from_tensor_slices(input_tensor).shuffle(tf.shape(input_tensor, out_type=tf.int64)[0]).repeat(num_epochs). Ifshuffle=False, omit
the.shuffle(...). WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:190:
limit_epochs (from tensorflow.python.training.input) is deprecated and
will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.from_tensors(tensor).repeat(num_epochs). W1206
14:32:35.979965 140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:190:
limit_epochs (from tensorflow.python.training.input) is deprecated and
will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.from_tensors(tensor).repeat(num_epochs).
WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:199:
QueueRunner.init (from
tensorflow.python.training.queue_runner_impl) is deprecated and will
be removed in a future version. Instructions for updating: To
construct input pipelines, use thetf.datamodule. W1206
14:32:35.981818 140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:199:
QueueRunner.init (from
tensorflow.python.training.queue_runner_impl) is deprecated and will
be removed in a future version. Instructions for updating: To
construct input pipelines, use thetf.datamodule.
WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:199:
add_queue_runner (from tensorflow.python.training.queue_runner_impl)
is deprecated and will be removed in a future version. Instructions
for updating: To construct input pipelines, use thetf.datamodule.
W1206 14:32:35.983106 140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/input.py:199:
add_queue_runner (from tensorflow.python.training.queue_runner_impl)
is deprecated and will be removed in a future version. Instructions
for updating: To construct input pipelines, use thetf.datamodule.
WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:79:
FixedLengthRecordReader.init (from tensorflow.python.ops.io_ops)
is deprecated and will be removed in a future version. Instructions
for updating: Queue-based input pipelines have been replaced bytf.data. Usetf.data.FixedLengthRecordDataset. W1206
14:32:35.987178 140128687093568 deprecation.py:323] From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:79:
FixedLengthRecordReader.init (from tensorflow.python.ops.io_ops)
is deprecated and will be removed in a future version. Instructions
for updating: Queue-based input pipelines have been replaced bytf.data. Usetf.data.FixedLengthRecordDataset.
WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:359: The name
tf.random_crop is deprecated. Please use tf.image.random_crop instead.W1206 14:32:36.005118 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:359: The name
tf.random_crop is deprecated. Please use tf.image.random_crop instead.WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/ops/image_ops_impl.py:1514:
div (from tensorflow.python.ops.math_ops) is deprecated and will be
removed in a future version. Instructions for updating: Deprecated in
favor of operator or tf.math.divide. W1206 14:32:36.057567
140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/ops/image_ops_impl.py:1514:
div (from tensorflow.python.ops.math_ops) is deprecated and will be
removed in a future version. Instructions for updating: Deprecated in
favor of operator or tf.math.divide. Filling queue with 20000 CIFAR
images before starting to train. This will take a few minutes.
WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:126:
shuffle_batch (from tensorflow.python.training.input) is deprecated
and will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.shuffle(min_after_dequeue).batch(batch_size). W1206
14:32:36.059510 140128687093568 deprecation.py:323] From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:126:
shuffle_batch (from tensorflow.python.training.input) is deprecated
and will be removed in a future version. Instructions for updating:
Queue-based input pipelines have been replaced bytf.data. Usetf.data.Dataset.shuffle(min_after_dequeue).batch(batch_size).
WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:135: The name
tf.summary.image is deprecated. Please use tf.compat.v1.summary.image
instead.W1206 14:32:36.075527 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10_input.py:135: The name
tf.summary.image is deprecated. Please use tf.compat.v1.summary.image
instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:374: The name
tf.variable_scope is deprecated. Please use
tf.compat.v1.variable_scope instead.W1206 14:32:36.079024 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:374: The name
tf.variable_scope is deprecated. Please use
tf.compat.v1.variable_scope instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:135: calling
TruncatedNormal.init (from tensorflow.python.ops.init_ops) with
dtype is deprecated and will be removed in a future version.
Instructions for updating: Call initializer instance with the dtype
argument instead of passing it to the constructor W1206
14:32:36.079606 140128687093568 deprecation.py:506] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:135: calling
TruncatedNormal.init (from tensorflow.python.ops.init_ops) with
dtype is deprecated and will be removed in a future version.
