【2023 华数杯全国大学生数学建模竞赛】 C题 母亲身心健康对婴儿成长的影响

1 题目
母亲是婴儿生命中最重要的人之一,她不仅为婴儿提供营养物质和身体保护, 还为婴儿提供情感支持和安全感。母亲心理健康状态的不良状况,如抑郁、焦虑、压力等,可能会对婴儿的认知、情感、社会行为等方面产生负面影响。压力过大的母亲可能会对婴儿的生理和心理发展产生负面影响,例如影响其睡眠等方面。
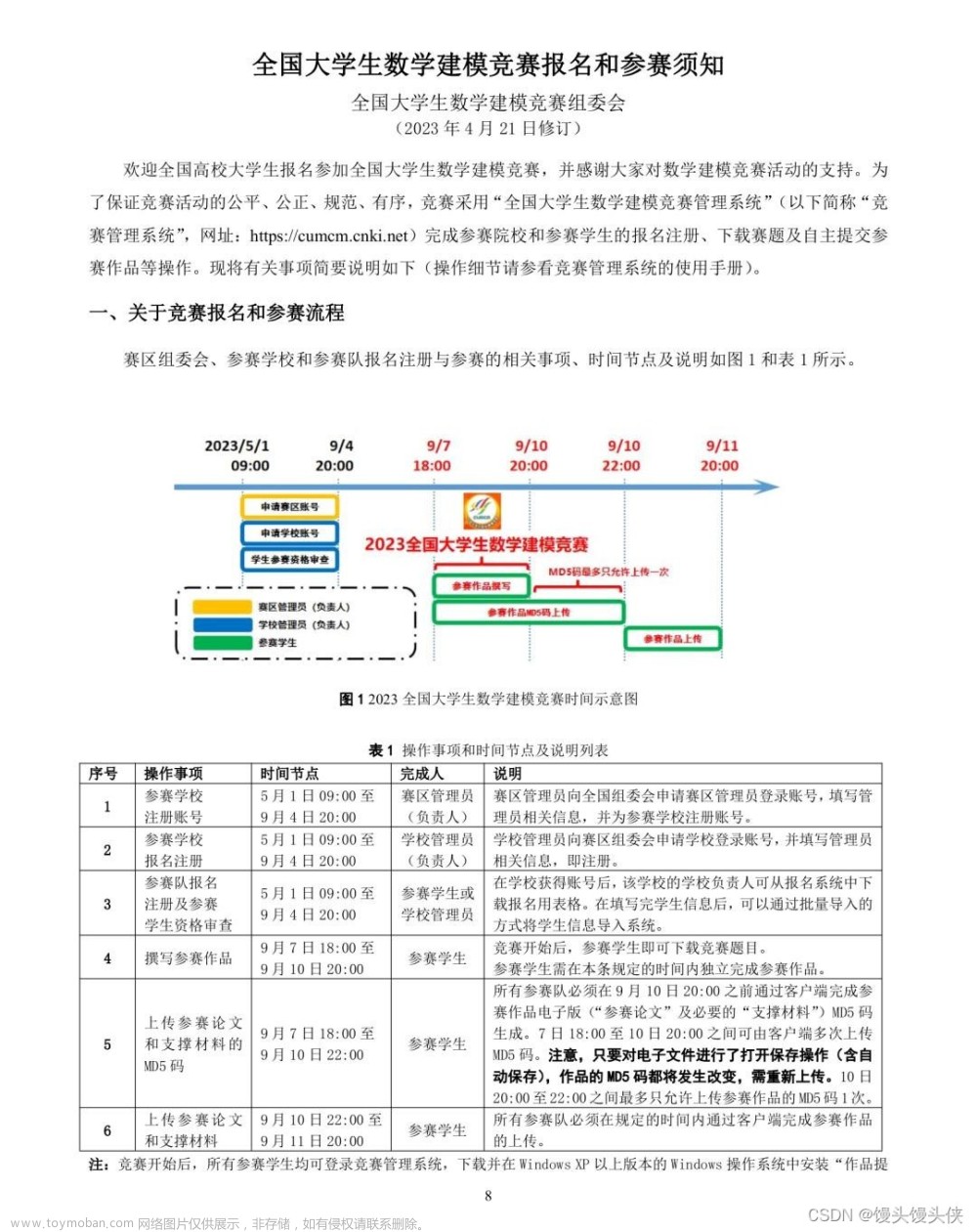
附件给出了包括 390名 3 至 12 个月婴儿以及其母亲的相关数据。这些数据涵盖各种主题,母亲的身体指标包括年龄、婚姻状况、教育程度、妊娠时间、分娩方式,以及产妇心理指标CBTS(分娩相关创伤后应激障碍问卷)、EPDS(爱丁堡产后抑郁量表)、HADS(医院焦虑抑郁量表)和婴儿睡眠质量指标包括整晚睡眠时间、睡醒次数和入睡方式。
请查阅相关文献,了解专业背景,根据题目数据建立数学模型,回答下列问题。
-
许多研究表明,母亲的身体指标和心理指标对婴儿的行为特征和睡眠质量有影响,请问是否存在这样的规律,根据附件中的数据对此进行研究。
-
婴儿行为问卷是一个用于评估婴儿行为特征的量表,其中包含了一些关于婴儿情绪和反应的问题。我们将婴儿的行为特征分为三种类型:安静型、中等型、矛盾型。请你建立婴儿的行为特征与母亲的身体指标与心理指标的关系模型。数据表中最后有20组(编号391-410号)婴儿的行为特征信息被删除,请你判断他们是属于什么类型。
-
对母亲焦虑的干预有助于提高母亲的心理健康水平,还可以改善母婴交互质量,促进婴儿的认知、情感和社交发展。CBTS、EPDS、HADS的治疗费用相对于患病程度的变化率均与治疗费用呈正比,经调研,给出了两个分数对应的治疗费用,详见表1。现有一个行为特征为矛盾型的婴儿,编号为238。请你建立模型, 分析最少需要花费多少治疗费用,能够使婴儿的行为特征从矛盾型变为中等型?
