相关
hyper-v安装ubuntu-20-server
hyper-v建立快照
hyper-v快速创建虚拟机-导入导出虚拟机
准备
虚拟机设置
采用hyper-v方式安装ubuntu-20虚拟机和koolshare
| hostname | ip |
|---|---|
| h01 | 192.168.66.20 |
| h02 | 192.168.66.21 |
| h03 | 192.168.66.22 |
静态IP
所有机器都需要按需设置
sudo vim /etc/netplan/00-installer-config.yaml
sudo netplan apply
00-installer-config.yaml
addresses中192.168.66.10是机器的IP地址
gateway4是koolshare的地址
network:
ethernets:
eth0:
dhcp4: no
addresses: [192.168.66.20/24]
optional: true
gateway4: 192.168.66.1
nameservers:
addresses: [223.5.5.5,223.6.6.6]
version: 2
更改hostname
hostnamectl set-hostname h01
hostnamectl set-hostname h02
hostnamectl set-hostname h03
配置hosts
每台机器都要操作
sudo vim /etc/hosts
# 注意,注释掉或更好名称
127.0.0.1 h01/h02/h03
# 添加一下内容
192.168.66.20 h01
192.168.66.21 h02
192.168.66.22 h03
新增mybigdata用户
每台机器都要操作
# 添加mybigdata用户 (用户名)》密码是必须设置的,其它可选
sudo adduser mybigdata
# 用户加入sudo组,a(append),G(不要将用户从其它组移除)
sudo usermod -aG sudo mybigdata
# 补充,删除用户和文件
# sudo deluser --remove-home mybigdata
ssh登录
ssh -p 22 mybigdata@192.168.66.20
ssh -p 22 mybigdata@192.168.66.21
ssh -p 22 mybigdata@192.168.66.22
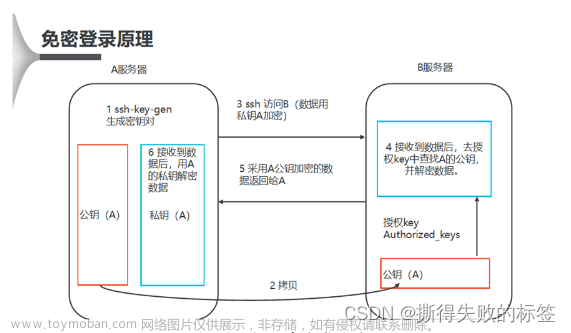
免密登录
每台机器都需要设置
# 秘钥生成
ssh-keygen -t rsa
# 秘钥拷贝
ssh-copy-id h01
ssh-copy-id h02
ssh-copy-id h03
# 测试
ssh h01
ssh h02
ssh h03
rsync分发
在h01执行
cd /home/mybigdata
# 创建xsync 分发脚本
vim xsync
# xsync增加可执行权限
chmod +x xsync
# 运行示例
# xsync test.txt
xsync 分发脚本
#!/bin/bash
pcount=$#
if [ $pcount -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
for host in h01 h02 h03
do
echo ====$host====
for file in $@
do
if [ -e $file ]
then
pdir=$(cd -P $(dirname $file); pwd)
echo pdir=$pdir
fname=$(basename $file)
echo fname=$fname
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $USER@$host:$pdir
else
echo $file does not exists!
fi
done
done
jdk
在h01执行
cd /home/mybigdata
# windows上传linux h01
scp -P 22 -r D:\00garbage\jdk-8u321-linux-x64.tar.gz mybigdata@192.168.66.20:/home/mybigdata/
# 解压
tar -zxvf jdk-8u321-linux-x64.tar.gz
# 配置环境变量
vim .bashrc
# 刷新环境变量
source .bashrc
# 测试
java -version
javac -help
.bashrc
#JAVA_HOME
export JAVA_HOME=/home/mybigdata/jdk1.8.0_321
export JRE_HOME=/home/mybigdata/jdk1.8.0_321/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
安装hadoop
在h01操作
cd /home/mybigdata
# windows上传linux h01
scp -P 22 -r D:\00garbage\hadoop-3.1.3.tar.gz mybigdata@192.168.66.20:/home/mybigdata/
# 解压
tar -zxvf hadoop-3.1.3.tar.gz
# 配置环境变量
vim .bashrc
# 刷新环境变量
source .bashrc
# 测试
scp -P 22 -r D:\00garbage\hadoop-mapreduce-examples-3.1.3.jar mybigdata@192.168.66.20:/home/mybigdata/
mkdir input
vim input/word.txt
hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount input/ ./output
cd output
vim part-r-00000
.bashrc
#HADOOP_HOME
export HADOOP_HOME=/home/mybigdata/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
配置hadoop集群
| 组件 | 地址 | 介绍 |
|---|---|---|
| hdfs namenode | hdfs://h01:9000 | |
| hdfs secondary namenode | h02:50090 | |
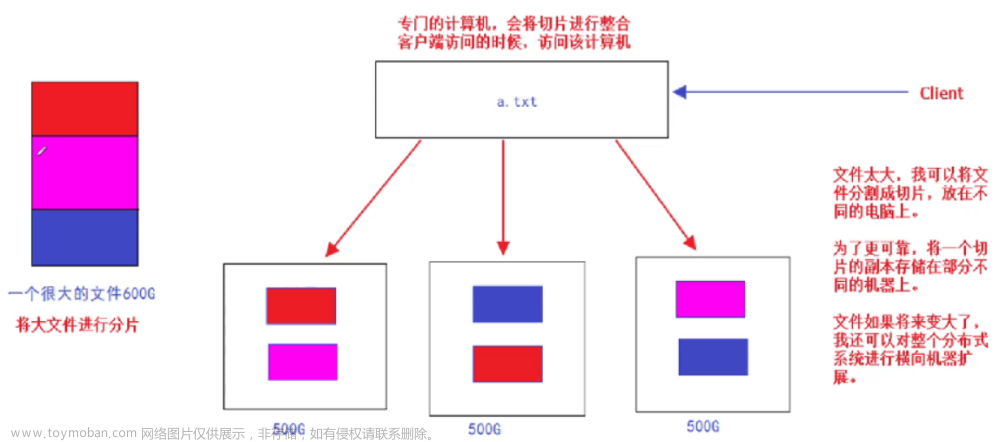
| hdfs datanode | 所有结点都有 | |
| mapred/yarn JobHistoryServer | u01 | |
| yarn resourcemanager | h01 | |
| yarn nodemanager | 所有结点都有 |
| 配置文件 | 地址 | 介绍 |
|---|---|---|
| core-site.xml/fs.defaultFS | hdfs://h01:9000 | namenode 地址,client与namenode通信地址 |
| hdfs-site.xml/dfs.namenode.secondary.http-address | h02:50090 | secondary namenode 地址 |
| yarn-site.xml/yarn.resourcemanager.hostname | h01 | yarn resourcemanager 地址 |
