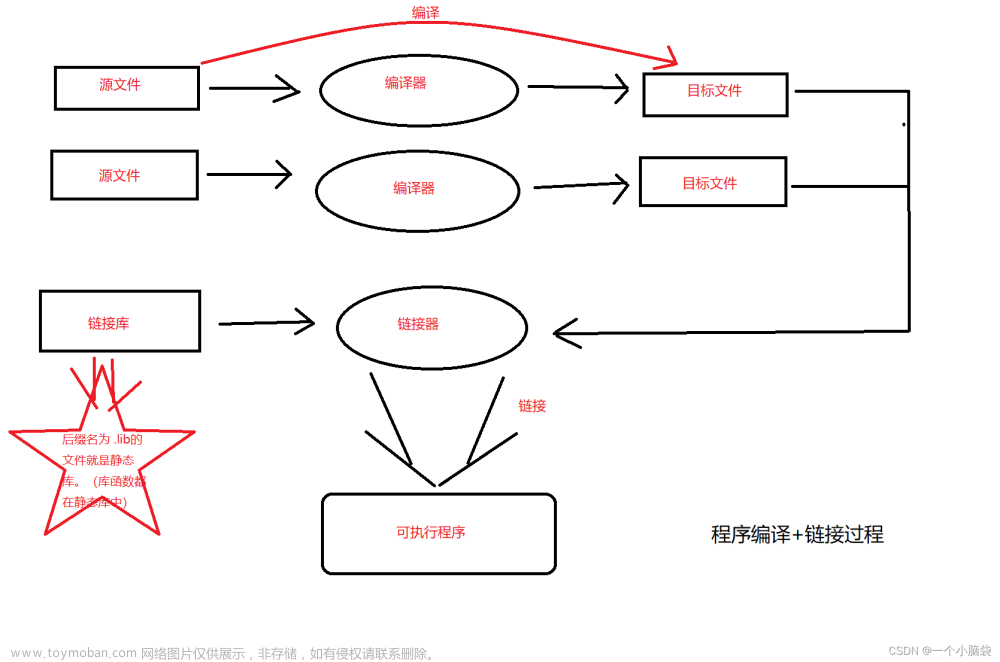
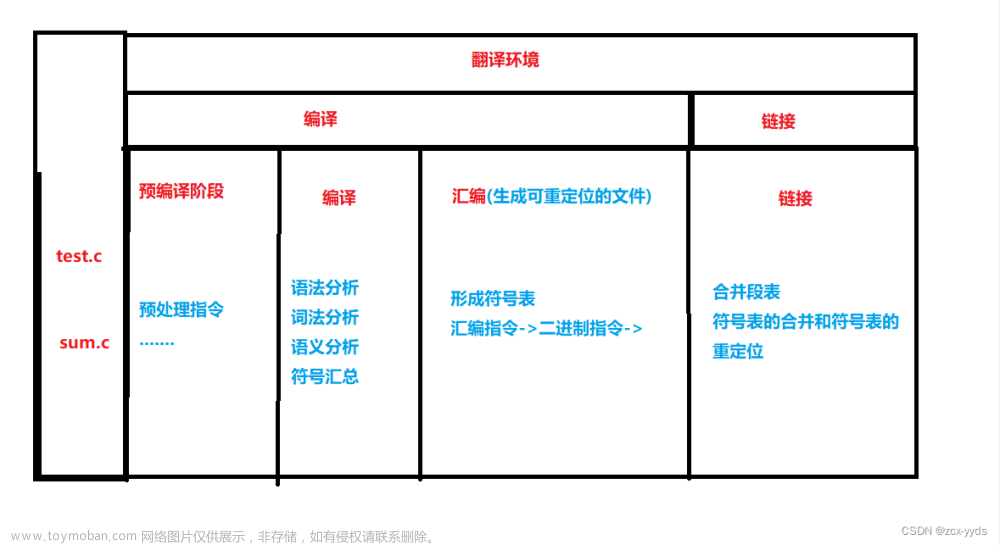
欢迎阅读新一期的c语言学习模块————预处理
✒️个人主页:-_Joker_-
🏷️专栏:C语言
📜代码仓库:c_code
🌹🌹欢迎大佬们的阅读和三连关注,顺着评论回访🌹🌹
文章目录
- 什么是预处理
- 宏定义#define
- #undef
- #include
- 条件编译
- #error
- #pragma
什么是预处理
预编译又称为预处理 , 是做些代码文本的替换工作。
处理以# 开头的指令 , 比如拷贝 #include 包含的文件代码,#define 宏定义的替换 , 条件编译等,就是为编译做的预备工作的阶段。
主要处理#开始的预编译指令,预编译指令指示了在程序正式编译前就由编译器进行的操作,可以放在程序中的任何位置。
C 编译系统在对程序进行通常的编译之前,首先进行预处理。
c 提供的预处理功能主要有以下三种:
1 )宏定义
2 )文件包含
3 )条件编译
何时需要预编译:
总是使用不经常改动的大型代码体。
程序由多个模块组成,所有模块都使用一组标准的包含文件和相同的编译选项。在这种情况下,可以将所有包含文件预编译为一个“预编译头”
在c语言中有如下预处理指令
下面介绍几个常用的预处理指令
一. 宏定义(#define)
常用的宏定义有以下几种:
①宏常量
我们最常使用到的#define的用法就是用#define来定义一个符号常量,而要修改时,只需修改#define这条语句就行了,不必每处代码都修改
例如
#include"stdio.h"
#define A 10
int main()
{
printf("A = %d" , A);//在预处理时,A会被转化为 10
return 0;
}在预处理时,A会被转变为10
结果如下

②宏语句
宏定义除了可以定义一些常量之外,我们还可以用来定义一些语句
例如
#include <stdio.h>
#define Print(str) printf("%s", str)
int main()
{
Print("这是一个宏定义的输出语句");//在程序预处理时会变为printf("%s", str);
return 0;
}在预处理时,Print会被转变为printf("%s", str);
结果如下

③宏函数
宏除了可以定义常量和语句以外,也可以用来定义一些函数
例如
#include <stdio.h>
#define ADD(x, y) x + y
int main()
{
printf("%d", ADD(10, 20));
return 0;
}在预处理时,编译器会将10和20带入宏定义的ADD(x, y) ,并且将ADD(x, y)转变为 x + y,所以原语句 <==>printf("%d", 10 + 20);
结果如下