若要使其行为特征变为安静型,治疗方案需要如何调整?
表1. 患病得分与治疗费用
| CBTS | EPDS | HADS | |||
|---|---|---|---|---|---|
| 得分 | 治疗费用(元) | 得分 | 治疗费用(元) | 得分 | 治疗费用(元) |
| 0 | 200 | 0 | 500 | 0 | 300 |
| 3 | 2812 | 2 | 1890 | 5 | 12500 |
-
婴儿的睡眠质量指标包含整晚睡眠时间、睡醒次数、入睡方式。请你对婴儿的睡眠质量进行优、良、中、差四分类综合评判,并建立婴儿综合睡眠质量与母亲的身体指标、心理指标的关联模型,预测最后20组(编号391-410号)婴儿的综合睡眠质量。
-
在问题三的基础上,若需要让238号婴儿的睡眠质量评级为优,请问问题三的治疗策略是否需要调整?如何调整?
2 问题分析
2.1 问题一
对于母亲的身体指标和心理指标对婴儿的行为特征和睡眠质量的影响,这是一个回归分析建模问题。将婴儿行为特征和婴儿的整晚睡眠时间作为因变量,而母亲的身体指标和心理指标(母亲年龄、婚姻状况、教育程度、妊娠时间、分娩方式、CBTS、EPDS和HADS)作为自变量进行分析。一般采用多元线性回归模型来建模。多元线性回归模型的目标是找到一组线性关系,将自变量与因变量联系起来。回归模型的形式可以表示为:
Y
=
β
0
+
β
1
∗
X
1
+
β
2
∗
X
2
+
.
.
.
+
β
n
∗
X
n
+
ε
Y = β0 + β1*X1 + β2*X2 + ... + βn*Xn + ε
Y=β0+β1∗X1+β2∗X2+...+βn∗Xn+ε
其中Y表示因变量(即婴儿行为特征和婴儿睡眠质量),X1到Xn表示自变量(即母亲的身体指标和心理指标),β0到βn表示回归系数,ε表示误差项。
对于回归模型的拟合程序的评估指标有调整的R方、AIC、BIC等。注意在回归分析中,需要提出假设条件,并要分析回归结果,考虑各个指标的系数估计值和其显著性检验结果。如以下三个方面。
- 系数估计值:表示自变量对因变量的影响强度,例如β1表示自变量x1对因变量y的影响强度,β2表示自变量x2对因变量y的影响强度等等。
- t值和p值:用于检验各个系数估计值的显著性程度。t值可以表示变量的标准误和系数之间的比值,而p值可以表示该t值在显著性水平下的置信区间范围。一般来说,p值小于0.05或0.01时,表示该系数估计值在显著性水平下具有统计学意义,即该自变量对因变量的影响显著。
- 回归方程的拟合程度:可用R方和调整R方来衡量。R方表示模型拟合数据的适配度,可解释为自变量对因变量方差的百分比。调整R方则考虑了自变量数目影响,具有更加稳健的拟合效果。另外,由于数据集中包含相关系数较多,我们还可以考虑使用主成分分析(PCA)来减少自变量的维度,提取主要的特征,并建立主成分回归模型。
此外在多元回归分析中,需要考虑各个特征之间是否存在多重共线性,在回归分析之前可以采用主成分分析(PCA)来减少自变量的维度,提取主要的特征,再建立主成分回归模型。
2.2 问题二
这是一个分类问题,并需要预测20个样本的类别。分类模型的建立步骤如下:
-
数据预处理:对收集到的数据进行缺失值处理、异常值处理、标准化等预处理步骤。
-
特征工程:进行特征转换、特征组合或选择等操作,以提取更具有区分度的特征。
-
模型选择:根据数据的特征和模型的要求,选择适合的多类别分类算法,如逻辑回归、支持向量机、决策树、随机森林、神经网络等。
-
模型评估:使用交叉验证、混淆矩阵、准确率、召回率、F1分数等指标,对模型进行评估和优化。
-
模型应用:使用训练好的模型对新样本进行预测和分类,就可以得到婴儿的行为特征分类结果。
2.3 问题三
这就是一个最小优化问题。首先使用线性回归模型来建立CBTS、EPDS和HADS的得分与治疗费用之间的关系。可以将CBTS、EPDS和HADS的得分作为自变量,将治疗费用作为因变量,通过拟合线性回归模型,来估计得分与治疗费用之间的线性关系。
。。。略
然后使用优化算法求解最小化总治疗费用的问题,并得到对应的CBTS、EPDS和HADS得分以及最小的治疗费用。
2.4 问题四
这是一个聚类问题,使用聚类分析将婴儿睡眠质量分为四类:优、良、中和差。可以根据婴儿的整晚睡眠时间、睡醒次数和入睡方式这几个指标,通过K-Means、Birch等指定K值的聚类算法对婴儿睡眠质量进行分类。使用四类作为聚类数,将数据集中的所有样本分成四个组。每个组代表一类睡眠质量。
。。。略
可以通过训练得到的回归模型,预测最后20组(编号391-410号)婴儿的综合睡眠质量评分。
2.5 问题五
在问题三的基础上,预测调整后编号238,在调整诊疗方案后,即是安静型的特征下,目前的睡眠质量是哪个类别。如果属于优就不用调整,属于其他,就需要调整。
3 代码实现
3.1 问题一
