决策树算法
特征工程-特征提取
特征提取就是将任意数据转换为可用于机器学习的数字特征。计算机无法直接识别字符串,将字符串转换为机器可以读懂的数字特征,才能让计算机理解该字符串(特征)表达的意义。
主要分为:字典特征提取(特征离散化)、文本特征提取(文章中特征词汇出现的频次)。
字典特征提取
对类别数据进行转换。
计算机不能够识别直接传入的城市、温度数据,需要转换为0,1的编码才能够被计算机所识别。
用代码实现就为:
字典特征提取API
sklearn.feature_extraction.DictVectorizer(sparse=Ture,...)
DictVectorizer.fit_transform(X),X:字典或者包含字典的迭代器返回值,返回sparse矩阵
DictVectorizer.get_feature_names()返回类别名称

当数据量比较大的时候,使用sparse矩阵能更好的显示特征数据,更加的直观,没有显示0数据,更加节省内存。
文本特征提取
对文本数据进行特征值化,一篇文章中每个词语出现的频次。
文本特征提取API
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
返回词频矩阵。
CountVectorizer.fit_transform(X)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.get_feature_names()返回值:单词列表
英文文本特征提取实现
需求:体现以下段落的词汇出现的频次
[“Life is a never - ending road”,“I walk,walk,keep walking.”]
注意:
1.文本特征提取没有sparse参数,只能以默认的sparse矩阵接收
2.单个的字母,如I,a都不会统计
3.通过stop_words指定停用词

中文文本特征提取实现
需求:体现以下段落的词汇出现的频次
data = [‘这一次相遇’,‘美得彻骨,美得震颤,美得孤绝,美得惊艳。’]

需求:体现以下文本的词汇出现的频次
把文章中的词汇统一提取出来,去掉重复值后放到一个列表里,矩阵里显示的是每个词汇在每一行中出现的次数。根据词汇出现的多少可以把 文章归纳为跟词汇相关的文章。
Tf-idf文本特征提取
TF-IDF的主要思想是:如果某个词语或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类。
TF-IDF的作用:用于评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
Tf-idf文本特征提取公式:
t
f
i
d
f
i
,
j
=
t
f
i
,
j
∗
i
d
f
i
tfidf_{i,j}=tf_{i,j}*idf_i
tfidfi,j=tfi,j∗idfi
词频(term frequency ,tf):指的是某一个给定的词语在该文件中出现的频率
逆向文档频率(inverse document frequency ,idf):是一个词语普遍重要性的度量。某一个特定词语的idf,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到。
比如一篇文章由1000个字,而房地产出现了500次,房地产在该文章中出现的频率tf为:500/1000=0.5;房地产在1000份文件中出现过,文件的总数量为1000000,idf:
l
o
g
1000000
/
1000
=
3
log1000000/1000=3
log1000000/1000=3;tf-idf就为0.5*3=1.5。
不单单看某个词汇在某一篇文章中出现的次数(频率),还需要看它在整个文件集中出现的次数。
Tf-idf文本特征提取api
sklearn.feature_extraction.text.TfidfVectorizer


得到的是计算之后的tfidf的结果,没有文件集就是以行来进行分割的,以列表作为文件集,把每一行作为一个文件来进行处理。通过判断tfidf的大小来将某个词汇作为分割的重要词汇。
决策树算法API
分类API
sklearn.tree.DecisionTreeClassifier 决策树的分类算法器
- criterion:设置树的类型
- entropy:基于信息熵,也就是ID3算法,实际结果与C4.5相差不大
- gini:默认参数,相当于基尼系数。CART算法是基于基尼系数做属性划分的,
所以criterion=gini时,实际上执行的是CART算法。
- splitter:在构造树时,选择属性特征的原则,可以是best或random。默认是best,
- best代表在所有的特征中选择最好的,random代表在部分特征中选择最好的。
- max_depth:决策树的最大深度,可以控制决策树的深度来防止决策树过拟合。
- min_samples_split:当节点的样本数小于min_samples_split时,不再继续分裂,默认值为2
- min_samples_leaf:叶子节点需要的最小样本数。如果某叶子节点的数目小于这个阈值,则会和
兄弟节点一起被剪枝。可以为int、float类型。
- min_leaf_nodes:最大叶子节点数。int类型,默认情况下无需设置,特征不多时,无需设置。
特征比较多时,可以通过该属性防止过拟合。
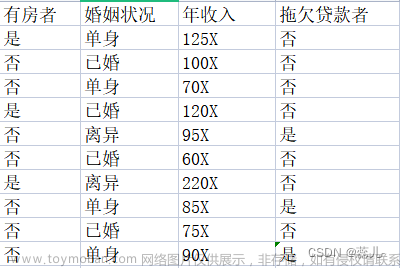
案例:泰坦尼克号乘客生存预测
需求:读取以下数据,预测生存率
train.csv 是训练数据集,包含特征信息和存活与否的标签;
test.csv 是测试数据集,只包含特征信息。
PassengerId:乘客编号;Survived:是否幸存;Pclass:船票等级;Name:姓名;Sex:性别;Age:年龄;
SibSp:亲戚数量(兄妹 配偶);Parch:亲戚数量(父母 子女);Ticket:船票号码;Fare:船票价格;Cabin:船舱;




通过对字段的分析进行处理,注意纯数字类型可以以均值进行替换,字符串类型的缺失值太大就直接删掉,缺失值比较少的话就用占比比较多的来填充,特征选择尽量与标签有关系的特征,将特征中的文本转换为对应的数值,最终进行训练模型,然后进行K折交叉验证。
决策树可视化
安装graphviz工具,下载地址:http://www.graphviz.org/download/
将graphviz添加到环境变量PATH中,然后通过pip install graphviz 安装graphviz库

生成的图片比较大,可以保存为pdf文件,效果如下 文章来源:https://www.toymoban.com/news/detail-633614.html
文章来源:https://www.toymoban.com/news/detail-633614.html
决策树解决回归问题
决策树基于ID3、C4.5、CART算法,回归问题是基于CART算法实现的,基尼系数。
导入boston房价的数据,以及决策树的回归问题接口,接下来要调用数据接口,获取数据集,然后获取特征名称、特征集、得到训练集和测试集的特征和标签,然后进行训练和预测。 文章来源地址https://www.toymoban.com/news/detail-633614.html
文章来源地址https://www.toymoban.com/news/detail-633614.html
到了这里,关于python机器学习(七)决策树(下) 特征工程、字典特征、文本特征、决策树算法API、可视化、解决回归问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!