宏定义不止可以定义常量,语句,函数,它还可以用来实现递归调用等,宏定义类似于函数,但是又和函数不同,宏定义在预处理时需要编译器进行预处理,每一次对宏定义的函数/语句/常量的引用都需要进行一次转化。在定义结构较简单,使用次数较少的函数时,宏定义的预处理时间可以忽略不计,宏定义的效率会比函数要更高,但是如果多次调用宏定义函数的话,系统会不断对宏定义的语句进行处理,从而消耗很多时间,这种情况下的效率是要低于函数的,所以宏定义和函数是各有春秋,可以根据使用需求的不同来使用不同的方法。
二、#undef
这个预处理命令也就是undefine的意思,即撤销宏定义。也就是说宏定义的生命周期从#define开始到#undef结束。
在实际应用中可以按照以下方式使用
1. 防止宏定义冲突
在一个程序块中用完宏定义后,为防止后面标识符冲突需要取消其宏定义。
#include <stdio.h>
int main()
{
#define MAX 200
printf("MAX = %d\n", MAX);
#undef MAX
int MAX = 10;
printf("MAX = %d\n", MAX);
return 0;
}在一个程序段中使用完宏定义后立即将其取消,防止在后面程序段中用到同样的名字而产生冲突。
2. 增强代码可读性
在同一个头文件中定义结构类型相似的对象,根据宏定义不同获取不同的对象,主要用于增强代码的可读性。
#include <stdio.h>
#define MING
#include "student.h"
#undef MING
#define HONG
#include "student.h"
#undef HONG
int main()
{
printf("Xiao Ming's age is %d.\n", MING_AGE);
printf("Xiao Hong's age is %d.\n", HONG_AGE);
return 0;
}
在一个头文件里定义的两个对象与分别在两个头文件里定义效果相同,但如果将相似的对象只用一个头文件申明,可以增强源代码的可读性。
三、#include
这是我们最常见的词语了。在编译一个程序的时候,首先第一句话就是#include <stdio.h>啦。它同样也非常重要,是将多个源文件连接成一个源文件进行编译,结果就生成一个目标文件(obj)。常见有两种形式:
1.include <xxx.h>
用尖括号括起来的头文件一般都是系统自带的,表示系统将在指定的路径进行寻找。
2.include "xxx.h"
双引号一般则用于我们自己编写的头文件,系统也会优先在当前目录中查找。如果找不到指定文件名的文件就会和形式1一样在指定的路径进行寻找。
四、条件编译
平常写代码过程中,我们为了实现分支结构会经常使用if else结构,在预处理同样也有类似的功能,即条件编译。我们可以按照不同的条件去编译不同的部分,这对程序的移植和调试有着巨大的帮助。条件编译主要有以下两种形式。
1.#ifdef 标识符1 && #ifndef 标识符2
