第16章 分布式内存计算平台Spark习题
16.1 选择题
1、Spark是Hadoop生态( B )组件的替代方案。
A. Hadoop B. MapReduce C. Yarn D.HDFS
2、以下( D )不是Spark的主要组件。
A. Driver B. SparkContext C. ClusterManager D. ResourceManager
3、Spark中的Executor是( A )。
A.执行器 B.主节点 C.从节点 D.上下文
4、下面( D )不是Spark的四大组件之一。
A.Spark Streaming B.Spark MLlib
C.Spark GraphX D.Spark R
5、Scala属于哪种编程语言( C )。
A.汇编语言 B.机器语言
C.函数式编程语言 D.多范式编程语言
6、Spark组件中,SparkContext是应用的( C ),控制应用的生命周期。
A.主节点 B.从节点
C.上下文 D.执行器
7、以下( D )不是Spark的主要组件。
A.DAGScheduler B.TaskScheduler
C.SparkContext D.MultiScheduler
8、Spark组件中,ClusterManager是( B )。
A.从节点 B.主节点
C.执行器 D.上下文
9、关于Spark中的RDD说法不正确的是( B )。
A.是弹性分布式数据集 B.是可读可写分区的集合
C.存在容错机制 D.是Spark中最基本的数据抽象
10、GraphX的BSP计算模型中,一个超步中的内容不包括( C )。
A.计算 B.消息传递
C.缓存 D.整体同步点
16.2 填空题
1、内存计算主要用于处理( 数据密集型 )的计算任务,尤其是数据量极大且需要实时分析处理的应用。
2、Ignite是一个可扩展的、( 容错性好的 )分布式内存计算平台。
3、RDD通过一种名为( 血统 )的容错机制进行错误的时的数据恢复。
4、数据分析栈BDAS包括( Spark SQL )、( Spark Streaming )、 ( Spark GraphX )、 ( MLlib )四个部分。
5、Spark Streaming是建立在Spark上的( 实时计算 )框架,提供了丰富的API、基于内存的高速执行引擎,用户可以结合流式、批处理进行交互式查询应用
16.3 简答题
1、在硬件、软件、应用与体系等方面,内存计算有哪些主要特性?
答:
- 在硬件方面,需要大容量的内存,以便尽量将待处理的数据全部存放在内存中,内存可以是单机内存或分布式内存,且内存要足够大。
- 在软件方面,需要有良好的编程模型和编程接口。
- 在应用方面,主要面向数据密集型应用,数据规模大、对实时处理性能要求高。
- 在体系方面,需要支持并行处理数据。
2、请与MapReduce相比,Spark的优势有哪些?
答:
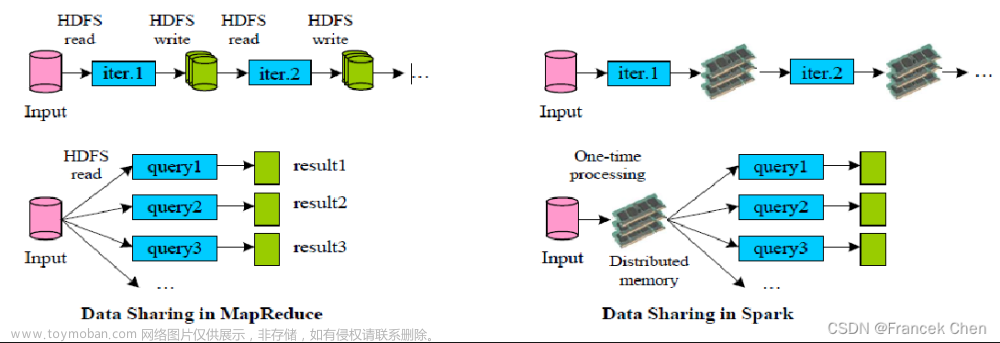
- 中间结果可输出。基于MapReduce的计算模型会将中间结果序列化到磁盘上,而Spark将执行模型抽象为通用的有向无环图,可以将中间结果缓存在内存中。
- 数据格式和内存布局。Spark抽象出分布式内存存储结构RDD,用于进行数据存储。Spark能够控制数据在不同节点上的分区,用户可以自定义分区策略。
- 执行策略。MapReduce在数据Shuffle之前总是花费大量时间来排序,Spark支持基于Hash的分布式聚合,Spark默认Shuffle已经改为基于排序的方式。
- 任务调度的开销。当MapReduce上不同的作业在同一个节点运行时,会各自启动一个Java虚拟机(Java Virtual Machine,JVM); Spark同一节点的所有任务都可以在一个JVM上运行。
- 编程模型。MapReduce仅仅提供了Map和Reduce两个计算原语,需要将数据处理操作转化为Map和Reduce操作,在一定程度增加了编程难度;Spark则提供了丰富的输出处理算子,实现了分布式大数据处理的高层次抽象。
- 统一数据处理。Spark框架为批处理(Spark Core)、交互式(Spark SQL)、流式(Spark Streaming)、机器学习(MLlib)、图计算(GraphX)等计算任务提供一个统一的数据处理平台,各组件间可以共享数据。
3、请描述Pregel计算模型的缺点或局限。
答:
- 在图的划分上,采用的是简单的Hash方式,这样固然能够满足负载均衡,但Hash方式并不能根据图的连通特性进行划分,导致超步之间的消息传递开销影响性能。
- 简单的Checkpoint机制只能将状态恢复到当前超步的几个超步之前,要到当前超步还需要重复计算。BSP计算模型本身有其局限性,整体同步并行对于计算速度快的Worker,长期等待的问题无法解决。
- 由于Pregel目前的计算状态都是常驻内存的,对于规模继续增大的图处理可能会导致内存不足。
4、请简要描述函数式编程中尾递归的含义。
答:
尾递归是递归的一种优化方法。递归的空间效率很低,当递归深度很深时,容易产生栈溢出的情况。尾递归就是将递归语句写在函数的最底部,这样在每次调用尾递归时,就不需要保存当前状态值,可以直接把当前的状态值传递给下次一次调用,然后清空当前的状态。占用的栈空间就是常量值,不会出现栈溢出的情况。
16.4 解答题
1、根据用户手机上网的行为记录,基于 Spark设计程序来分别统计不同设备的用户使用的上行总流量以及下行总流量。其中,数据记录的字段描述如下。
| 序号 |
字段 |
字段类型 |
