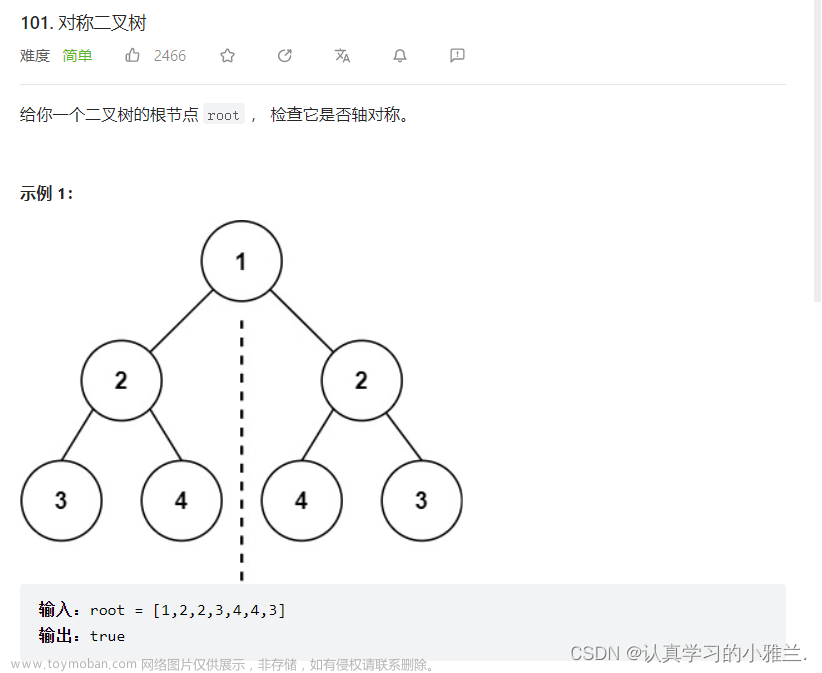
一、思路
二分查找——因为它可以快速地将版本范围缩小一半,从而更快地找到第一个坏版本。
二、解题方法
维护一个左边界 left 和一个右边界 right,在每一步循环中,我们计算中间版本 mid,然后检查它是否是坏版本。如果是坏版本,说明第一个坏版本在 mid 或者它之前,我们将 right 更新为 mid。如果不是坏版本,说明第一个坏版本在 mid 之后,我们将 left 更新为 mid + 1。最终,当 left 和 right 相等时,就找到了第一个坏版本。
三、code
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
int left=1;//设定一个左边界 left 和一个右边界 right
int right=n;
while(left<right)
{
int mid=left+(right-left)/2;
if(isBadVersion(mid))
{
right=mid;
}
else
{
left=mid+1;
}
}
return left;//也可以是right。当 left 和 right 相等时,就找到了第一个坏版本。
}
};=====================================================================
①
二分查找(Binary Search)是一种高效的搜索算法,适用于已排序的数据集。它的核心思想是将待查找的数据与数据集的中间元素进行比较,从而排除一半的数据,然后继续在剩余的一半中继续查找,以此类推,直到找到目标元素或者确定目标元素不存在。
二分查找的步骤如下:
-
确定查找范围的起始点和终点,通常是整个数据集的起始和终止位置。
-
计算中间元素的位置。这可以通过
(start + end) / 2来获得,也可以使用(start + end) >> 1来获得,这两种方法在整数运算中可以避免溢出问题。 -
比较中间元素与目标元素的大小关系,如果相等,则找到了目标元素,算法结束。
-
如果中间元素比目标元素大,那么目标元素应该在左半部分,将终点位置更新为中间位置减一。
-
如果中间元素比目标元素小,那么目标元素应该在右半部分,将起始位置更新为中间位置加一。
-
重复步骤2到步骤5,直到起始位置大于终点位置,表示查找范围为空,目标元素不存在。
二分查找是一种时间复杂度为 O(log n) 的算法,因此在处理大规模数据时非常高效。然而,它要求数据集是已排序的,否则无法正确进行查找。
错误:使用线性搜索来解决这个问题,但是可能因为版本数量很多而导致超时。
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);文章来源:https://www.toymoban.com/news/detail-631937.html
class Solution {
public:
int firstBadVersion(int n) {
for (int i = 1; i <= n; ++i) {
if (isBadVersion(i) == true) {
return i;
}
}
return -1; // 如果没有找到坏版本,可以根据题目要求返回一个特定值
}
};
文章来源地址https://www.toymoban.com/news/detail-631937.html
到了这里,关于leetcode每日一练-第278题-第一个错误的版本的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!