一、基本了解
1.1 插件分类
- 插件是用户以自定义方式增强es功能的一种方法,分两类,核心插件和社区贡献插件。
- 插件太多,只需要熟悉插件的安装流程即可,根据项目需要再自行安装。
核心插件:
- 核心插件属于es项目,插件的版本号始终与es安装包的版本号相同,这些插件由es团队维护。
- 项目地址

社区贡献插件:
- 社区贡献插件属于es项目外部的插件。这些插件由单个开发人员或私人公司提供,并拥有各自的许可证及各自的版本控制系统。
1.2 插件管理命令
1.列出当前已安装的插件。这里显示的就是我们已经安装了一个ik分词器插件。
[es-qingjun@localhost bin]$ elasticsearch-plugin list

2.安装插件。
[es-qingjun@localhost bin]$ elasticsearch-plugin install analysis-icu

3.删除插件。
[es-qingjun@localhost bin]$ elasticsearch-plugin remove analysis-icu

- 我们可以使用相关命今获取插件命令的使用说明:$es_home/bin/elasticsearch-plugin - h
1.插件位置指定
当在根目录中运行 Elasticsearch 时,如果使用 DEB 或RPM 安装了 Elasticsearch,则以根目录运行 /usr /share / Elasticsearch/ bin /Elasticsearch-plugin,以便 Elasticsearch 可以写入磁盘的相应文件,否则需要以拥有所有 Elasticsearch 文件的用户身份运行 bin/ Elasticsearch 插件当用户自定义URL 或文件系统时,用户可以通过指定 URL 直接从自定义位置下载插件:
sudo bin / elasticsearch - plugin install [url]
二、分析插件
基本了解:
- 分析器会接受一个字符串作为输入参数,将这个字符串拆分成独立的词或语汇单元(也称之为 token)。
- 在处理过程中会丢弃一些标点符号等字符,处理后会输出一个语汇单元流(也称之为 token stream)。
- es为很多语言提供了专用的分析器,特殊语言所需的分析器可以由用户根据需要以插件的形式提供。
分析器组成的三个部分:
- character filter: 分词之前的预处理,过滤HTML标签、特殊符号转换等。
- tokenizer:用于分词。
- token filter:用于标准化输出。
es内置的主要分析器:
- Standard分析器:默认的分词器,会将词汇单元转换成小写形式,并且去除停用词和标点符号,支持中文(采用的方法为单字切分)。停用词指语气助词等修饰性词语,如 the、an、的、这等。
- Simple分析器:首先通过非字母字符分割文本信息,并去除数字类型的字符,然后将词汇单元统一为小写形式。
- Whitespace分析器:仅去除空格,不会将字符转换成小写形式,不支持中文:不对生成的词汇单元进行其他标准化处理。
- Stop分析器:与Simple 分析器相比,增加了去除停用词的处理。
- Keyword分析器:该分析器不进行分词,而是直接将输入作为一个单词输出。
- Pattern分析器:该分析器通过正则表达式自定义分隔符,默认是“]W+”,即把非字词的符号作为分隔符。
- Language分析器:这是特定语言的分析器,不支持中文,支持如 English、French 和Spanish 等蛮豆颓逼磺糯敢奇害弋亭缆忸侠子补。
注意事项:
- 任何全文检索的字符串域都会默认使用 Standard 分析器。
Standard分析器简介:
- 工作模式:一般来说,分析器会接受一个字符串作为输入。在工作时,分析器会将这个字符串拆分成独立的词或语汇单元(称之为 token),当然也会丢弃一些标点符号等字符,最终分析器输出一个语汇单元流。
- 常规分析器使用算法:Whitespace 分词算法。
- 该算法按空白字符,如空格、Tab、换行符等,对语句进行简单的拆分,将连续的非空格字符组成一个语汇单元。
- 例如,对下面的语句使用 Whitespace 分词算法分词时,会得到如下结果:
原文:You're the lst runner home! 结果: You're、the、st、runner、home!- Standard 分析器使用算法: Unicode 文本分制算法。
- 可以寻找单词之间的界限,并输出所有界限之间的内容。
- Unicode 内包含的知识使其可以成功地对包含混合语言的文本进行分词。
2.1 es中的分析插件
分析插件是一类插件,可通过向es中添加新的分析器、标记化器、标记过滤器或字符过滤器等扩展es的分析功能。
2.1.1 官方核心分析插件
| 插件名称 | 作用 |
|---|---|
| ICU库 | 可以扩展对 Unicode 的支持, 包括更好地分析亚洲语言、Unicode 规范化、 支持 Unicode 的大小写折叠、支持排序和音译。 |
| Kuromoji 插件 | 对日语进行分析 |
| Lucene Nori 插件 | 对韩语进行分析 |
| Phonetic 插件 | 可以使用 Soundex、Metaphone、Caverphone 和其他编码器/解码器将标记分析为其语音等价物。 |
