1.实现原理
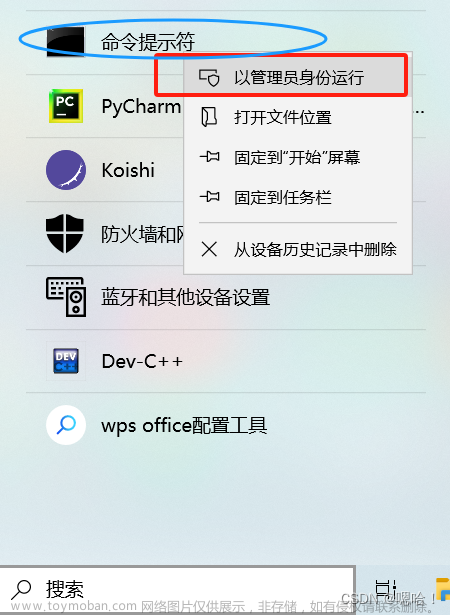
- 首先,我们需要来到西瓜视频的官网,链接为:西瓜视频,随便点击其中一个视频进入,点击电脑键盘的F12来到开发者模式,按ctrl+F进行搜索,输入video,如下:

- 我们可以发现,这里有一个视频链接,我们点击这个链接进入,依旧按电脑F12键来到开发者模式,继续搜索video,可以发现,这里直接有视频的下载链接,如下:

- 我们是不是只要运用代码就可以找到视频的下载链接呢?不过,由于上述图片这些视频下载链接是动态加载的,这里需要用到selenium模块哈!不懂这个模块的 读者可以看看小编之前写的博客哈!这里小编给出一篇博客,博客链接为:selenium模块太强大了,网易云音乐都可下载

2.程序代码
程序代码如下:
import re
from selenium import webdriver
# url="https://www.ixigua.com/6982149651281478152?logTag=cc6bf98fd0f8fe35fe0e"
url=input("输入视频链接:")
group_id=re.findall('https://www.ixigua.com/(.*)\?logTag=.*',url)
url='https://www.ixigua.com/embed?group_id='+group_id[0]
# 进入浏览器设置
options = webdriver.ChromeOptions()
# 设置中文
options.add_argument('lang=zh_CN.UTF-8')
# 更换头部
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"')
driver=webdriver.Chrome(options=options)
driver.get(url=url)
driver.implicitly_wait(5)
infos=driver.find_elements_by_xpath("//xg-definition/ul/li")
for info in infos[:-1]:
print(info.get_attribute("definition"))
print('http:'+info.get_attribute("url"))
- 别看总共代码就这么点,如果不知道其中的原理,或许这么点代码都敲不出来呢?
- 由于视频下载直接用代码实现可能需要较长的时间,使用这里直接把视频的下载链接给出来哈!之后读者就可以拿视频下载链接去浏览器上下载即可。

3.运行结果

 文章来源:https://www.toymoban.com/news/detail-633916.html
文章来源:https://www.toymoban.com/news/detail-633916.html
Python爬虫下载西瓜视频文章来源地址https://www.toymoban.com/news/detail-633916.html
到了这里,关于Python爬虫:给我一个链接,西瓜视频随便下载的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!