import pandas as pd
import statsmodels.api as sm
data = pd.read_excel('./data/附件.xlsx')
data = data[0:-20]
data
import re
# 提取自变量和因变量
X = data[['母亲年龄', '婚姻状况', '教育程度', '妊娠时间(周数)', '分娩方式', 'CBTS', 'EPDS', 'HADS']]
Y1 = data['婴儿行为特征'].map({'中等型':1,'安静型':2,'矛盾型':3})
# 将睡眠时间转为分钟,并剔除其中的异常值
def convert_to_minutes(time_str):
...略
return total_minutes
# 对 Y2 列中的数据进行转换和剔除异常值
Y2 = data['整晚睡眠时间(时:分:秒)'].apply(convert_to_minutes)
# 添加截距项
X = sm.add_constant(X)
# 构建OLS回归模型
model1 = sm.OLS(Y1, X)
model2 = sm.OLS(Y2, X)
# 得到回归结果
result1 = model1.fit()
result2 = model2.fit()
# 输出回归结果概要
print(result1.summary())
# 输出各个指标的系数估计值和显著性检验结果
print(result1.params)
print(result1.pvalues)
根据回归分析的结果,得出以下结论:
- 整体的回归方程(R-squared值)表明,自变量对因变量的解释能力较弱,模型可解释变异性的比例为1.4%。
- 调整后的R-squared值显示,模型的解释能力被调整后的参数效应所削弱,为负值。
- F统计量的值为0.6728,Prob(F-statistic)的值为0.716,两者都较大,说明模型的整体显著性不高。
- 各自变量的系数(coef)没有通过显著性检验(P>|t|),说明它们与因变量之间的关系不显著。
- 通过系数的置信区间([0.025 0.975]),可以推测参数的真实值有一定的不确定性。
- 基于满足多重线性回归的模型假设的前提下,模型的拟合度检验(AIC和BIC值)显示该模型在给定数据集上的拟合度较好。
- 其他检验(如Omnibus和Durbin-Watson)显示存在一些模型假设和统计特性的问题,需要进一步考虑。
综上所述,通过对数据的回归分析,在该数据集中,自变量(母亲年龄、婚姻状况、教育程度、妊娠时间、分娩方式、CBTS、EPDS、HADS)与因变量(婴儿行为特征)之间的关系不明确且不显著,模型的解释能力较弱。因此,自变量对于预测婴儿行为特征的贡献度较低。
print(result2.summary())
print(result2.params)
print(result2.pvalues)
回归结论总结如下:
整晚睡眠时间(时:分:秒)的回归模型具有一定解释能力,R-squared为0.063,说明回归模型能够解释阳性反应量的6.3%的变异性。调整后的R方为0.043,相对更加准确。
- 常数项const的系数为534.4218,显著不为0,说明即使其他自变量为0时,整晚睡眠时间仍然大约为534小时。
- 母亲年龄的系数为0.5649,p值为0.575,不显著,说明母亲年龄与整晚睡眠时间之间可能不存在线性关系。
- 婚姻状况的系数为-17.6649,p值为0.135,不显著,说明婚姻状况对整晚睡眠时间的影响可能不明显。
- 教育程度的系数为-2.6517,p值为0.557,不显著,说明教育程度对整晚睡眠时间的影响可能不明显。
- 妊娠时间(周数)的系数为2.6182,p值为0.268,不显著,说明妊娠时间对整晚睡眠时间的影响可能不明显。
- 分娩方式的系数为21.0835,p值为0.593,不显著,说明分娩方式对整晚睡眠时间的影响可能不明显。
- CBTS的系数为2.5157,p值为0.078,接近显著水平,说明CBTS对整晚睡眠时间可能有一定的影响。
- EPDS的系数为-4.4951,p值为0.000,显著,说明EPDS对整晚睡眠时间有显著负向影响。
- HADS的系数为0.8048,p值为0.633,不显著,说明HADS对整晚睡眠时间的影响可能不明显。
回归模型的统计检验结果显示F统计量为3.200,对应的p值为0.00157,拒绝原假设(自变量都不重要的假设),认为至少有一个自变量对整晚睡眠时间有显著影响。Durbin-Watson统计量为2.180,接近2,说明回归模型中可能不存在自相关性的问题。
总体而言,EPDS(产后抑郁指标)是整晚睡眠时间的重要影响因素,其他自变量对整晚睡眠时间的影响可能不明显。但回归模型的解释能力较弱,R方值较低,可能存在未考虑的其他重要因素。
