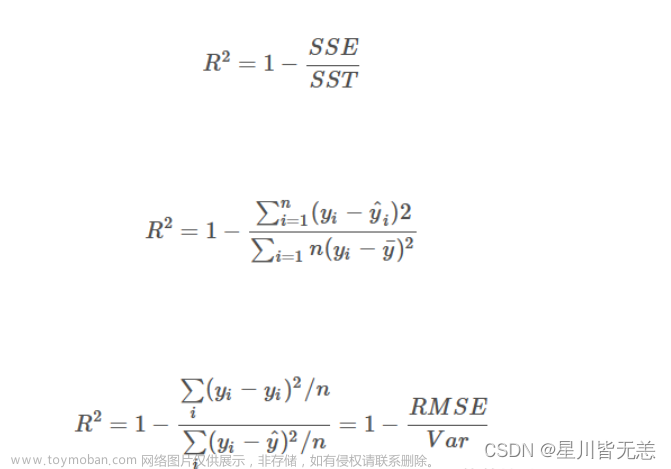模型训练pipeline
基于数十种统计类型特征,构建LR回归模型。代码逻辑包含:样本切分、特征预处理、模型训练、模型评估、特征重要性的可视化。
步骤一:导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, PolynomialFeatures
from sklearn.metrics import mean_squared_error, r2_score
步骤二:读取数据
data = pd.read_csv('data.csv')
步骤三:数据预处理
# 去除缺失值
data.dropna(inplace=True)
# 划分自变量和因变量
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 构建pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('poly', PolynomialFeatures(degree=2, include_bias=False)),
('reg', LinearRegression())
])
# 训练模型
pipeline.fit(X_train, y_train)
# 预测结果
y_pred = pipeline.predict(X_test)
步骤四:模型评估文章来源:https://www.toymoban.com/news/detail-631875.html
# 均方误差
mse = mean_squared_error(y_test, y_pred)
# R2值
r2 = r2_score(y_test, y_pred)
print('MSE: %.3f' % mse)
print('R2 score: %.3f' % r2)
步骤五:特征重要性的可视化文章来源地址https://www.toymoban.com/news/detail-631875.html
# 获取特征重要性
importance = pipeline.named_steps['reg'].coef_
# 将特征重要性与对应特征名对应
feature_names = pipeline.named_steps['poly'].get_feature_names(X.columns)
feature_importance = pd.DataFrame({'Feature': feature_names, 'Importance': importance})
feature_importance = feature_importance.sort_values('Importance', ascending=False)
# 绘制水平条形图
plt.figure(figsize=(10, 8))
plt.barh(feature_importance['Feature'], feature_importance['Importance'])
plt.title('Feature importance')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()
到了这里,关于【sklearn】回归模型常规建模流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!