| SmartCN插件 | 可用于对中文或中英文混合文本进行分析。 该插件利用概率知识对简化中文文本进行最优分词。 首先文本被分割成句子,然后每个句子再被分割成单词。 |
| Stempel插件 | 对波兰语进行分析 |
| Ukrainian 插件 | 为乌克兰语提供词干分析 |
2.1.2 社区提供分析插件
| 插件名称 | 作用 |
|---|---|
| IK Analysis Plugin | 将 Lucene IK Analyzer 集成到 Elasticsearch 中,支持读者自定义字典 |
| Pinyin Analysis Plugin | 一款拼音分析插件,该插件可对汉字和拼音进行相互转换。 |
| Vietnamese Analysis Plugin | 对越南语进行分析 |
| Network Addresses Analysis Plugin | 可以用于分析网络地址。 |
| Dandelion Analysis Plugin | 可译为蒲公英分析插件,该插件提供了一个分析器(称为“蒲公英-A”),该分析器会从输入文本中提取的实体进行语义搜索。 |
| STConvert Analysis Plugin | 可对中文简体和繁体进行相互转换 |
2.2 API扩展插件
- API扩展插件通过添加新的、与搜索有关的 API 或功能,实现对es新功能的添加。
- es社区人员陆陆续续贡献了不少API扩展插件编辑器,汇总如下:
| 插件名称 | 作用 |
|---|---|
| Carrot2 Plugin | 用于结果聚类。 可访问 GitHub 官网搜索 elasticsearch-carrot2,查看配套代码。 |
| Elasticsearch Trigram Accelerated Regular Expression Filter | 该插件包括查询、过滤器、原生脚本、评分函数,以及用户最终创建的任意其他内容,通过该插件可以让搜索变得更好。 可访问 GitHub 官网搜索 search-extra 获取插件。 |
| Elasticsearch Experimental Highlighter | Java 编写,用于文本高亮显示。 可访问 GitHub 官网,搜索 search-highlighter 获取插件。 |
| Entity Resolution Plugin | 该插件使用 Duke (Duke 是一个用 Java 编写的、快速灵活的、删除重复数据的引擎)进行重复检测。读者可访问 GitHub 官网,搜索 elasticsearch-entity-resolution 获取插件 |
| Entity Resolution Plugin(zentity) | 用于实时解析es中存储的实体信息。 可访问 GitHub 官网,搜索zentity 获取插件。 |
| POL language Plugin | 该插件允许用户使用简单的管道查询语法对es进行查询。 可访问 GitHub官网,搜索 elasticsearch-pql 获取插件。 |
| Elasticsearch Taste Plugin | 该插件基于 Mahout Taste 的协同过滤算法实现。 可访问 GitHub 官网,搜索elasticsearch-taste 获取插件。 |
| WebSocket Change Feed Plugin | 该插件允许客户端创建到es节点的 WebSocket 连接,并从数据库接收更改的提要。 可访问 GitHub 官网,搜索 es-change-feed-plugin 获取插件 |
三、Head 插件
- es-head插件在0.x-2.x版本时,是集成在elasticsearch内的。由elasticsearch的bin/elasticsearch-plugin来管理插件,从2.x版本跳到了5.x版本后,head就作用了一个独立的服务来运行了。
- Elasticsearch 5之后则需要将elasticsearch-head服务单独运行,并且支持Chrome的插件方式或者Docker容器运行方式。
- 这个插件我们前面已经安装过,这里就介绍下具体怎么玩它。
插件简介:
- Head 插件,全称为 elasticsearch-head,是一个界面化的集群操作和管理工具,可以对集群进行“傻瓜式”操作。
- 既可以把 Head 插件集成到 Elasticsearch 中,也可以把 Head 插件当成-个独立服务。
主要功能:
- 显示es集群的拓扑结构,能够执行索引和节点级别的操作。
- 在搜索接口能够查询es集群中原始JSON 或表格格式的数据。
- 能够快速访问并显示es集群的状态。
3.1 安装
1.安装node.js环境,注意版本不要太高,不然会跟linux本身的依赖库包版本冲突报错。
[root@localhost bck]# tar zxf node-v16.9.0-linux-x64.tar.gz
[root@localhost bck]# mv node-v16.9.0-linux-x64 /usr/local/node
[root@localhost bck]# tail -2 /etc/profile
export node_home=/usr/local/node
export PATH=$node_home/bin:$PATH
[root@localhost bck]# source /etc/profile
[root@localhost bck]# node -v
v16.9.0