3.2 问题二
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import re
# 读取数据
import pandas as pd
import statsmodels.api as sm
data = pd.read_excel('./data/附件.xlsx')
data = data[0:-20]
# 数据预处理
...略
# 划分特征和标签
features = data[['母亲年龄', '婚姻状况', '教育程度', '妊娠时间(周数)', '分娩方式', 'CBTS', 'EPDS', 'HADS', '婴儿性别', '婴儿年龄(月)', '整晚睡眠时间(时:分:秒)', '睡醒次数', '入睡方式']]
labels = data['婴儿行为特征']
features
# 划分训练集和测试集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.2, random_state=0)
# 建立决策树模型
clf = DecisionTreeClassifier()
clf.fit(train_features, train_labels)
# 预测测试集结果
pred_labels = clf.predict(test_features)
# 计算准确率
accuracy = sum(pred_labels == test_labels) / len(test_labels)
print("决策树模型准确率:", accuracy)
决策树模型准确率: 0.4230769230769231
# 建立随机森林模型
rf = RandomForestClassifier()
rf.fit(train_features, train_labels)
# 预测测试集结果
pred_labels_rf = rf.predict(test_features)
# 计算准确率
accuracy_rf = sum(pred_labels_rf == test_labels) / len(test_labels)
print("随机森林模型准确率:", accuracy_rf)
随机森林模型准确率: 0.5512820512820513
# 使用模型预测结果
unknown_samples = data[-20:] # 获取需要预测的样本
unknown_features = unknown_samples[['母亲年龄', '婚姻状况', '教育程度', '妊娠时间(周数)', '分娩方式', 'CBTS', 'EPDS', 'HADS', '婴儿性别', '婴儿年龄(月)', '整晚睡眠时间(时:分:秒)', '睡醒次数', '入睡方式']]
unknown_pred_labels = clf.predict(unknown_features)
label_dict ={0:'中等型',1:'安静型',2:'矛盾型'}
print("预测结果:")
for i in range(len(unknown_samples)):
print("样本编号{},预测类型为{}".format(390+i, label_dict[unknown_pred_labels[i]]))
预测结果:
样本编号390,预测类型为中等型
样本编号391,预测类型为安静型
样本编号392,预测类型为安静型
样本编号393,预测类型为安静型
样本编号394,预测类型为中等型
样本编号395,预测类型为安静型
样本编号396,预测类型为安静型
样本编号397,预测类型为安静型
样本编号398,预测类型为安静型
样本编号399,预测类型为中等型
样本编号400,预测类型为安静型
样本编号401,预测类型为中等型
样本编号402,预测类型为中等型
样本编号403,预测类型为中等型
样本编号404,预测类型为中等型
样本编号405,预测类型为中等型
样本编号406,预测类型为中等型
样本编号407,预测类型为安静型
样本编号408,预测类型为安静型
样本编号409,预测类型为中等型
3.3 问题三
请下载完整资料
4 完整资料下载
知乎文章底部下载链接,包括完整的word文档和python代码。文章来源:https://www.toymoban.com/news/detail-631349.html
zhuanlan.zhihu.com/p/648093611文章来源地址https://www.toymoban.com/news/detail-631349.html
到了这里,关于【2023 华数杯全国大学生数学建模竞赛】 C题 母亲身心健康对婴儿成长的影响 Python代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!