背景
微调 mask-rcnn 代码,用的是 torchvision.models.detection.maskrcnn_resnet50_fpn 代码,根据该代码的注释,输入应该是:images, targets=None(List[Tensor], Optional[List[Dict[str, Tensor]]]) -> Tuple[Dict[str, Tensor], List[Dict[str, Tensor]]]
所以我写的 dataset 是这样的:
def _load_ann(self):
transformed_anns = {'boxes': boxes : List[List],
'labels': categories: List[int],
'masks': masks: List[str]}
self.anns[filename] = transformed_anns
def __getitem__(self, item) -> (Tensor, Optional[Dict[str, Tensor]]):
img_name = self.img_list[item]
img = cv2.imread(os.path.join(self.root_path, self.split, img_name))
if self.split == 'train':
return img, self.anns[img_name]
大概思路是:先把所有的标注信息读入内存,然后按照 img_name 把标注信息(也就是 target )取出来。
这里有个令人纠结的地方:__get_item__ 返回的到底是什么格式的数据?一开始我是直接把 boxes labels masks 都直接写成 tensor 返回,但是一次性把所有的 masks 都读到内存,太大了。再加上看了这个 pytorch内存泄露-dataloader - 知乎 ,这里建议 dataset 的 __get_item__ 返回的都是 python 的基础数据类型,所以我就改成了上面的样子。其实返回什么类型的都行,只要在 dataloader 的 collate_fn 方法里面都转成可以送入模型的数据形式就行了。
因为 dataset 是上面的写法,所以对应的 collate_fn 写法是:
def collate_fn(datas: List[Tuple[Tensor, Dict]]):
imgs = []
targets = []
for data in datas:
img, target = data
imgs.append(transforms.ToTensor()(img))
target['boxes'] = torch.tensor(target['boxes'], dtype=torch.float)
target['labels'] = torch.tensor(target['labels'], dtype=torch.int64)
masks = target['masks']
masks = [cv2.imread(mask, 0) for mask in masks]
masks = np.stack(masks, axis=0)
masks = masks / 255
masks = masks.astype(np.uint8)
target['masks'] = torch.from_numpy(masks)
targets.append(target)
return imgs, targets
错误排查及解决方法
把所有的数据送入 model 的代码都注释掉,只保留如下代码:
for e in range(epoch):
for i, (imgs, targets) in enumerate(train_dataloader):
imgs = [img.to(device) for img in imgs]
targets = [_to_device(target, device) for target in targets]
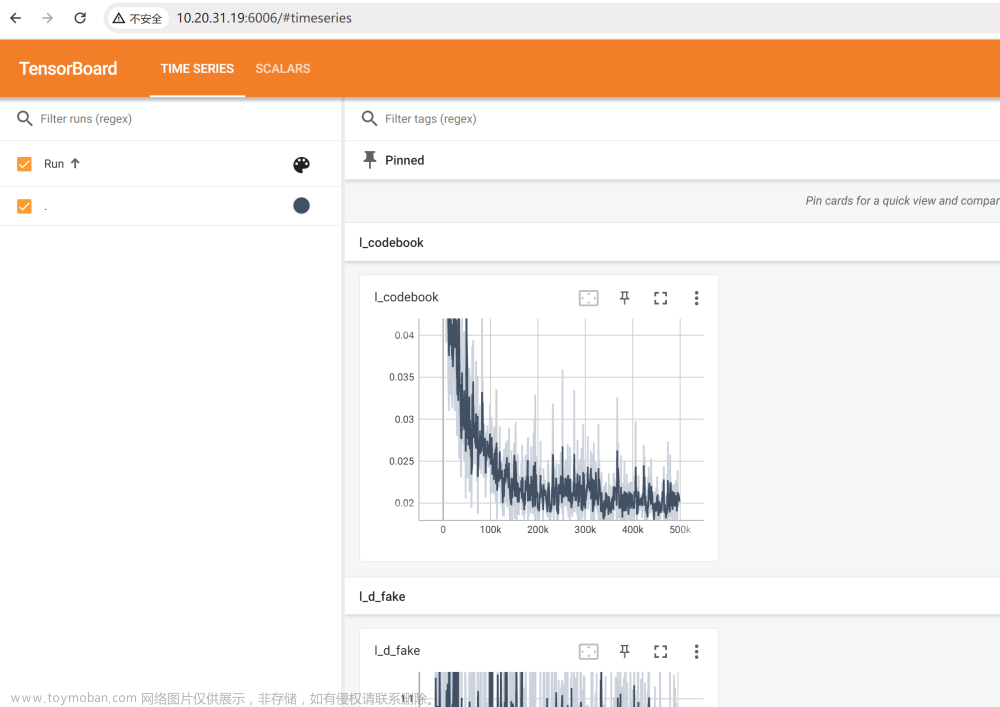
用 watch -n 1 nvidia-smi 监控显存占用,发现一直在涨。毫无疑问肯定是 dataloader 导致的显存泄露 😭
然后就是排查,到底是谁?是谁想害朕??
