论文: 《AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning》
github: https://github.com/guoyww/animatediff/
1. 摘要
随着文生图模型Stable Diffusion及个性化finetune方法:DreamBooth、LoRA发展,人们可以用较低成本生成自己所需的高质量图像,这导致对于图像动画的需求越来越多。本文作者提出一种框架,可将现有个性化文生图模型所生成图片运动起来。该方法内核为在模型中插入一个运动建模模块,训练后用于蒸馏合理的运动先验。一旦训练完成,所有基于同一个文生图模型的个性化版本都可变为文本驱动模型。作者在动画、真实图上验证,AnimateDiff生成视频比较平滑,同时保留域特性及输出多样性。
2. 引言
作者提出的AnimateDiff,可对于任意个性化文生图模型生成动图,收集每个个性化域对应视频进行finetune是不方便的,因此作者设计运动建模模块,在大规模视频上进行finetune,学习到运动先验。
3. 算法
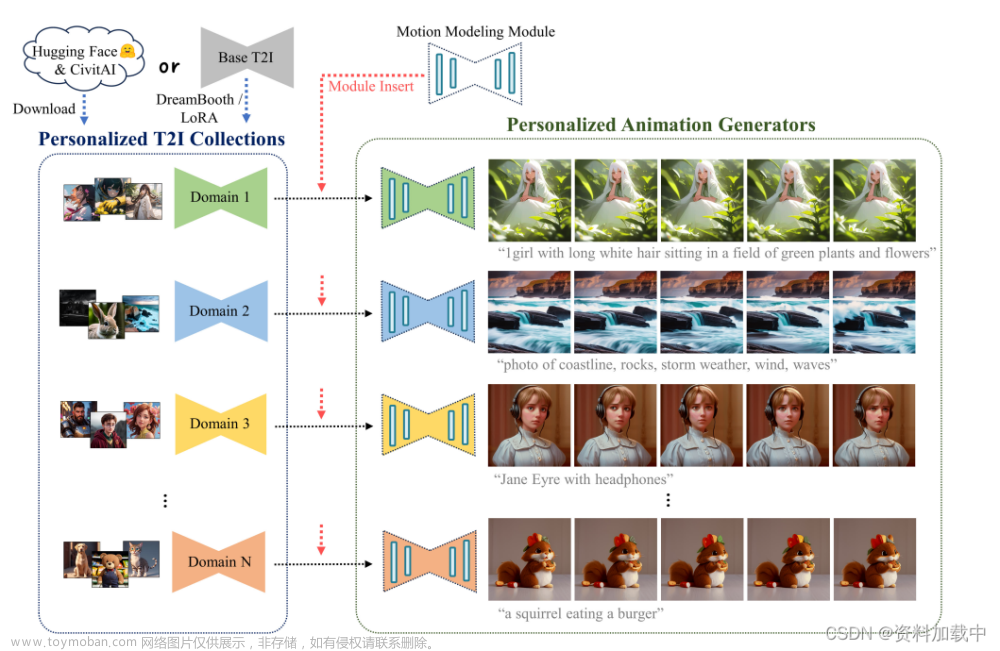
AnimateDiff结构如图2所示,
3.1 Preliminaries
作者使用通用文生图模型SD,对于个性化图像生成领域,如果采集目标域数据进行finetune模型,成本大,DreamBooth通过设置稀有字符串作为目标域标志,同时增加原始模型生成图像进行训练,减少信息丢失;LoRA训练模型参数差值∆W,为降低计算量,作者将∆W解耦为两个低秩矩阵,只有transformer block中映射矩阵参与finetune。
3.2. Personalized Animation
Personalized Animation定义为:给出个性化文生图模型,比如DreamBooth或LoRA,通过少量训练成本或不训练即可驱动生成器,保留原始域信息及质量。
为达到上述目的,常规方案是扩展模型增加关注时间的结构,通过大量视频数据学习合理运动先验,但是个性化视频收集成本大,有限视频将导致源域信息丢失。
对此,作者选择训练泛化性运动建模模块,推理时将其插入文生图模型,作者实验验证发现,该模块可用于任何基于同一基础模型的文生图模型,因为几乎未改变基础模型特征空间,ControlNet也曾证明过。
3.3 Motion Modeling Module
网络扩展:
原始SD仅能用于处理图像数据,若要处理5D视频张量(batch
×
\times
×channels
×
\times
×frames
×
\times
×height
×
\times
×width),则需要扩展网络,作者将原模型中每个2D卷积及attention层转换到仅关注空间的伪3D层,将frame维度合并到batch维度。新引入的运动模块可在每个batch中跨帧执行,使得生成视频跨帧平滑,内容一致,细节如图3所示。
运动建模模块设计:
该模块主要用于高效交换跨帧信息,作者发现普通的时空transformer足够建模运动先验。其由几个self-attention在时空维执行,特行图z的空间维度height、width reshape到batch维度,得到长度frames的
b
a
t
c
h
∗
h
e
i
g
h
t
∗
w
i
d
t
h
batch*height*width
batch∗height∗width的序列,该映射特征经过几个self-attention block,如式4,
使得该模块可以捕获帧序列同一位置之间时空依赖性;为扩大感受野,作者在U型扩散网路每个分辨率层级引入该模块;此外,self-attention中增加正弦位置编码,使得网络关注当前帧时空位置。
训练目标函数:
训练过程:采样视频数据,通过预训练编码器,编码到隐空间,经过运动模块扩展的扩散网络,将噪声隐向量及对应文本prompt作为输入,预测增加到隐向量上的噪声,如式5,
4. 实验
如图4,作者展示不同模型效果;
图5,作者比较AnimateDiff与Text2Video-Zero,帧与帧之间内容一致性,Text2Video-Zero内容缺少细粒度一致性。
消融实验:
表2作者比较3种不同扩散机制,可视化结果如图6,Schedule B达到两者均衡。
5.限制
作者发现个性化文生图模型数据域为非逼真图片,更容易生成失败,如图7,有明显伪影,不能生成合理运动,归因于训练视频与个性化模型之间存在较大分布差异。可通过收集目标域视频finetune解决。 文章来源:https://www.toymoban.com/news/detail-630781.html
文章来源:https://www.toymoban.com/news/detail-630781.html
6. 结论
作者提出AnimateDiff,可将大多数个性化文生图模型进行视频生成,基于简单设计的运动建模模块,在大量视频数据学习运动先验,插入个性化文生图模型用于生成自然合理的目标域动图。文章来源地址https://www.toymoban.com/news/detail-630781.html
到了这里,关于AnimateDiff论文解读-基于Stable Diffusion文生图模型生成动画的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[Stable Diffusion]AnimateDiff :最稳定的文本生成视频插件](https://imgs.yssmx.com/Uploads/2024/02/764342-1.png)

![[Stable Diffusion进阶篇]AnimateDiff :最稳定的文本生成视频插件](https://imgs.yssmx.com/Uploads/2024/02/763585-1.png)