描述 |
| 0 |
reportTime |
long |
记录报告时间戳 |
| 1 |
deviceId |
String |
手机号码 |
| 2 |
upPackNum |
long |
上行数据包数,单位:个 |
| 3 |
downPackNum |
long |
下行数据包总数,单位:个 |
数据文件的具体内容(一部分)如下:
1454307391161 77e3c9e1811d4fb291d0d9bbd456bb4b 79976 11496
1454315971161 f92ecf8e076d44b89f2d070fb1df7197 95291 89092
1454304331161 3de7d6514f1d4ac790c630fa63d8d0be 57029 50228
1454303131161 dd382d2a20464a74bbb7414e429ae452 20428 93467
1454319991161 bb2956150d6741df875fbcca76ae9e7c 51994 57706
答:
Step1:将SparkConf封装在一个类中。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
public class CommSparkContext {
public static JavaSparkContext getsc(){
SparkConf sparkConf = new SparkConf().setAppName("CommSparkContext").setMaster("local");
return new JavaSparkContext(sparkConf);
}
}
Step2:自定义数据类型LogInfo
import java.io.Serializable;
public class LogInfo implements Serializable {
private long timeStamp;
private long upTraffic;
private long downTraffic;
public long getTimeStamp() {
return timeStamp;
}
public void setTimeStame(long timeStame) {
this.timeStamp = timeStame;
}
public long getUpTraffic() {
return upTraffic;
}
public void setUpTraffic(long upTraffic) {
this.upTraffic = upTraffic;
}
public long getDownTraffic() {
return downTraffic;
}
public void setDownTraffic(long downTraffic) {
this.downTraffic = downTraffic;
}
public LogInfo(){
}
public LogInfo(long timeStame, long upTraffic, long downTraffic) {
this.timeStamp = timeStame;
this.upTraffic = upTraffic;
this.downTraffic = downTraffic;
}
}
Step3:自定义key排序类LogSort
import scala.Serializable;
import scala.math.Ordered;
public class LogSort extends LogInfo implements Ordered<LogSort> , Serializable {
private long timeStamp;
private long upTraffic;
private long downTraffic;
@Override
public long getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(long timeStamp) {
this.timeStamp = timeStamp;
}
@Override
public long getUpTraffic() {
return upTraffic;
}
@Override
public void setUpTraffic(long upTraffic) {
this.upTraffic = upTraffic;
}
@Override
public long getDownTraffic() {
return downTraffic;
}
@Override
public void setDownTraffic(long downTraffic) {
this.downTraffic = downTraffic;
}
public LogSort(){
}
public LogSort(long timeStamp, long upTraffic, long downTraffic) {
this.timeStamp = timeStamp;
this.upTraffic = upTraffic;
this.downTraffic = downTraffic;
}
public int compare(LogSort that) {