2.解压es-head安装包,安装依赖。注意这里需要进入解压出来的目录里执行命令。下载地址
#安装cnpm
[root@localhost elasticsearch-head-5.0.0]# npm install -g cnpm --registry=https://registry.npm.taobao.org
#安装依赖
[root@localhost elasticsearch-head-5.0.0]# cnpm install


3.启动es-head
[root@localhost elasticsearch-head-5.0.0]# npm run start

4.访问页面。
5.修改es配置文件,添加如下两行,解决跨域问题。
[root@localhost elasticsearch-8.5.2]# vi config/elasticsearch.yml
http.cors.enabled: true
http.cors.allow-origin: "*"
6.重启es,es-head就可以连接es了。
3.2 web页面使用
Head 插件首页由 4 部分组成:节点地址输入区域、信息刷新区域、导航条、概览中的集群信息汇总。
3.2.1 概览页
- 第一部分:节点地址输入区域。这里输入es集群任意一个节点IP就可以查看集群所有状态和数据。

- 第二部分:信息刷新区域。
- 刷新区域可以查看es相关的信息和刷新插件的信息。
2. 信息区域可以看到es相关的信息,包括集群节点信息、节点状态、集群状态集群信息、集群健康值等内容。单击对应的按钮,即可查看对应的信息。

- 第三部分:导航条。看到概览、索引、数据浏览、基本查询和复合查询五个 Tab 导航,默认为概览。

- 第四部分:概览中的集群信息汇总。可以看到es已经创建的索引,这些索引信息包含了索引的名称、索引的大小和索引的数据量,并且通过“信息”和“动作”两个按钮可以查看索引信息,或者给索引创建别名。

- 第五部分:集群健康值。es中有专门的衡量索引健康状况的标志,分为三个等级:
- green,绿色。代表所有的主分片和副本分片都已分配,集群是 100% 可用的。
- yellow,黄色。所有的主分片已经分片了,但至少还有一个副本是缺失的,不会有数据丢失,所以搜索结果依然是完整的。不过高可用性在某种程度上会被弱化。如果更多的分片消失,就会丢数据了。可以把 yellow 想象成一个需要及时调查的警告。
- red,红色。至少一个主分片以及它的全部副本都在缺失中。意味缺少数据,搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
- 当只有一台主机时,索引的健康状况是 yellow。因为一台主机,集群没有其他的主机可以做副本,所以说,这就是一个不健康的状态,因此集群也是十分有必要的。

