1、概述
- 归一化(Normalization) 方法:指的是把不同维度的特征(例如序列特征或者图像的特征图等)转换为相同或相似的尺度范围内的方法,比如把数据特征映射到[0, 1]或[−1, 1]区间内,或者映射为服从均值为0、方差为1的标准正态分布。
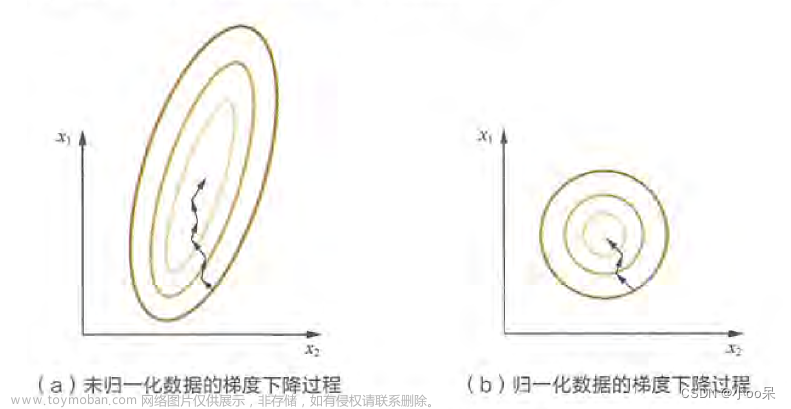
- 那为什么要进行归一化?
样本特征由于来源和度量单位的不同或者经过多个卷积层处理后导致不同来源或者不同卷积层的输入特征尺度存在较大差异,模型的优化方向可能会被尺度较大的特征所主导。而进行归一化可以使得尺度大致处于同一范围内,从而有利于模型的训练和优化。
- BN层(Batch Normalization):是在不同样本之间进行归一化。
- LN层(Layer Normalization):是在同一样本内部进行归一化。
- 以下的图简单展示了二者的区别:

参考链接:https://blog.csdn.net/qq_44397802/article/details/128452207
2、BN层
- 下图很清晰的解释了BN层:由于是Batch Normalization,那么简单来说,就是针对Batch中的不同样本之间求均值和标准差,再做归一化
1)如下图,针对神经元的输出进行BN,确定Batch size为N,但是不同类型样本的维度可能不一样(下图中维度为1,例如图像经过卷积以后维度为C × \times ×H × \times ×W)
2)不论维度为多少,各个样本之间的维度是相同的,因此针对不同样本之间的对应维度计算出均值和标准差,肯定与每个样本的维度相同(下图中,均值和标准差都为一维,对于图像,均值和标准差的维度为C × \times ×H × \times ×W)
3)针对每个神经元训练一组可学习的参数 γ \gamma γ和 β \beta β,用于对输出的每个响应值做缩放和平移。
4)注意:如果样本为一维,可学习参数的组数与输出的响应值的数量相等,也与神经元的个数相等;如果样本是图像,输入为N × \times ×C1 × \times ×H × \times ×W,卷积核个数为C2,那么输出为N × \times ×C2 × \times ×H × \times ×W,因此可学习参数的组数与输出通道数相等,为C2,也与卷积核个数相等。
5)所以简单来说,可学习参数的组数就与通道数相等。

3、LN层
-
一般来说,层归一化所做的就是,对于图像,即输入为N × \times ×C × \times ×H × \times ×W的特征图:在每个样本内部,计算所有像素点的均值和标准差,并针对每个像素点训练一组可学习参数 γ \gamma γ和 β \beta β,用于进行缩放和平移,以归一化到同一范围内。
-
如下图所示,针对的是一个样本中的所有通道内的所有像素。也就是说和Batch无关。
-
因此可学习参数的组数就等于C × \times ×H × \times ×W。

-
计算公式:
 文章来源:https://www.toymoban.com/news/detail-633201.html
文章来源:https://www.toymoban.com/news/detail-633201.html
4、Pytorch的实现
- BN层的实现:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
''
num_features:输入尺寸为(N,C,H,W),则该值为C
''
- LN层的实现:
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)
''
1)normalized_shape:归一化的尺寸,输入的尺寸必须符合:[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
如果为单个整数,则对最后一维进行归一化
2)elementwise_affine:是否具有可学习的参数,默认为True
''
- 如下为BN和LN层的实现,以及参数量的计算
import torch
from torch import nn
# NLP Example
batch, sentence_length, embedding_dim = 20, 5, 10
embedding = torch.randn(batch, sentence_length, embedding_dim)
layer_norm = nn.LayerNorm(embedding_dim)
print(layer_norm)
param_num = sum([param.numel() for param in layer_norm.parameters()])
print(param_num)
output_embed = layer_norm(embedding)
print(output_embed.shape)
- 输出为:
LayerNorm((10,), eps=1e-05, elementwise_affine=True)
20
torch.Size([20, 5, 10])
import torch
from torch import nn
# Image Example
N, C, H, W = 20, 5, 10, 10
input0 = torch.randn(N, C, H, W)
# Normalize over the last three dimensions (i.e. the channel and spatial dimensions)
layer_norm = nn.LayerNorm([C, H, W]) # 参数量为C*H*W*2
print(layer_norm)
param_num = sum([param.numel() for param in layer_norm.parameters()])
print(param_num)
output = layer_norm(input0)
print(output.shape)
input1 = torch.randn(N, C, H, W)
batch_norm = nn.BatchNorm2d(C) # 参数量为C*2
print(batch_norm)
param_num1 = sum([param.numel() for param in batch_norm.parameters()])
print(param_num1)
output1 = batch_norm(input1)
print(output1.shape)
- 输出为:
LayerNorm((5, 10, 10), eps=1e-05, elementwise_affine=True)
1000
torch.Size([20, 5, 10, 10])
BatchNorm2d(5, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
10
torch.Size([20, 5, 10, 10])
5、BN层和LN层的对比
- 简单对比如下:

参考链接:https://blog.csdn.net/hymn1993/article/details/122719043文章来源地址https://www.toymoban.com/news/detail-633201.html
到了这里,关于【深度学习中的批量归一化BN和层归一化LN】BN层(Batch Normalization)和LN层(Layer Normalization)的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![深度学习基础入门篇[七]:常用归一化算法、层次归一化算法、归一化和标准化区别于联系、应用案例场景分析。](https://imgs.yssmx.com/Uploads/2024/02/539080-1.png)