Instructions for updating: Call initializer instance with the dtype
argument instead of passing it to the constructor
WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:111: The name
tf.get_variable is deprecated. Please use tf.compat.v1.get_variable
instead.W1206 14:32:36.080104 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:111: The name
tf.get_variable is deprecated. Please use tf.compat.v1.get_variable
instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:138: The name
tf.add_to_collection is deprecated. Please use
tf.compat.v1.add_to_collection instead.W1206 14:32:36.089883 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:138: The name
tf.add_to_collection is deprecated. Please use
tf.compat.v1.add_to_collection instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:386: The name
tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.W1206 14:32:36.096186 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:386: The name
tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:572: The name
tf.train.exponential_decay is deprecated. Please use
tf.compat.v1.train.exponential_decay instead.W1206 14:32:36.164064 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:572: The name
tf.train.exponential_decay is deprecated. Please use
tf.compat.v1.train.exponential_decay instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:577: The name
tf.summary.scalar is deprecated. Please use
tf.compat.v1.summary.scalar instead.W1206 14:32:36.170583 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:577: The name
tf.summary.scalar is deprecated. Please use
tf.compat.v1.summary.scalar instead.INFO:tensorflow:Summary name conv1/weight_loss (raw) is illegal; using
conv1/weight_loss__raw_ instead. I1206 14:32:36.224623 140128687093568
summary_op_util.py:66] Summary name conv1/weight_loss (raw) is
illegal; using conv1/weight_loss__raw_ instead.
INFO:tensorflow:Summary name conv2/weight_loss (raw) is illegal; using
conv2/weight_loss__raw_ instead. I1206 14:32:36.230782 140128687093568
summary_op_util.py:66] Summary name conv2/weight_loss (raw) is
illegal; using conv2/weight_loss__raw_ instead.
INFO:tensorflow:Summary name local3/weight_loss (raw) is illegal;
using local3/weight_loss__raw_ instead. I1206 14:32:36.234036
140128687093568 summary_op_util.py:66] Summary name local3/weight_loss
(raw) is illegal; using local3/weight_loss__raw_ instead.
INFO:tensorflow:Summary name local4/weight_loss (raw) is illegal;
using local4/weight_loss__raw_ instead. I1206 14:32:36.236655
140128687093568 summary_op_util.py:66] Summary name local4/weight_loss
(raw) is illegal; using local4/weight_loss__raw_ instead.
INFO:tensorflow:Summary name softmax_linear/weight_loss (raw) is
illegal; using softmax_linear/weight_loss__raw_ instead. I1206
14:32:36.239247 140128687093568 summary_op_util.py:66] Summary name
softmax_linear/weight_loss (raw) is illegal; using
softmax_linear/weight_loss__raw_ instead. INFO:tensorflow:Summary name
cross_entropy (raw) is illegal; using cross_entropy__raw_ instead.
I1206 14:32:36.241847 140128687093568 summary_op_util.py:66] Summary
name cross_entropy (raw) is illegal; using cross_entropy__raw_
instead. INFO:tensorflow:Summary name total_loss (raw) is illegal;
using total_loss__raw_ instead. I1206 14:32:36.244410 140128687093568
summary_op_util.py:66] Summary name total_loss (raw) is illegal; using
total_loss__raw_ instead. WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:584: The name
tf.train.GradientDescentOptimizer is deprecated. Please use
tf.compat.v1.train.GradientDescentOptimizer instead.W1206 14:32:36.247661 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:584: The name
tf.train.GradientDescentOptimizer is deprecated. Please use
tf.compat.v1.train.GradientDescentOptimizer instead.WARNING:tensorflow:From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:609: The name
tf.summary.histogram is deprecated. Please use
tf.compat.v1.summary.histogram instead.W1206 14:32:36.383297 140128687093568 deprecation_wrapper.py:119] From
/home/ubuntu/aws_share/DistNet-master/cifar10.py:609: The name
tf.summary.histogram is deprecated. Please use
tf.compat.v1.summary.histogram instead.WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/moving_averages.py:433:
Variable.initialized_value (from tensorflow.python.ops.variables) is
deprecated and will be removed in a future version. Instructions for
updating: Use Variable.read_value. Variables in 2.X are initialized
automatically both in eager and graph (inside tf.defun) contexts.
