计算机网络(4) --- 协议定制_哈里沃克的博客-CSDN博客协议定制https://blog.csdn.net/m0_63488627/article/details/132070683?spm=1001.2014.3001.5501
目录
1.http协议介绍
1.协议的延申
2.http协议介绍
3.URL
4.urlencode和urldecode
2.HTTP协议结构
1.引入
2.细节
3.HTTP协议的使用
1.协议
2.网页配置
3.HTTP请求方法
4.HTTP内容
1.HTTP状态码
1.常见的几个状态码
2.重定向的状态码
2.长链接
3.HTTP周边会话保持
cookie保存信息
session保存
5.基本工具
1.postman
2.fiddler
1.http协议介绍
1.协议的延申
1.协议不只有一种,我们能自己定制协议。那么区分协议的关键就是报头的内容,如果报头内容有标记表示是哪种协议,那么接收方就能判断是哪个协议,进而使用对应的协议规范
2.其实离不开序列化和业务逻辑,那么其实站在7层网络协议的视角来看。表示层其实对应的就是序列化和反序列化;而应用层就是业务处理。但是我们也知道由于不同的要求,我们必须设置出不同的业务逻辑和序列化的标准,那么也就意味着七层的会话层,表达层和应用层是无法统一化的。
2.http协议介绍
1.http是超文本传输协议,它是用于web的一种常见协议。该协议可以传输视频,语音,图片等等的结构数据,所以多用于网页处理
2.http协议是服务于应用层的
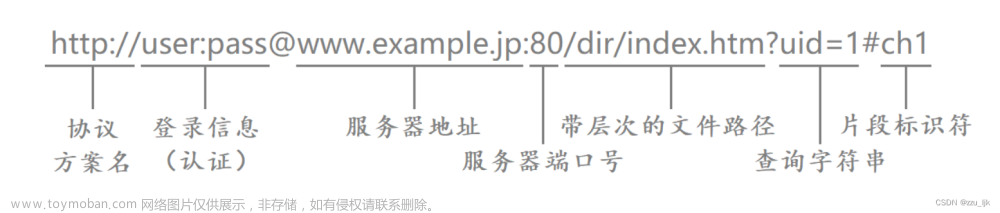
3.URL
1.URL开头为协议,能确认是哪个协议进行网络传输的
2.服务器地址,又叫做域名。该域名能找到指定的服务器IP地址
3.服务器端口,一般会被隐藏。http的端口号为80,https的端口号为443
4.端口号这里就已经确定是在哪个主机的哪个端口号下进行。而端口号后面表示在当前主机下的文件路径。第一个/表示web根目录,并不是指操作系统中的根目录。
5.那么URL的过程其实就是在指定的主机中指定位置根据具体的协议找到对应的资源。这些资源就是网络上看到一切数据,它们都在服务器的磁盘上存储着
4.urlencode和urldecode
1.像 / ? : 等这样的字符, 已经被url当做特殊意义理解了, 因此这些字符不能随意出现。那么某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义。
2.对特殊符号进行encode过程转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
3.把转码变为特殊符号过程为decode


2.HTTP协议结构
1.引入
1.以行为单位的协议
2.状态码,就是用于表示响应的状态:404->Not Found 200->OK
2.细节
1.由于以行为单位,我们轻松的读取完整的一行。第一行为请求行,我们知道了协议的具体获取方式,地址以及http的版本,随后循环式的获取行,知道获取到空行,那么我们得到了请求报头。请求报头中就有数据显示请求正文的大小,那么我们根据报头获取的数据就能得到正文。
2.序列化其实也简单。对于正文而言,其实是不需要做任何变化的。真正需要序列化的地方是报头,每读取一个报头后面加上\r\n,再不断的追加。最终得到序列化的报文。此时就可以组成协议了。

