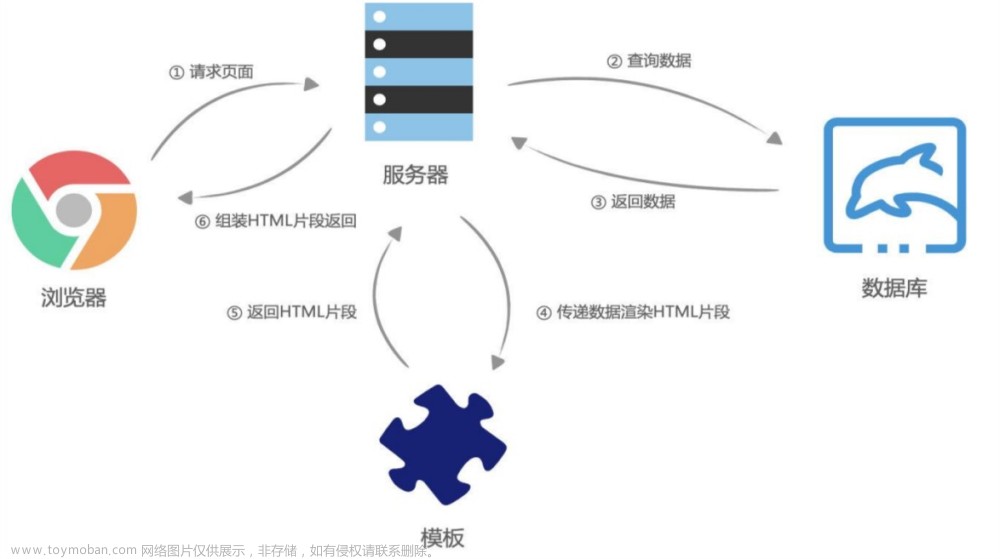
认识url
平时俗称的 “网址” 其实就是说的 URL,例如在百度上搜索一个C++

可以看到这段网址前面有个 https 那么这个就代表着使用的是https协议,现在都是使用https协议,不过还是需要认识以下http协议
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现。所以在通信的时候需要先对字符进行转义。
比如上面搜索的c++,在网址里就会将 + 转义,转义规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
+的字符码为43,所以转换为16进制为2B。可以通过某些网站来查看转义后的信息,例如:chinaz