int comp = Long.valueOf(this.getUpTraffic()).compareTo(that.getUpTraffic());
if (comp == 0){
comp = Long.valueOf(this.getDownTraffic()).compareTo(that.getDownTraffic());
}
if (comp == 0){
comp = Long.valueOf(this.getTimeStamp()).compareTo(that.getTimeStamp());
}
return comp;
}
public boolean $less(LogSort that) {
return false;
}
public boolean $greater(LogSort that) {
return false;
}
public boolean $less$eq(LogSort that) {
return false;
}
public boolean $greater$eq(LogSort that) {
return false;
}
public int compareTo(LogSort that) {
int comp = Long.valueOf(this.getUpTraffic()).compareTo(that.getUpTraffic());
if (comp == 0){
comp = Long.valueOf(this.getDownTraffic()).compareTo(that.getDownTraffic());
}
if (comp == 0){
comp = Long.valueOf(this.getTimeStamp()).compareTo(that.getTimeStamp());
}
return comp;
}
}
Step4:定义主类
import com.kfk.spark.common.CommSparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.List;
public class LogApp {
public static JavaPairRDD<String,LogInfo> mapToPairValues(JavaRDD<String> rdd){
JavaPairRDD<String,LogInfo> mapToPairRdd = rdd.mapToPair(new PairFunction<String, String, LogInfo>() {
public Tuple2<String, LogInfo> call(String line) throws Exception {
long timeStamp = Long.parseLong(line.split("\t")[0]);
String diviceId = String.valueOf(line.split("\t")[1]);
long upTraffic = Long.parseLong(line.split("\t")[2]);
long downTraffic = Long.parseLong(line.split("\t")[3]);
LogInfo logInfo = new LogInfo(timeStamp,upTraffic,downTraffic);
return new Tuple2<String, LogInfo>(diviceId,logInfo);
}
});
return mapToPairRdd;
}
public static JavaPairRDD<String,LogInfo> reduceByKeyValues(JavaPairRDD<String,LogInfo> mapPairRdd){
JavaPairRDD<String,LogInfo> reduceByKeyRdd = mapPairRdd.reduceByKey(new Function2<LogInfo, LogInfo, LogInfo>() {
public LogInfo call(LogInfo v1, LogInfo v2) throws Exception {
long timeStamp = Math.min(v1.getTimeStamp(), v2.getTimeStamp());
long upTraffic = v1.getUpTraffic() + v2.getUpTraffic();
long downTraffic = v1.getDownTraffic() + v2.getDownTraffic();
LogInfo logInfo = new LogInfo();
logInfo.setTimeStame(timeStamp);
logInfo.setUpTraffic(upTraffic);
logInfo.setDownTraffic(downTraffic);
return logInfo;
}
});
return reduceByKeyRdd;
}
public static JavaPairRDD<LogSort,String> mapToPairSortValues(JavaPairRDD<String,LogInfo> aggregateByKeyRdd){
JavaPairRDD<LogSort,String> mapToPairSortRdd = aggregateByKeyRdd.mapToPair(new PairFunction<Tuple2<String, LogInfo>, LogSort, String>() {