- 第六部分:索引分片。Elasticsearch数据就存储在这些分片中。每一个方框就是elasticsearch的分片,粗线方框是es的主分片,主分片旁边细线方框是es的备份分片,对应关系,粗线方框0的备份分片是细线方框0,以此类推。


3.2.1.1 unassigned问题解决
副本分片作用:
- 主要目的是为了故障转移,为备份数据。如果持有主分片的节点挂掉了,一个副本分片就会晋升为主分片的角色。
产生unassigned问题原因:
- 副本分片和主分片不能放在同一个节点上,在这里集群里只有一个节点,副本分片没有办法分配到其他的节点上,所以出现所有副本分片都是未分配的情况。因为只有一个节点,如果存在主分片节点挂掉了,那么整个集群理应就挂掉了,不存在副本分片升为主分片的情况。

处理手段:
- 将每个索引的副本数重置为0即可解决这个未知节点问题。“number_of_replicas”:0


3.2.2 索引页
- 可以查看当前es集群中的索引情况。

1.新建索引。
2.查看。

3.2.3 数据浏览页
- 可以查看特定索引下的数据。

3.2.4 基本查询页

匹配方式:
- must子句:文档必须匹配 must 查询条件,相当于“=”。
- should子句:文档应该匹配 should 子查询的一个或多个条件。
- must_not子句:文档不能匹配该查询条件,相当于“!=”。
- term:表示的是精确匹配。
- wildcard:表示的是通配符匹配。
- prefix:表示的是前缀匹配。
- range:表示的是区间查询。

注意事项:
- 当用多个查询条件进行搜索或查询时,需要注意多个查询条件间的匹配方式。
- 匹配方式主要有3种,即must、should 和mus_not。
- “+”“_”按用于增加查询条件或减少查询条件。

- 在查询结果展示区域中,用户可以设置数据的呈现形式,如 table、JSON、CVS 表格等还可以勾选“显示查询语句”选项,呈现通过表单内容拼接的搜索语句。

3.2.4.1 term指定查询

3.2.4.2 range范围查询

3.2.4.3 多条件查询

3.2.5 复合查询页
基本了解:
- “复合查询”标签页可以自由拼接条件,进行复杂的数据查询。
- “复合查询”标签页为用户提供了编写 RESTful接口风格的请求,用户可以使用JSON 进行复杂的查询,比如发送 PUT 请求新增及更新索引,使用 delete 请求删除索引等。

RESTful API的基本格式:
- http://ip:port/索引/类型/文档ID

配置接口的四个选项:
- 在es中,以POST 方法自动生成ID,而 PUT 方法需要指明ID。
- 请求方法与HTTP 的请求方法相同,如 GET、PUT、POST、DELETE 等。
- 还可以配置查询JSON 请求数据、请求对应的es节点和请求路径。
- 支持配置JSON验证器对用户输入的JSON 请求数据进行JSON 格式校验。
- 支持重复请求计时器配置重复请求的频率和时间。
- 在结果转换器中支持使用 JavaScript 表达式变换结果。