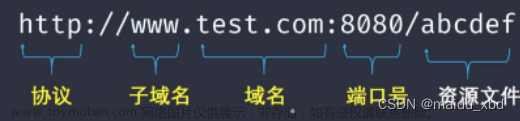
那么在http协议中,一串网址各个部分又有什么含义呢,假设现在有这么一串网址

也就是说,网络通信本就是在服务器中找对应的文件资源
http协议格式
了解了网址的意义,那么就来了解一下http协议的格式是什么样的。

通信
那么两端的机器接收到了数据后,怎么样保证读取到一个完整的http协议的数据呢
- 并不能确保将整个数据读完,但是可以确保将一行读完,因为其中的数据都是由 \r\n 结尾的
- 所以可以将请求行和请求报头读完,可以发现正文和报文是有空行分割的
- 一旦读到空行说明请求行和请求报头就读完了
- 接着报头里可以存放着正文长度的属性,根据正文长度再去读正文即可
- 响应端同理
那么请求和响应怎么样去序列化和反序列化呢,这个过程有http协议去完成即可
代码验证
验证这个过程只需要将服务端实现即可,客户端用浏览器去进行链接
细节
有时候通过网址去访问服务器时,并不会直接去指明去服务器的哪一个路径找资源,这时候不指明的情况就会默认到服务器的默认路径。例如直接输入 baidu.com 就会跳到百度的首页。因此在编写代码时要加上一个默认的路径
Util.hpp
编写一个工具类,将一些调用的方法放到里面
#pragma once
#include <iostream>
#include <string>
using namespace std;
class Util
{
public:
// 提取并删除首行
// 读到的首行并不需要处理
static string GetOneLine(string &inbuffer, const string &sep)
{
auto pos = inbuffer.find(sep);
if(pos == string::npos)
return "";
string sub = inbuffer.substr(0, pos);
inbuffer.erase(0, sub.size() + sep.size());
return sub;
}
};
protocol.hpp
编写请求和响应类
#pragma once
#include <iostream>
#include <string>
#include <sstream>
#include "Util.hpp"
using namespace std;
class HttpRequest
{
public:
string _inbuffer; // 接收请求数据
string _method; // 处理数据方法的名称
string _url; // url
string _httpversion; // http协议版本
string _path; // 查找资源的路径
HttpRequest(){}
// 处理收到的数据
// 添加默认路径
void parse()
{
// 定义分隔符
#define sep "\r\n"
#define default_root "./wwwroot"
#define home_page "index.html"
// 拿到第一行,并删除
string line = Util::GetOneLine(_inbuffer, sep);
if(line.empty())
return;
cout << "line: " << line << endl;
// 拿到第一行中的三个字段
stringstream ss(line);
ss >> _method >> _url >> _httpversion;
// 添加默认路径
_path = default_root;
_path += _url;
// 如果url为/ 则添加默认路径
if(_path[_path.size() - 1] == '/')
_path += home_page;
}
};
class HttpResponse
{
public:
string _outbuffer;
};
Server.hpp
编写服务端
#pragma once
#include "Protocol.hpp"
#include <sys/types.h>
#include <sys/socket.h>
#include <cstring>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <functional>
#include <sys/wait.h>
#include <unistd.h>
using func_t = function<bool(const HttpRequest &, HttpResponse &)>;
class Server
{
public:
Server(func_t func, uint16_t &port)
: _port(port), _func(func)
{
}
void Init()
{
// 创建负责监听的套接字 面向字节流
_listenSock = socket(AF_INET, SOCK_STREAM, 0);
if (_listenSock < 0)
exit(1);
// 绑定网络信息
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY;
if (bind(_listenSock, (struct sockaddr *)&local, sizeof(local)) < 0)
exit(3);
// 设置socket为监听状态
if (listen(_listenSock, 5) < 0)
exit(4);
}
// 服务端读取处理请求方法
void HttpHandler(int sock)
{
// 确保读到完整的http请求
char buffer[4096];
size_t n = recv(sock, buffer, sizeof(buffer) - 1, 0);
HttpRequest req;
HttpResponse res;
if (n > 0)
{
buffer[n] = 0;
req._inbuffer = buffer;
// 处理读到的数据
req.parse();
// 调用回调方法反序列化请求并得到响应结果和序列化响应结果
_func(req, res);
// 发回客户端
send(sock, res._outbuffer.c_str(), res._outbuffer.size(), 0);
}
}
void start()
{
while (1)
{
// server获取建立新连接
struct sockaddr_in peer;
memset(&peer, 0, sizeof(peer));
socklen_t len = sizeof(peer);
// 创建通信的套接字
// accept的返回值才是真正用于通信的套接字
_sock = accept(_listenSock, (struct sockaddr *)&peer, &len);
if (_sock < 0)
continue;
cout << "sock: " << _sock << endl;
// 利用多进程实现
pid_t id = fork();
if (id == 0) // child
{
close(_listenSock);
// 调用方法包括读取、反序列化、计算、序列化、发送
HttpHandler(_sock);
close(_sock);
exit(0);
}
close(_sock);
// father
pid_t ret = waitpid(id, nullptr, 0);
}
}
private:
int _listenSock; // 负责监听的套接字
int _sock; // 通信的套接字
uint16_t _port; // 端口号
func_t _func;
};
Server.cc
#include "Server.hpp"
#include <memory>
// 输出命令错误函数
void Usage(string proc)
{
cout << "Usage:\n\t" << proc << " local_ip local_port\n\n";
}
// 服务端处理的回调函数
bool func(const HttpRequest &req, HttpResponse &res)
{
// 打印方便调试查看接收到的数据是否正确
cout << "---------------http--------------" << endl;
cout << req._inbuffer;
cout << "_method: " << req._method << endl;
cout << " _url: " << req._url << endl;
cout << " _httpversion: " << req._httpversion << endl;
cout << " _path: " << req._path << endl;
cout << "---------------end---------------" << endl;
// 状态行
string resline = "HTTP/1.1 200 ok\r\n";
// 响应报头
string rescontet = "contet-type: text/html\r\n";
// 空行
string resblank = "\r\n";
// 响应正文:html代码格式,浏览器自动识别
string body = "<html lang=\"en\"><head><meta charset=\"UTF-8\"><title>My html</title><h1>hello world</h1></head><body><p>这是我的网页</p></body></html>";
// 写回响应的数据,后续要发送回客户端
res._outbuffer += resline;
res._outbuffer += rescontet;
res._outbuffer += resblank;
res._outbuffer += body;
return true;
}
int main(int argc, char *argv[])
{
// 启动服务端不需要指定IP
if (argc != 2)
{
Usage(argv[0]);
exit(1);
}
uint16_t port = atoi(argv[1]);
unique_ptr<Server> server(new Server(func, port));
// 服务端初始化
server->Init();
// 服务端启动
server->start();
return 0;
}
结果分析

可以看到,用浏览器充当客户端后,浏览器会向服务器发起请求,因为代码里有写了将收到的数据打印,就按照格式将内容打印了出来。
从内容里可以看出客户端的系统和版本。服务端响应后发回数据到浏览器,因为代码中用html的代码去传送,所以浏览器自动识别显示出了网页。文章来源:https://www.toymoban.com/news/detail-632071.html
这篇文章主要是将如果能够通信的了,并没有业务逻辑。文章来源地址https://www.toymoban.com/news/detail-632071.html
到了这里,关于初识http协议,简单实现浏览器和服务器通信的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!