//code1
#else
//code2
#endif
这一段就是经典的条件编译。如果定义了标识符1(或如果没有定义(ifndef)标识符2),执行代码段code1;否则执行code2.
要注意的是#ifdef或#ifndef需要和#endif对应。
2.#if 常量表达式
//code1
#else
//code2
#endif
这段则无限接近我们日常使用的if else了。同样要注意endif。
除此之外还有一个#elif,即是elseif,形成if else_if 阶梯状语句,可以进行多种编译选择。
五、#error
#error的作用是用于提示报错信息,当程序运行到#error时会生成一个错译信息,这个错误信息是由系统已经定义好了的,它会根据错误类型生成一个提示并停止程序。这里就不作过多介绍,如果想要了解可以通过链接进行了解--->#error 指令 (C/C++)
六、#pragma
#pragma是以上预处理指令中较为复杂的一个,同时也是功能较为强大的一个,它的用法如下:
1.#pragma once
这是一个比较常用于自定义的函数头文件中的预处理指令,通常在头文件的最开始处加上这句话,就可以避免头文件的重复引用(include)。它的作用就是保证每个头文件只编译一次,再加入同名的头文件也没有关系(反正也不编译,且不会报错)。
2.#pragma warning
此指令用于和warning有关的操作(即非致命编程错误的警告)。
具体示例:
#pragma warning (disable:4707) //屏蔽4707警告
#pragma warning (once:4706) //只显示一次4706警告
#pragma warning (error:164) //将164号警告当作一个错误。
也可以三合一写成:#pragma warning (disable:4707;once:4706;e
编译器将 4000 添加到 0 和 999 之间的任何警告编号。具体用法及详细使用方法可以参照警告 pragma
3.#pragma pack
这个预处理指令设计到了内存对齐相关的问题,它的作用是设定最小对齐数,它可以用来更改结构体的对齐方式,如果不清楚内存对齐的小伙伴可以参考【C语言学习——————————结构体对齐案例解析】
如果对这条预处理指令的用法及注意事项有兴趣的小伙伴,可以参考pack pragma
#pragma的用法不止以上三种,它还有其他的使用方法,这里就不一一介绍了,只介绍常用的相关用法。
以上带来的就是预处理的相关介绍。文章来源:https://www.toymoban.com/news/detail-630935.html
文章来源地址https://www.toymoban.com/news/detail-630935.html
到了这里,关于【C语言学习——————预处理3000字讲解】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!