W1206 14:32:36.406855 140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/moving_averages.py:433:
Variable.initialized_value (from tensorflow.python.ops.variables) is
deprecated and will be removed in a future version. Instructions for
updating: Use Variable.read_value. Variables in 2.X are initialized
automatically both in eager and graph (inside tf.defun) contexts.
WARNING:tensorflow:From cifar10_train2.py:144: The name
tf.train.SessionRunHook is deprecated. Please use
tf.estimator.SessionRunHook instead.W1206 14:32:36.700819 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:144: The name tf.train.SessionRunHook is deprecated.
Please use tf.estimator.SessionRunHook instead.WARNING:tensorflow:From cifar10_train2.py:171: The name
tf.train.MonitoredTrainingSession is deprecated. Please use
tf.compat.v1.train.MonitoredTrainingSession instead.W1206 14:32:36.701856 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:171: The name tf.train.MonitoredTrainingSession is
deprecated. Please use tf.compat.v1.train.MonitoredTrainingSession
instead.WARNING:tensorflow:From cifar10_train2.py:173: The name
tf.train.StopAtStepHook is deprecated. Please use
tf.estimator.StopAtStepHook instead.W1206 14:32:36.702125 140128687093568 deprecation_wrapper.py:119] From
cifar10_train2.py:173: The name tf.train.StopAtStepHook is deprecated.
Please use tf.estimator.StopAtStepHook instead.INFO:tensorflow:Create CheckpointSaverHook. I1206 14:32:36.702475
140128687093568 basic_session_run_hooks.py:541] Create
CheckpointSaverHook. WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/ops/array_ops.py:1354:
add_dispatch_support..wrapper (from
tensorflow.python.ops.array_ops) is deprecated and will be removed in
a future version. Instructions for updating: Use tf.where in 2.0,
which has the same broadcast rule as np.where W1206 14:32:36.849380
140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/ops/array_ops.py:1354:
add_dispatch_support..wrapper (from
tensorflow.python.ops.array_ops) is deprecated and will be removed in
a future version. Instructions for updating: Use tf.where in 2.0,
which has the same broadcast rule as np.where INFO:tensorflow:Graph
was finalized. I1206 14:32:36.947587 140128687093568
monitored_session.py:240] Graph was finalized. 2019-12-06
14:32:36.948710: I tensorflow/core/platform/cpu_feature_guard.cc:142]
Your CPU supports instructions that this TensorFlow binary was not
compiled to use: AVX2 FMA 2019-12-06 14:32:36.957928: I
tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency:
2400045000 Hz 2019-12-06 14:32:36.958092: I
tensorflow/compiler/xla/service/service.cc:168] XLA service 0x405e200
executing computations on platform Host. Devices: 2019-12-06
14:32:36.958116: I tensorflow/compiler/xla/service/service.cc:175]
StreamExecutor device (0): , 2019-12-06
14:32:37.060010: W
tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time
warning): Not using XLA:CPU for cluster because envvar
TF_XLA_FLAGS=–tf_xla_cpu_global_jit was not set. If you want
XLA:CPU, either set that envvar, or use experimental_jit_scope to
enable XLA:CPU. To confirm that XLA is active, pass
–vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=–xla_hlo_profile.
INFO:tensorflow:Running local_init_op. I1206 14:32:37.153052
140128687093568 session_manager.py:500] Running local_init_op.
INFO:tensorflow:Done running local_init_op. I1206 14:32:37.165080
140128687093568 session_manager.py:502] Done running local_init_op.
