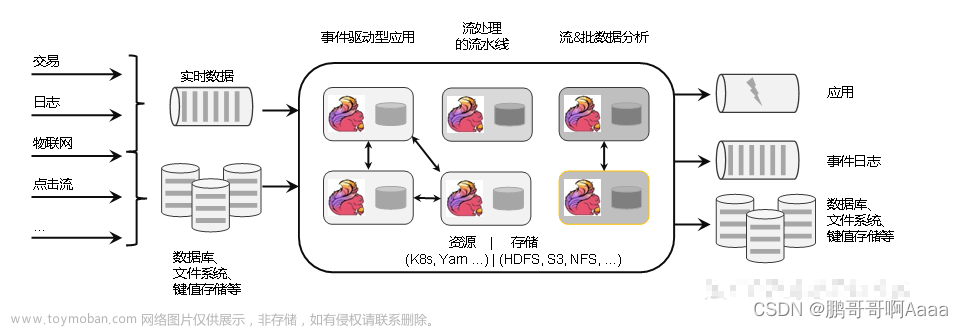
1.1 技术架构

- 应用框架层: 在API层之上构建的满足特定应用场景的计算框架,总体上分为流计算和批处理两类应用框架。
- API 层: Flink对外提供能力的接口 ,实现了面向流计算的DataStream API和面向批处理的DataSet API。
- 运行时层:Flink计算的核心
- DAG抽象:拆分作业→任务,建立数据流链路
- 数据处理:包含了开发层面、运行层面的数据处理抽象,例如 包含数据处理行为的封装、通用数据运算的实现(如Join、Filter、 Map等)。
- 容错:提供了集群级、应用级容错处理机制,保障集群、作业的可靠运行。
- 内存管理:内存管理、数据序列化:通过序列化,使用二进制方式在内存 中存储数据,避免JVM的垃圾回收带来的停顿问题。
- 数据交换:数据在计算任务之间的本地、跨网络传递。
- 部署层:集群部署
- Standalone模式:Flink安装在普通的Linux机器上,或者安装在K8s中,集群的资源由Flink自行管理。
- Yarn、Mesos、K8s等资源管理集群模式:Flink向资源集群申请资源,创建Flink集群。
- 云模式
- 连接器(Connector):Connector是Flink计算引擎与外部存储交互的IO抽象,是Source和Sink的具体实现。
1.2 运行架构
Flink集群采用Master-Slave架构:
Master的角色是JobManager, 负责集群和作业管理。
Slave的角色是TaskManager,负责执行计算任务。
JobManager和TaskManager是集群的进程,Flink客户端是在集群外部执行的进程,不是集群的一部分。

 文章来源:https://www.toymoban.com/news/detail-632451.html
文章来源:https://www.toymoban.com/news/detail-632451.html
文章来源地址https://www.toymoban.com/news/detail-632451.html
- JobManager:
- 拆分job→task
- 申请资源
- 分发任务
- 负责应用容错
- 跟踪执行状态
- TaskManager
- 执行子任务
- 管理subtask
到了这里,关于1.Flink概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!