系列文章链接
数据解读参考:数据基础:多维时序数据集简介
论文一:2022 Anomaly Transformer:异常分数预测
论文二:2022 TransAD:异常分数预测
论文三:2023 TimesNet:基于卷积的多任务模型
论文链接:TransAD.pdf
代码库链接:https://github.com/imperial-qore/TranAD文章来源:https://www.toymoban.com/news/detail-634698.html
这篇文章是基于多变量数据的异常检测,也是基于transformer的一种深度学习方法,作者对前人的工作存在以下两点思考:文章来源地址https://www.toymoban.com/news/detail-634698.html
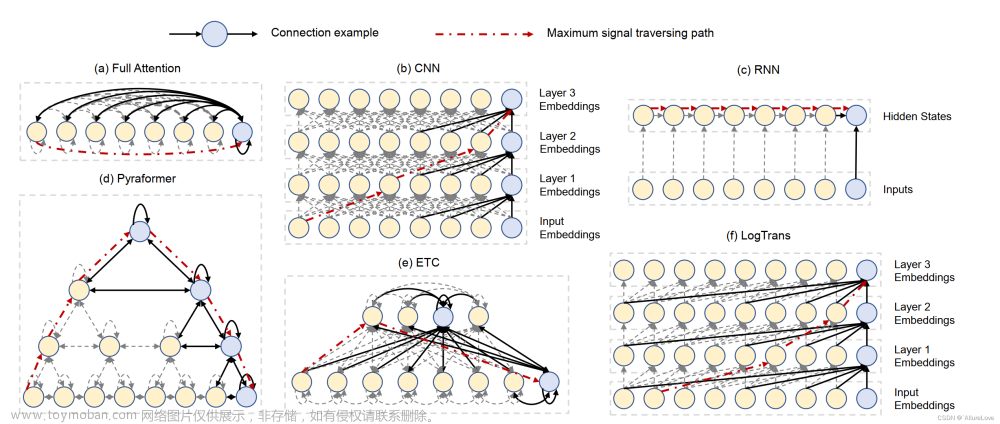
- 在常用的基于深度学习的异常检测方案中,都是采用一定的固定窗口进行样本数据提取,如对于一个时间点位,会提取历史窗口长度为100的数据作为当前点位的数据,然后采用LSTM编码进行数据向量化表征,但是这种表征方式存在缺陷,就是忽略了数据的长期周期性、季节性等规律特性。但是如果要加入这些数据,时序原始数据表征长度就会过长,很难进行建模。

- 真实数据和重构的数据差异比较大时有两种情况:(1)原始数据的噪声;(2)异常事件引起数据异常;而模型需要关注的应该是这些时候的差异性;
 针对上述思考,论文作者提出了两个创新模块:
针对上述思考,论文作者提出了两个创新模块: - 基于Transformer的时序数据建模;
- 基于two-phase inference的数据重构;


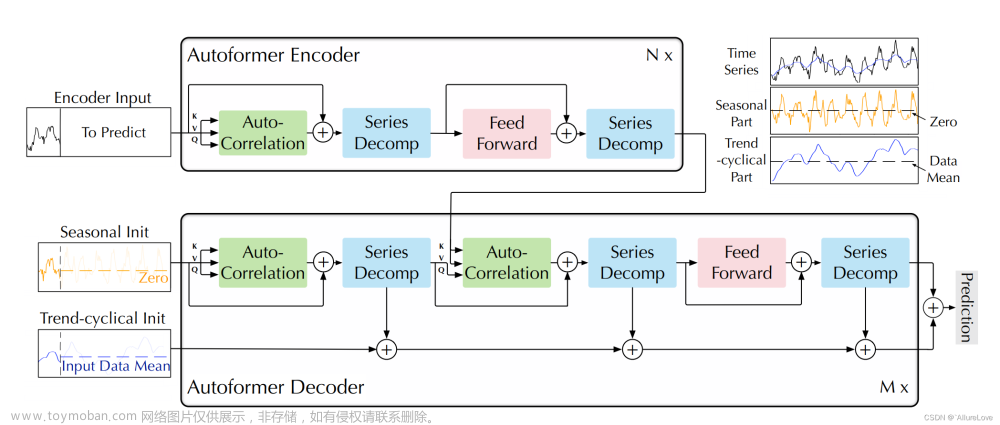
整体架构如上图所示,通过编解码的结构进行网络架构搭建,具体的模块细节包含下面几个:
- Phase1对应的粗略重建:如下图所示,其中
W
W
W表示时序数据邻近窗口点位的时序数据,
C
C
C表示能够获取周期性、季节性特性的长时段时间序列,截至点为当前时间点,
0
⃗
\vec 0
0表示的是趋势序列输入的数据权重,在第一个阶段中是和完整序列
C
C
C大小相匹配的全0向量。在对窗口数据
W
W
W和完整序列
C
C
C采用多头注意力进行编码后,将完整序列的编码结果和窗口编码结果采用注意力机制进行计算,并进行解码,重构出两个输出结果
O
1
O_1
O1和
O
2
O_2
O2。关于如何进行多头注意力机制的建模就不展开了,可以参考原文。

- Phase2对应的引导重构:对于输出结果
O
1
O_1
O1、
O
2
O_2
O2而言,构建重构损失
∣
∣
O
1
−
W
∣
∣
2
||O_1-W||_2
∣∣O1−W∣∣2
∣
∣
O
2
−
W
∣
∣
2
||O_2-W||_2
∣∣O2−W∣∣2用于反馈给网络,
O
1
O_1
O1反馈用于更新网络的focus score。更新好focus score后,对于Decoder1而言,目标是使得重构结果和目标间的差距更小,对于Decoder2而言,目标是使得重构结果和目标间的差距更大,所以对于两个解码器的两个阶段而言,设计了以下损失构建方式:
L
1
=
ϵ
−
n
∣
∣
O
1
−
W
∣
∣
2
+
(
1
−
ϵ
−
n
)
∣
∣
O
^
2
−
W
∣
∣
2
L_1=\epsilon^{-n}||O_1-W||_2+(1-\epsilon^{-n})||\hat O_2-W||_2
L1=ϵ−n∣∣O1−W∣∣2+(1−ϵ−n)∣∣O^2−W∣∣2
L
2
=
ϵ
−
n
∣
∣
O
2
−
W
∣
∣
2
+
(
1
−
ϵ
−
n
)
∣
∣
O
^
2
−
W
∣
∣
2
L_2=\epsilon^{-n}||O_2-W||_2+(1-\epsilon^{-n})||\hat O_2-W||_2
L2=ϵ−n∣∣O2−W∣∣2+(1−ϵ−n)∣∣O^2−W∣∣2

- 异常得分计算: 1 2 ∣ ∣ O 1 − W ^ ∣ ∣ 2 + 1 2 ∣ ∣ O ^ 2 − W ^ ∣ ∣ 2 \frac{1}{2}||O_1-\hat W||_2+\frac{1}{2}||\hat O_2-\hat W||_2 21∣∣O1−W^∣∣2+21∣∣O^2−W^∣∣2超过阈值的则认为是异常;
到了这里,关于【论文阅读】基于深度学习的时序异常检测——TransAD的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!