WARNING:tensorflow:From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py:875: start_queue_runners (from
tensorflow.python.training.queue_runner_impl) is deprecated and will
be removed in a future version. Instructions for updating: To
construct input pipelines, use thetf.datamodule. W1206
14:32:37.200688 140128687093568 deprecation.py:323] From
/home/ubuntu/geo-distNet/lib/python3.6/site-packages/tensorflow/python/training/monitored_session.py:875: start_queue_runners (from
tensorflow.python.training.queue_runner_impl) is deprecated and will
be removed in a future version. Instructions for updating: To
construct input pipelines, use thetf.datamodule.
INFO:tensorflow:Saving checkpoints for 0 into
/home/ubuntu/cifar10_train/model.ckpt. I1206 14:32:38.378327
140128687093568 basic_session_run_hooks.py:606] Saving checkpoints for
0 into /home/ubuntu/cifar10_train/model.ckpt. 2019-12-06
14:32:42.361013: W tensorflow/core/framework/allocator.cc:107]
Allocation of 18874368 exceeds 10% of system memory. 2019-12-06
14:32:42.897646: W tensorflow/core/framework/allocator.cc:107]
Allocation of 21196800 exceeds 10% of system memory. 2019-12-06
14:32:43.161692: W tensorflow/core/framework/allocator.cc:107]
Allocation of 9437184 exceeds 10% of system memory. 2019-12-06
14:32:43.169073: W tensorflow/core/framework/allocator.cc:107]
Allocation of 18874368 exceeds 10% of system memory. 2019-12-06
14:32:43.231100: W tensorflow/core/framework/allocator.cc:107]
Allocation of 16070400 exceeds 10% of system memory. 2019-12-06
14:32:43.285419: step 0, loss = 4.67 (197.6 examples/sec; 0.648
sec/batch) WARNING:tensorflow:It seems that global step
(tf.train.get_global_step) has not been increased. Current value
(could be stable): 0 vs previous value: 0. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. W1206 14:32:43.988662
140128687093568 basic_session_run_hooks.py:724] It seems that global
step (tf.train.get_global_step) has not been increased. Current value
(could be stable): 0 vs previous value: 0. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. WARNING:tensorflow:It
seems that global step (tf.train.get_global_step) has not been
increased. Current value (could be stable): 1 vs previous value: 1.
You could increase the global step by passing
tf.train.get_global_step() to Optimizer.apply_gradients or
Optimizer.minimize. W1206 14:32:45.315430 140128687093568
basic_session_run_hooks.py:724] It seems that global step
(tf.train.get_global_step) has not been increased. Current value
(could be stable): 1 vs previous value: 1. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. WARNING:tensorflow:It
seems that global step (tf.train.get_global_step) has not been
increased. Current value (could be stable): 2 vs previous value: 2.
You could increase the global step by passing
tf.train.get_global_step() to Optimizer.apply_gradients or
Optimizer.minimize. W1206 14:32:46.506114 140128687093568
basic_session_run_hooks.py:724] It seems that global step
(tf.train.get_global_step) has not been increased. Current value
(could be stable): 2 vs previous value: 2. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. WARNING:tensorflow:It
seems that global step (tf.train.get_global_step) has not been
increased. Current value (could be stable): 3 vs previous value: 3.
You could increase the global step by passing
tf.train.get_global_step() to Optimizer.apply_gradients or
Optimizer.minimize. W1206 14:32:47.667660 140128687093568
basic_session_run_hooks.py:724] It seems that global step
(tf.train.get_global_step) has not been increased. Current value
(could be stable): 3 vs previous value: 3. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. WARNING:tensorflow:It
seems that global step (tf.train.get_global_step) has not been
increased. Current value (could be stable): 4 vs previous value: 4.