| yarn-site.xml/yarn.log.server.url | http://h01:19888/jobhistory/logs | yarn日志服务端地址 |
| mapred-site.xml/mapreduce.jobhistory.address | h01:10020 | mapreduce jobhistory 地址 |
| mapred-site.xml/mapreduce.jobhistory.webapp.address | h01:19888 | mapreduce jobhistory web端地址 |
现在h01执行,再分发
cd /home/mybigdata/hadoop-3.1.3/etc/hadoop/
vim hadoop-env.sh
vim workers
# hdfs namenode
vim core-site.xml
# hdfs secondary namenode
vim hdfs-site.xml
# mapred
vim mapred-site.xml
# yarn resourcemanager
vim yarn-site.xml
hadoop-env.sh
添加
export JAVA_HOME=/home/mybigdata/jdk1.8.0_321
workers
删除localhost
添加
h01
h02
h03
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!--namenode 地址,client与namenode通信地址-->
<value>hdfs://h01:9000</value>
</property>
<!--Hadoop的临时目录,默认/tem/hadoop-${user.name}-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mybigdata/hadoop-3.1.3/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<!--副本数量-->
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>h02:50090</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!--指定MapReduce运行时的调度框架,这里指定在Yarn上,默认在local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--mapreduce jobhistory 地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>h01:10020</value>
</property>
<!--mapreduce jobhistory web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>h01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!--ResourceManager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--yarn日志服务端地址,mapred-site.xml已配置-->
<property>
<name>yarn.log.server.url</name>
<value>http://h01:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
</configuration>
分发
在h01执行
# 环境变量 .bashrc
./xsync .bashrc
# jdk
./xsync jdk1.8.0_321
# hadoop
./xsync hadoop-3.1.3
# 在每个虚拟机上执行,激活环境变量
source .bashrc
脚本
在h01执行
# 启动 停止脚本;hse.sh start/stop
vim hse
# 修改权限
chmod +x hse
# 每个虚拟机执行,jps软连接
ln -s -f /home/mybigdata/jdk1.8.0_321/bin/jps /usr/bin/jps
# hjps
vim hjps
# 修改权限
chmod +x hjps
hse.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "请输入start/stop"
exit ;
fi
case $1 in
"start")
echo "===启动hadoop集群 ==="
echo "---启动hdfs---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/start-dfs.sh"
echo "---启动yarn---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/start-yarn.sh"
echo " ---启动historyserver---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo "===关闭hadoop集群==="
echo "---关闭historyserver---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo "---关闭yarn---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/stop-yarn.sh"
#若yarn在u02机器上则 ssh h02
echo "---关闭hdfs---"
ssh h01 "/home/mybigdata/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "请输入start/stop"
;;
esac
hjps
#!/bin/bash
for host in h01 h02 h03
do
echo ===$host===
ssh $host jps
done
windows配置
hosts 位置 C:\windows\system32\drivers\etc\
192.168.66.20 h01
192.168.66.21 h02
192.168.66.22 h03
测试
在h01执行文章来源:https://www.toymoban.com/news/detail-630616.html
cd /home/mybigdata
# namenode 格式化
hdfs namenode -format
# 启动
./hse start
# 检查jps
./hjps
# 执行
hadoop dfs -mkdir /wordin
vim word.txt
hadoop dfs -moveFromLocal ./word.txt /wordin
hadoop jar ./hadoop-mapreduce-examples-3.1.3.jar wordcount /wordin /wordout
# hdfs web地址
http://u01:9870
# yarn web地址
http://u01:8088
./hjps 执行结果文章来源地址https://www.toymoban.com/news/detail-630616.html
到了这里,关于hadoop 3.1.3集群搭建 ubuntu20的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!