环境准备
| node1节点 | 192.168.40.16 | elasticsearch | 2c/4G |
| node2节点 | 192.168.40.17 | elasticsearch | 2c/4G |
| Apache节点 | 192.168.40.170 | logstash/Apache/kibana | 2c/4G |
| filebeat节点 | 192.168.40.20 | filebeat | 2c/4G |
https://blog.csdn.net/m0_57554344/article/details/132059066?spm=1001.2014.3001.5501
接上期elk部署我们这次加一个filebeat节点
实验:
在filebeat节点上操作
1.安装 Filebeat
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat

文章来源地址https://www.toymoban.com/news/detail-632013.html
2.设置 filebeat 的主配置文件
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log #指定 log 类型,从日志文件中读取消息
enabled: true
paths:
- /var/log/messages #指定监控的日志文件
- /var/log/*.log
fields: #可以使用 fields 配置选项设置一些参数字段添加到 output 中
service_name: filebeat
log_type: log
service_id: 192.168.40.20
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.40.170:5044"] #指定 logstash 的 IP 和端口
#启动 filebeat
./filebeat -e -c filebeat.yml

4.在 Logstash 组件所在节点上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d
vim logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.40.16:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
#启动 logstash
logstash -f logstash.conf


5.浏览器访问 http://192.168.40.170:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
二、ELFK+zookeeper+kafka
一 部署zookeeper集群
//准备 3 台服务器做 Zookeeper 集群
192.168.40.21
192.168.40.22
192.168.40.23
1.安装前准备
//关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
//安装 JDK
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
java -version
cd /opt
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz

2.安装 Zookeeper
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
//修改配置文件
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
tickTime=2000 #通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10 #Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5 #Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data ●修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs ●添加,指定存放日志的目录,目录需要单独创建
clientPort=2181 #客户端连接端口
#添加集群信息
server.1=192.168.40.21:3188:3288
server.2=192.168.40.22:3188:3288
server.3=192.168.40.23:3188:3288

server.A=B:C:D
●A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
●B是这个服务器的地址。
●C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
●D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
//拷贝配置好的 Zookeeper 配置文件到其他机器上
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.22:/usr/local/zookeeper-3.5.7/conf/
scp /usr/local/zookeeper-3.5.7/conf/zoo.cfg 192.168.40.23:/usr/local/zookeeper-3.5.7/conf/
//在每个节点上创建数据目录和日志目录
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
//在每个节点的dataDir指定的目录下创建一个 myid 的文件
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
//配置 Zookeeper 启动脚本
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac

// 设置开机自启
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper 
//分别启动 Zookeeper
service zookeeper start
//查看当前状态
service zookeeper status

三 部署 kafka 集群
1.下载安装包
2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}

vim server.properties
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.40.21:2181,192.168.40.22:2181,192.168.40.23:2181 ●123行,配置连接Zookeeper集群地址
//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile


//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka
//分别启动 Kafka
service kafka start

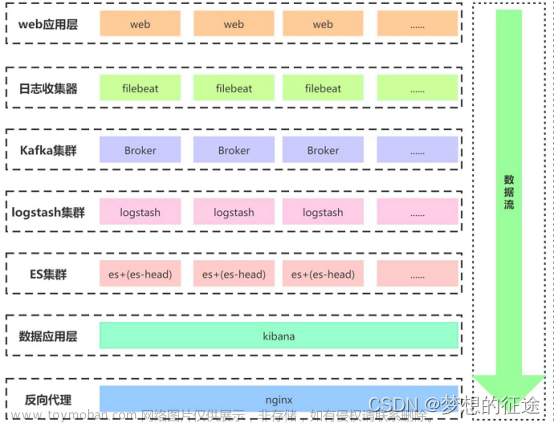
四 部署Filebeat+Kafka+ELK

1.修改filebeat配置文件filebeat.yml收集日志转发(生产)给kafka
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/httpd/access_log
tags: ["nginx_access"]
- type: log
enabled: true
paths:
- /var/log/httpd/error_log
tags: ["nginx_error"]
......
#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: ["192.168.40.21:9092","192.168.40.22:9092","192.168.40.23:9092"] #指定 Kafka 集群配置
topic: "httpd" #指定 Kafka 的 topic
#启动 filebeat
./filebeat -e -c filebeat.yml




2.修改logstash配置从kafka中消费日志,并输出到kibana前端展示

开启logstash,此时访问web测试页面,就可以在kibana对日志收集分析了




 文章来源:https://www.toymoban.com/news/detail-632013.html
文章来源:https://www.toymoban.com/news/detail-632013.html
到了这里,关于EFLFK——ELK日志分析系统+kafka+filebeat架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!