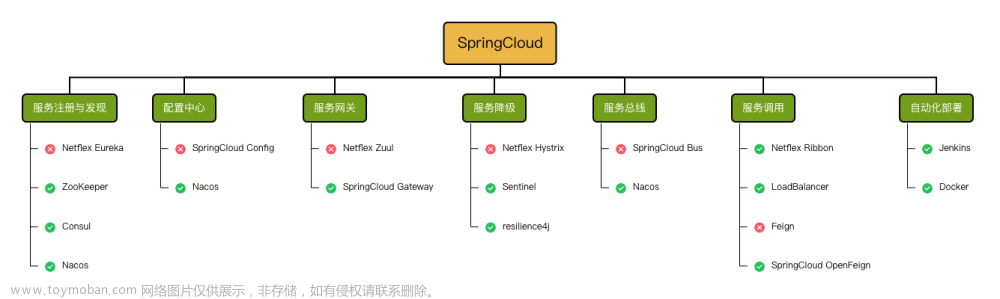
点击跳转:Docker安装MySQL、Redis、RabbitMQ、Elasticsearch、Nacos等常见服务全套(质量有保证,内容详情)
本文主要讨论在Elasticsearch和Kibana安装好合适版本的前提下,继续整合Zipkin。
1. 组件介绍
一般的,它们的工作过程是这样的:Spring Cloud微服务把调用链路的日志发送给Zipkin,Zipkin把数据发送给Elasticsearch进行保存,Kibana图形化显示Elasticsearch的数据。
Zipkin和Elaticsearch都可以单独使用,但是Zipkin是把数据保存在内存中的,重启后数据消失,所以通常跟Elasticsearch搭配把数据保存在Elasticsearch中,Kibana是可视化平台必须需要跟Elaticsearch搭配。
单独安装可参考Docker单独安装Elaticsearch、Docker单独安装Zipkin。
- **Elasticsearch:**Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
- Kibana:Kibana是一款适用于Elasticsearch的数据可视化和管理工具,可以提供实时的直方图、线形图、饼状图和地图。支持用户安全权限体系,支持各种纬度的插件,通常搭配Elasticsearch、Logstash一起使用。
- **Zipkin:**Zipkin是Twitter的一个开源项目,可以用来获取和分析Spring Cloud Sleuth中产生的请求链路跟踪日志,它提供了Web界面来帮助我们直观地查看请求链路跟踪信息。常用语微服务的调用链路跟踪。
2. 服务整合
2.1. 前提:安装好Elaticsearch和Kibana
在安装好Elaticsearch和Kibana基础上再来整合Zipkin。Docker下安装Elasticsearch和Kibana,Docker安装Kibana服务
- 安装启动Elasticsearch
#
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \
-e "discovery.type=single-node" \
-e "cluster.name=elasticsearch" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx1024m" \
-d "docker.elastic.co/elasticsearch/elasticsearch:6.6.2"
- 安装启动Kibana
#
docker run -d --name kibana -p 5601:5601 \
--link elasticsearch:elasticsearch \
kibana:6.6.2
2.2. 再整合Zipkin
Elasticsearch的版本和Kibana的版本要求一致,Zipkin的版本不做要求。安装启动好Elasticsearch和Kibana之后,继续把Zipkin整合进来。下面以Elasticsearch的6.6.2、Kibana的6.6.2、Zipkin为例来整合:
- Docker启动Zipkin连接Elasticsearch,如下:
docker run -d --name zipkin -p 9411:9411 \
-e STORAGE_TYPE=elasticsearch \
-e ES_HOSTS=http://192.168.1.6:9200 \
openzipkin/zipkin
注:其中的ip地址填写你自己的主机ip地址
- 查看Zipkin的日志
docker logs -f zipkin
- Zipkin页面访问地址:http://localhost:9411,点击查询几下

- 查看Elasticsearch日志有zipkin字样的也就基本没啥问题了
docker logs -f elasticsearch
 文章来源:https://www.toymoban.com/news/detail-632490.html
文章来源:https://www.toymoban.com/news/detail-632490.html
- 都安装好之后,下一次的启动顺序是有要求的,先要启动Elasticsearch,如下:
docker start elasticsearch
docker start zipkin
docker start kibana
- 如果发生了微服务间的分布式调用,通过Kibana也是可以看到调用链路的日志信息的,如下图:
 文章来源地址https://www.toymoban.com/news/detail-632490.html
文章来源地址https://www.toymoban.com/news/detail-632490.html
到了这里,关于【Docker】Docker+Zipkin+Elasticsearch+Kibana部署分布式链路追踪的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!