LeNet卷积神经网络-笔记

手写分析LeNet网三卷积运算和两池化加两全连接层计算分析
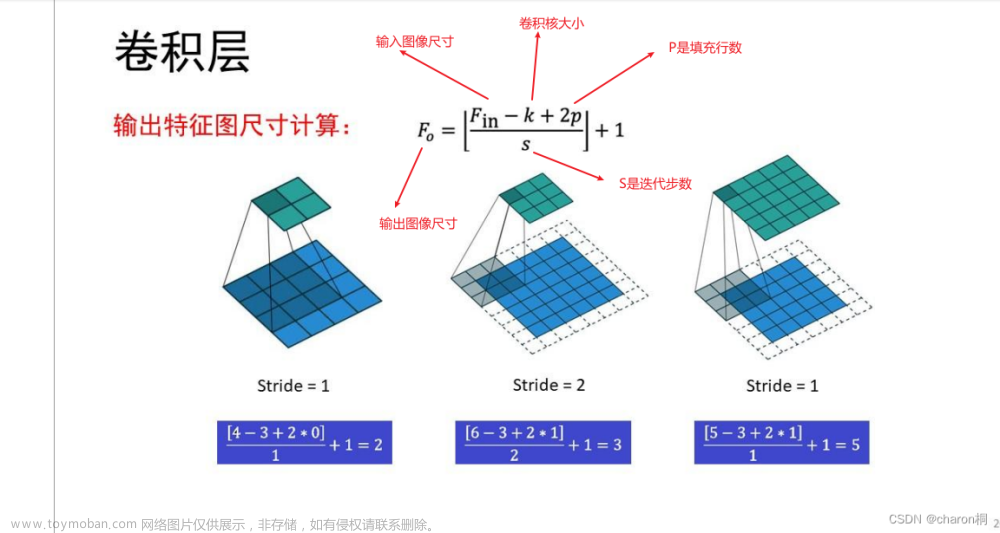
修正上图中H,W的计算公式为下面格式
基于paddle飞桨框架构建测试代码
#输出结果为:
#[validation] accuracy/loss: 0.9530/0.1516
#这里准确率为95.3%
#通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。文章来源:https://www.toymoban.com/news/detail-634023.html
详细源代码如下所示:文章来源地址https://www.toymoban.com/news/detail-634023.html
# 导入需要的包
import paddle
import numpy as np
from paddle.nn import Conv2D, MaxPool2D, Linear
## 组网
import paddle.nn.functional as F
# 定义 LeNet 网络结构
#==============================================================================
class LeNet(paddle.nn.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层
# 创建第1个卷积层
self.conv1 = Conv2D(in_channels=1, out_channels=6, kernel_size=5)
self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)
# 尺寸的逻辑:池化层未改变通道数;当前通道数为6
# 创建第2个卷积层
self.conv2 = Conv2D(in_channels=6, out_channels=16, kernel_size=5)
self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)
# 创建第3个卷积层
self.conv3 = Conv2D(in_channels=16, out_channels=120, kernel_size=4)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
# 输入size是[28,28],经过三次卷积和两次池化之后,C*H*W等于120
self.fc1 = Linear(in_features=120, out_features=64)
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc2 = Linear(in_features=64, out_features=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
# 每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
x = F.sigmoid(x)
x = self.max_pool1(x)
x = F.sigmoid(x)
x = self.conv2(x)
x = self.max_pool2(x)
x = self.conv3(x)
# 尺寸的逻辑:输入层将数据拉平[B,C,H,W] -> [B,C*H*W]
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.sigmoid(x)
x = self.fc2(x)
return x
#==========================================================================================
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')
# 创建LeNet类的实例,指定模型名称和分类的类别数目
model = LeNet(num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(model.sublayers())
print(x.shape)
x = paddle.to_tensor(x)
print(x.shape)
for item in model.sublayers():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
try:
x = item(x)
except:
x = paddle.reshape(x, [x.shape[0], -1])
x = item(x)
if len(item.parameters())==2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)
else:
# 池化层没有参数
print(item.full_name(), x.shape)
#
'''
#显示子图层列表model.sublayers()
[
Conv2D(1, 6, kernel_size=[5, 5], data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0),
Conv2D(6, 16, kernel_size=[5, 5], data_format=NCHW),
MaxPool2D(kernel_size=2, stride=2, padding=0),
Conv2D(16, 120, kernel_size=[4, 4], data_format=NCHW),
Linear(in_features=120, out_features=64, dtype=float32),
Linear(in_features=64, out_features=10, dtype=float32)
]
'''
# -*- coding: utf-8 -*-
# LeNet 识别手写数字
import os
import random
import paddle
import numpy as np
import paddle
from paddle.vision.transforms import ToTensor
from paddle.vision.datasets import MNIST
# 定义训练过程
def train(model, opt, train_loader, valid_loader):
# 开启0号GPU训练
use_gpu = True
paddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')
print('start training ... ')
model.train()
for epoch in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
img = data[0]
label = data[1]
# 计算模型输出
logits = model(img)
# 计算损失函数
loss_func = paddle.nn.CrossEntropyLoss(reduction='none')
loss = loss_func(logits, label)
avg_loss = paddle.mean(loss)
if batch_id % 2000 == 0:
print("epoch: {}, batch_id: {}, loss is: {:.4f}".format(epoch, batch_id, float(avg_loss.numpy())))
avg_loss.backward()
opt.step()
opt.clear_grad()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
img = data[0]
label = data[1]
# 计算模型输出
logits = model(img)
pred = F.softmax(logits)
# 计算损失函数
loss_func = paddle.nn.CrossEntropyLoss(reduction='none')
loss = loss_func(logits, label)
acc = paddle.metric.accuracy(pred, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {:.4f}/{:.4f}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# 保存模型参数
paddle.save(model.state_dict(), 'mnist_LeNet.pdparams')
# 创建模型
model = LeNet(num_classes=10)
# 设置迭代轮数
EPOCH_NUM = 5
# 设置优化器为Momentum,学习率为0.001
opt = paddle.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameters=model.parameters())
# 定义数据读取器
train_loader = paddle.io.DataLoader(MNIST(mode='train', transform=ToTensor()), batch_size=10, shuffle=True)
valid_loader = paddle.io.DataLoader(MNIST(mode='test', transform=ToTensor()), batch_size=10)
# 启动训练过程
train(model, opt, train_loader, valid_loader)
#输出结果为:
#[validation] accuracy/loss: 0.9530/0.1516
#这里准确率为95.3%
#通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。
到了这里,关于LeNet卷积神经网络-笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!