3.2.5.1 查询数据
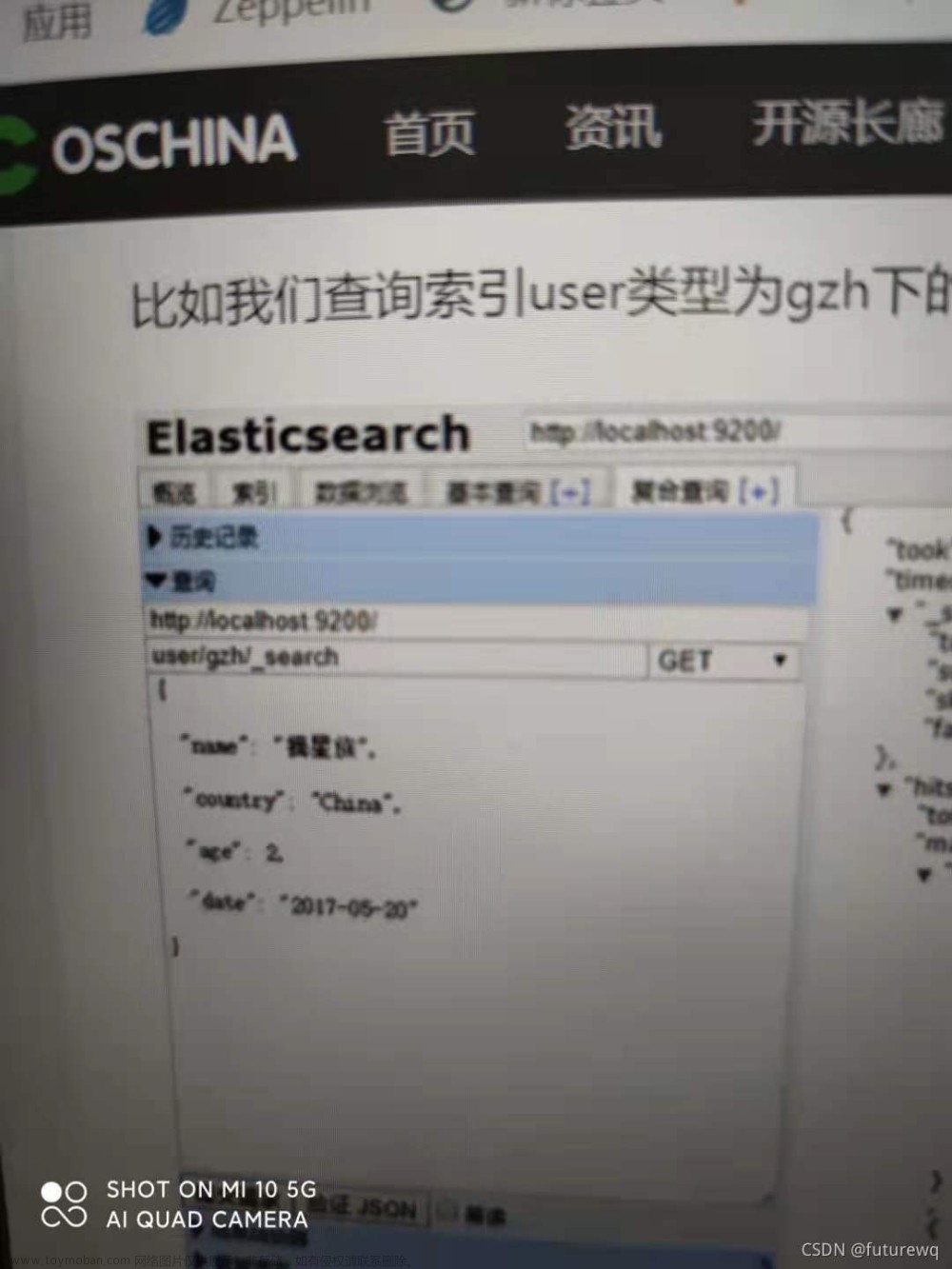
- 查询。查询索引111中编号为1的文档。

3.2.5.2 插入数据
新增数据有两种方式,POST和PUT,两者的区别就是POST自动生成文档编号,也可以指定,而PUT需要指定文档编号生成。
1.post方式指定id生成。

2.post方式不指定id生成会是随机生成一个id。
3.put方式指定id生成。
3.2.5.3 查询所有文档

3.2.5.4 布尔查询
- must:文档必须匹配这些条件才能被搜索出来。
- must_not:文档必须不匹配这些条件才能被搜索出来。
- should:如果满足这些语句中的任意语句,则将增加搜索排名结果 score; 否则,对查询结果无任何影响。其主要作用是修正每个文档的相关性得分。
- filter:表示必须匹配,但它是以不评分的过滤模式进行的。这些语句对评分没有贡献只是根据过滤标准排除或包含文档。
注意事项:
- 如果没有 must 语句,那么需要至少匹配其中的一条 should 语句。但如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
- 查看匹配”qingjun“,且不匹配”baimu“的文档。
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "qingjun"
}
}
],
"must_not": [
{
"match": {
"name": "baimu"
}
}
]
}
}
}