public Tuple2<LogSort, String> call(Tuple2<String, LogInfo> stringLogInfoTuple2) throws Exception {
String diviceId = stringLogInfoTuple2._1;
long timeStamp = stringLogInfoTuple2._2.getTimeStamp();
long upTraffic = stringLogInfoTuple2._2.getUpTraffic();
long downTraffic = stringLogInfoTuple2._2.getDownTraffic();
LogSort logSort = new LogSort(timeStamp,upTraffic,downTraffic);
return new Tuple2<LogSort, String>(logSort,diviceId);
}
});
return mapToPairSortRdd;
}
public static void main(String[] args) {
JavaSparkContext sc = CommSparkContext.getsc();
JavaRDD<String> rdd = sc.textFile("{文件路径}");
// rdd map() -> <diviceId,LogInfo(timeStamp,upTraffic,downTraffic)>
JavaPairRDD<String,LogInfo> mapToPairRdd = mapToPairValues(rdd);
// mapToPairRdd reduceByKey() -> <diviceId,LogInfo(timeStamp,upTraffic,downTraffic)>
JavaPairRDD<String,LogInfo> reduceByKeyRdd = reduceByKeyValues(mapToPairRdd);
// reduceByKeyRdd map() -> <LogSort(timeStamp,upTraffic,downTraffic),diviceId>
JavaPairRDD<LogSort, String> mapToPairSortRdd = mapToPairSortValues(reduceByKeyRdd);
// sortByKey
JavaPairRDD<LogSort,String> sortByKeyValues = mapToPairSortRdd.sortByKey(false);
// TopN
List<Tuple2<LogSort,String>> sortKeyList = sortByKeyValues.take(10);
for (Tuple2<LogSort,String> logSortStringTuple2 : sortKeyList){
System.out.println(logSortStringTuple2._2 + " : " + logSortStringTuple2._1.getUpTraffic() + " : " + logSortStringTuple2._1.getDownTraffic());
}
}
}
Step5:使用maven将程序打包成jar包
Step6:将数据文件上传到hdfs
Step7:运行jar包,进行SPARK_HOME/bin目录下,执行下面的操作
./spark-submit –class LogApp –master spark://master:7077 {jar包位置} {hdfs文件地址} {结果输出的地址}
Step8:查看结果
efde893d9c254e549f740d9613b3421c : 1036288 : 629025
84da30d2697042ca9a6835f6ccec6024 : 930018 : 737453
94055312e11c464d8bb16f21e4d607c6 : 827278 : 897382
c2a24d73d77d4984a1d88ea3330aa4c5 : 826817 : 943297
6e535645436f4926be1ee6e823dfd9d2 : 806761 : 613670
92f78b79738948bea0d27178bbcc5f3a : 761462 : 567899
1cca6591b6aa4033a190154db54a8087 : 750069 : 696854
f92ecf8e076d44b89f2d070fb1df7197 : 740234 : 779789
e6164ce7a908476a94502303328b26e8 : 722636 : 513737文章来源:https://www.toymoban.com/news/detail-629946.html
537ec845bb4b405d9bf13975e4408b41 : 709045 : 642202文章来源地址https://www.toymoban.com/news/detail-629946.html
到了这里,关于云计算与大数据第16章 分布式内存计算平台Spark习题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!