排查方法是:分别注释掉 imgs / boxes / labels / masks ,观察注释掉谁的时候不会显存泄露。
发现,是 masks 导致的内存泄露。
但是这很怪啊,明明 masks 和 imgs 是一样的数据类型,为什么前者会显存泄露,但是后者不会?于是我把 masks 单独拿出来,像 imgs 一样放在 list 里面,不会内存泄露。但是一旦把 imgs 嵌套放在 targets 这个 dict 里面,就会显存泄露 orz
于是,既然是 masks 没有释放,所以我加一句:
for e in range(epoch):
for i, (imgs, targets) in enumerate(train_dataloader):
imgs = [img.to(device) for img in imgs]
targets = [_to_device(target, device) for target in targets]
# ... 传入模型的计算
for target in targets:
del target['masks']
但是没用,还是泄露。然后查了 pytorch 怎么释放 tensor,发现要主动调用 torch.cuda.empty_cache() 才会释放,所以我又加了一句:
for e in range(epoch):
for i, (imgs, targets) in enumerate(train_dataloader):
imgs = [img.to(device) for img in imgs]
targets = [_to_device(target, device) for target in targets]
# ... 传入模型的计算
for target in targets:
del target['masks']
torch.cuda.empty_cache()
这回没有显存泄露了。
但是出现了新的问题,在 epoch=2 的时候报错 targets 没有 masks 这个 key;然后我 debug 发现,由 dataloader 取到的数据 label 和 boxes 在 collate_fn 之前就已经是 tensor 状态了,再往前倒,发现 dataset.anns 里面的数据居然被改了!这实在是太荒谬了。
所以我把 __get_item 改成:文章来源:https://www.toymoban.com/news/detail-630932.html
def __getitem__(self, item) -> (Tensor, Optional[Dict[str, Tensor]]):
img_name = self.img_list[item]
img = cv2.imread(os.path.join(self.root_path, self.split, img_name))
if self.split == 'train':
return img, deepcopy(self.anns[img_name])
这样就没问题了文章来源地址https://www.toymoban.com/news/detail-630932.html
总结
- 查找内存泄露/显存泄露的位置:
- 把数据送入模型的代码全部注释掉,观察显存是否上涨;上涨说明内存泄露出现在
dataloader(出现在非 dataloader 地方的最常见的显存泄露原因是,loss打印/统计的时候没有写loss.item()) - 把不同的 data 组成部分注释掉,观察具体是哪个 data 导致的内存泄露
- 把数据送入模型的代码全部注释掉,观察显存是否上涨;上涨说明内存泄露出现在
- pytorch 释放内存的方法:把 tensor 读到 gpu 就会有显存占用,一般可以自动释放,但是显存泄露的时候就没法释放。找到没有及时释放的代码位置,然后首先
del tensor标记删除,随后需要调用torch.cuda.empty_cache()才能真正释放。 - dataset 的
__get_item__方法注意,如果要返回内部维护的 list 类型的数据的话,不要直接返回该数据切片,而是返回deepcopy(), 防止内部维护的数据被外部修改
到了这里,关于pytorch 训练过程内存泄露/显存泄露debug记录:dataloader和dataset导致的泄露的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!