3.2.5.5 创建索引库


四、ik分词器
什么是IK分词器 ?
- 分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神"会被分为"我"“爱”“狂"神”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
注意事项:
- 如果要使用中文,建议使用ik分词器 !
- ik提供了两个分词算法:ik_smat 和ik_max_word,其中 ik_mart 为最少切分,ik_max_word为最细粒度划分!一会我们测试!
常用配置文件:
- IKAnalyzer.cfg.xml:用来配置自定义词库。
- main.dic:ik原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起,最常用的文件。
- quantifier.dic:存放了一些单位相关的词。
- suffix.dic:存放了一些后缀。
- surname.dic:中国的姓氏。
- stopword.dic:包含了英文的停用词,停用词 stop word ,比如 a 、the 、and、 at 、but 等会在分词的时候直接被干掉,不会建立在倒排索引中。

4.1 Windows安装
1.下载ik分词器安装包,注意下载版本需要与安装的es版本一致。github下载地址
2.将下载的压缩包解压到我们本地安装es根目录下的plugins目录。我这里新增加了一个ik目录是为了好区分,该目录下的所有文件就是解压出来的。
3.重启es,包括与之相关的所有服务kibana。重启再启动后能读到分词器,日志就会显示。
4.可以通过elasticsearch-plugin命令查看加载进来的插件,这里就显示了一个ik插件。
5.启动kibana测试。
get _analyze ##get请求,_analyze为请求对象(分词器)。下面括号内容为请求要求。
{
"analyzer": "ik_smart", ##选中ik分词器。
"text": "跟我一起学运维" ##分哪个词。
}
ik_smart为最少切分,是将一句话按段切分出来的,分出来的内容没有重复的字。

ik_max_word最小粒度划分,穷尽所有组合,会出现重复的字。

这里就出现了一个问题,把“学运维”三个字拆分了,我不需要将这三个字拆分,应该是一个组合词,该怎么办?自己去添加词库。
6.进入ik分词器安装目录下的config目录,手动创建一个文档,以dic结尾,里面添加我们想要的词。
7.将新建的文档名称添加到IKAnalyzer.cfg.xml文件中。
8.重启es和kibana。
9.再次查看kibana上的分词效果。此时“学运维”就是我们添加再词库里的词,而不是切分开来;用最小粒度查看就多了一个“学运维”词,之前是没有这个词的。

4.2 Linux安装
1.同样需要准备ik分词器的安装包,版本最好与es、kibana版本一致。我们还是解压到es的插件目录里,方便管理。
2.进入config目录,自定义分词。
- 第一种,在默认词库里添加后在重启es、kibana服务,测试效果。


- 第二种,新建自定义分词库,再重启es和kibana,测试效果。


4.3 自定义停用词词典
- 上面我们已经自定义了“学运维”一词,在分词时可以把这三个字排一起当成一个词分出来。
- 当然也可以自定义停用词词典,比如了、的、啥、么,我不像搜索这样的词出来。
1.比如我想在能把“吧”这个词搜索出来,对我没有实际意义,就可以把它单独停用。
2.在ik/config目录下自定义个文件,里面添加不像分的词,再添加到IKAnalyzer.cfg.xml文件里,最后重启es和kibana。文章来源:https://www.toymoban.com/news/detail-631723.html

3.重启后在测试,就不会有“吧”这个词了。 文章来源地址https://www.toymoban.com/news/detail-631723.html
文章来源地址https://www.toymoban.com/news/detail-631723.html
到了这里,关于elasticsearch基础6——head插件安装和web页面查询操作使用、ik分词器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!