You could increase the global step by passing
tf.train.get_global_step() to Optimizer.apply_gradients or
Optimizer.minimize. W1206 14:32:48.857112 140128687093568
basic_session_run_hooks.py:724] It seems that global step
(tf.train.get_global_step) has not been increased. Current value
(could be stable): 4 vs previous value: 4. You could increase the
global step by passing tf.train.get_global_step() to
Optimizer.apply_gradients or Optimizer.minimize. 2019-12-06
14:32:50.199463: step 10, loss = 4.66 (185.1 examples/sec; 0.691
sec/batch) 2019-12-06 14:32:56.430896: step 20, loss = 4.64 (205.5
examples/sec; 0.623 sec/batch) Killed
搜索解决方案并找到以下命令:
dmesg -T| grep -E -i -B100 'killed process'
它显示了导致进程终止并获得以下输出的原因:
[Fri Dec 6 14:33:06 2019] [ pid ] uid tgid total_vm rss
pgtables_bytes swapents oom_score_adj name [Fri Dec 6 14:33:06 2019]
[ 8384] 1000 8384 64817 627 266240 0 0
(sd-pam) [Fri Dec 6 14:33:06 2019] [ 8513] 1000 8513 27163
427 253952 0 0 sshd [Fri Dec 6 14:33:06 2019] [
8519] 1000 8519 5803 437 86016 0 0
bash [Fri Dec 6 14:33:06 2019] [ 8558] 1000 8558 118072 11795
430080 0 0 jupyter-noteboo [Fri Dec 6 14:33:06
2019] [ 8567] 1000 8567 155530 8753 421888 0
0 python3 [Fri Dec 6 14:33:06 2019] [ 8588] 1000 8588 156391
9638 430080 0 0 python3 [Fri Dec 6 14:33:06
2019] [ 8826] 1000 8826 1157 16 49152 0
0 sh [Fri Dec 6 14:33:06 2019] [ 8827] 1000 8827 462846 175833
2416640 0 0 cifar10_train2. [Fri Dec 6 14:33:06
2019] Out of memory: Kill process 8827 (cifar10_train2.) score 700 or
sacrifice child [Fri Dec 6 14:33:06 2019] Killed process 8827
(cifar10_train2.) total-vm:1851384kB, anon-rss:703332kB, file-rss:0kB,
shmem-rss:0kB
这意味着内存不足的原因导致!
解决
[cRPD] Syslog Message: ‘Memory cgroup out of memory: Kill process (rpd) score or sacrifice child’
RPD 在启动容器时将利用比分配给它的内存+交换更多的内存+交换。例如,在以下情况下,生成的容器的内存+交换限制为 2G
docker run --rm -detach --name cRR1 -h cRR1 --privileged -v cRR1-config:/config -v cRR1-Log:/var/log --memory="2g" --memory-swap="2g" -it crpd:20.3X75-D5.5
如下面的 docker 统计信息输出所示,它显示容器正在利用分配给它的所有内存 - 2G
/home/regress# ps aux | grep "/usr/sbin/rpd -N"

任务内存输出显示容器在“22/05/30 09:56:20”上使用了大约 2G 的最大内存 - 这正是内存不足和 RPD 崩溃的时候文章来源:https://www.toymoban.com/news/detail-629368.html
Memory cgroup out of memory” is a message coming from the kernel when it kills something because of a memory cgroup restriction, such as those we place on containers while spinning them.
“内存 cgroup 出内存”是来自内核的消息,当它由于内存 cgroup 限制而杀死某些内容时,例如我们在旋转容器时放置在容器上的那些。
One major thing that could lead to this event is if insufficient memory is allocated to container which is insufficient to handle the route scale.
可能导致此事件的一个主要原因是,如果分配给容器的内存不足,这不足以处理路由规模。
Another factor which could lead to memory contention is a huge route churn which pushes the memory to the edge of extinction.
另一个可能导致内存争用的因素是巨大的路由搅动,它将内存推向灭绝的边缘。
As a reference for RIB/FIB scale vs minimum memory required to support it, refer the documentation on cRPD Resource Requirements.
有关 RIB/FIB 规模与支持它所需的最小内存的参考,请参阅 cRPD 资源要求的文档。文章来源地址https://www.toymoban.com/news/detail-629368.html
到了这里,关于在tensorflow分布式训练过程中突然终止(终止)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!