3.HTTP协议的使用
1.协议
void HandlerHttp(int sock) { // 1. 读到完整的http请求 // 2. 反序列化 // 3. httprequst, httpresponse, _func(req, resp) // 4. resp序列化 // 5. send char buffer[4096]; HttpRequest req; HttpResponse resp; size_t n = recv(sock, buffer, sizeof(buffer) - 1, 0); // 大概率我们直接就能读取到完整的http请求 if (n > 0) { buffer[n] = 0; req.inbuffer = buffer; _func(req, resp); // req -> resp send(sock, resp.outbuffer.c_str(), resp.outbuffer.size(), 0); } }class HttpRequest { public: std::string inbuffer; std::string reqline; std::vector<std::string> reqheader; std::string body; std::string method; std::string url; std::string httpversion; std::string path; }; class HttpResponse { public: std::string outbuffer; }; bool Get(const HttpRequest &req, HttpResponse &resp) { cout << "----------------------http start---------------------------" << endl; cout << req.inbuffer << std::endl; cout << "----------------------http end---------------------------" << endl; }编写一段接收服务器接收http协议,并且打印的逻辑。当我们访问当前的服务器是。结果回传出客户端打来http协议。
GET方法,在/web根目录下,HTTP/1.1版本的协议
2.网页配置
1.配置初始的web首页:就是在文件中创建一个wwwroot文件,该文件可以放入各种网页所需要的资源。
2.wwwroot中,index.html文件为默认的首页,404.html文件显示无法访问的网页
3.一个用户看到的网页是多个资源组合而成的,所以我们要得到一整张完整的网页,服务端会发起多次请求。
3.HTTP请求方法
1.交互web有两种行为:1.获取资源 2.上传资源(交互)
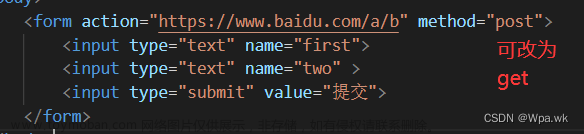
2.我们进行数据提交的时候,其实是前端要form表单提交的,浏览器会自动将form表单中的内容转换成为GET/POST方法请求。
3.GET方法会把参数拼接到URL上提交给服务器;POST方法提交参数通过正文提参。POST是正文提参,一般用户看不到,私密性比较好。但是私密性不代表安全,GET和POST都不安全。POST通过正文,所以可以传入比较大的资源。
4.GET在内部服务器端可以写代码,一旦得到GET请求,可以分离出url和参数,之后我们就可以对参数进行服务操作了;而POST本来就分离的,那么自然可以在正文里找到参数进行服务操作

4.HTTP内容
1.HTTP状态码
1.常见的几个状态码
1.200:OK -- 正常运行
2.404:Not Found -- 用户错误
3.403:Forbidden -- 拒绝客户访问
4.503:Bad Gateway -- 服务端错误(创建进程线程等任务失败)
2.重定向的状态码
3开头的状态码:是关于重定向的状态码。其原理就是先通过url访问服务端,服务端发送给客户端3开头对应的状态码,随后又将设置好的新url传送给客户端,客户端跳转到新的url处。301:永久重定向,跳转旧网页就会访问新网页;307临时重定向,一般用于登录界面之类。
2.长链接
1.其实我们看到的网页是一堆的资源组成的,那么也就意味着需要多次的http请求将整个完整的浏览器进行渲染和优化
2.http是基于tcp套接字的,tcp是面向链接的,也就是说http多次请求tcp就多次链接。那么就会出现频繁创建链接的问题
3.所谓的client和server都需要长链接,这种链接是在获取一大堆资源时,通过一条链接完成的。
4.协议中出现connection:keep-alive说明是长链接。
3.HTTP周边会话保持
1.会话保持严格意义不是http协议天然具备的,是后面使用发现需要的
2.访问指定浏览器一个网页,该网页需要登录,一旦关闭后又重新开启网页,网页依然会有登录的记录。我们换一个浏览器,那么就没有登录的记录了,不能自己登录。
3.http只在乎当前这一次的请求,那么也就意味着之前或者后来的请求有什么状态,就当前而言是无法知道的。但是用户需要这种历史记录!
4.会话保持:http协议是无状态的,但是用户需要,因为用户查看新的网页是常规操作,那么新页面也就无法识别用户,为了让用户一经登录,整个网站按照用户身份进行随意的访问的功能就是会话保持
cookie保存信息
1.浏览器在登录时,我们将所有的信息写入时,会创建一个空间存储当前的信息。那么服务端在用户访问时需要不断判断身份,随后就能拿到浏览器保存的信息进行身份认证,这样就能够达到目的。该浏览器记录的功能为cookie技术。
2.cookie分为文件级别和内存级别。关闭浏览器重新开启依然能保存信息是文件级别的cookie;但是关闭后就没有信息的就是内存级别,因为浏览器是进程,关闭后进程的信息就会被释放。
3.缺点:由于cookie保存的功能,一旦有木马攻击用户,那么此时黑客就拥有了用户的登录信息,此时就能像用户一样进行登录。换句话说我们被盗号了。造成信息泄漏和他人使用。
session保存
1.根据上面的缺点,归根到底是因为信息由用户管理出现的问题。所以将用户的信息在输入时保存到 服务器中,服务器生成唯一的session文件进行保存,每一个访问浏览器返回唯一的session id对应session文件。一旦浏览器访问,则需要把http和session id一起发送过去,随后调取服务器内部session文件,避免了信息泄漏。
2.为了防止木马拿去session id以达到访问的效果,服务器设置了cookie访问时间,如果cookie在其他地方没一分钟就会有措施。只要不符合就将session id失效,这样只有有密码的人才能访问。
3.以及一些长时间未登录等的用户行为,IP地址变换等等的情况都是保护个人信息的措施。
4.手机保护,人脸识别等等也可以作为确认个人信息的能力

5.基本工具
1.postman
格式化处理的网页
文章来源:https://www.toymoban.com/news/detail-633708.html
2.fiddler
抓包本地http工具,一般用于检查http请求的正确与否文章来源地址https://www.toymoban.com/news/detail-633708.html

到了这里,关于计算机网络(5) --- http协议的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!