关于Java连接Hive,Spark等服务的Kerberos工具类封装
idea连接服务器的hive等相关服务的kerberos认证注意事项
- idea 本地配置,连接服务器;进行kerberos认证,连接hive、HDFS、Spark等服务注意事项:
- 本地idea连接Hadoop,需要在本地安装Hadoop的window工具
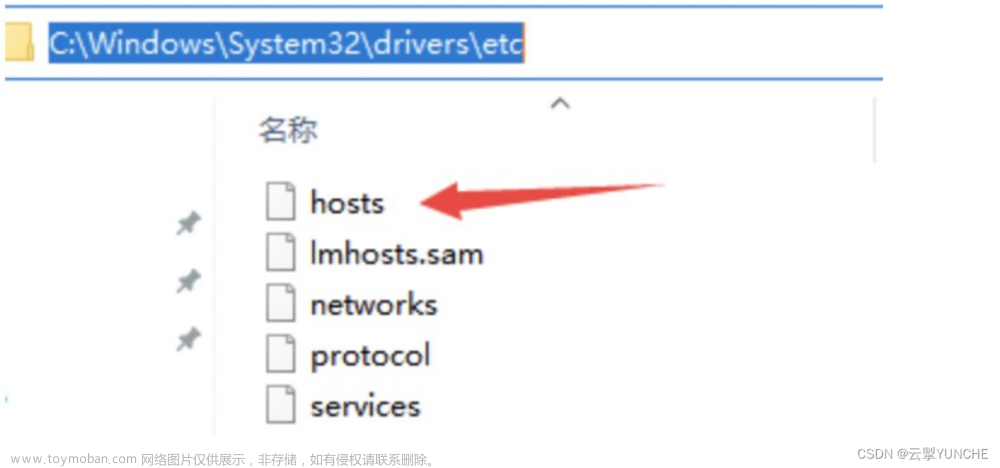
hadoop-3.1.1-winutils-master,配置环境变量 - 配置hosts主机名映射
- kerberos认证需要在idea工作目录所在的磁盘的根目录下创建对应的文件夹把keytab放到该目录下,方便认证。
- krb5.conf放到对应的目录,如:system.properties中配置了krbConf=/etc/krb5.conf;在项目所在的磁盘根目录下,创建对应的etc目录在下面放配置文件krb5.conf。如:我的idea工作空间在D盘那么就在D盘根目录下创建。
- 在resource目录下放置集群的配置文件:hdfs-site.xml、core-site.xml、mapred-site.xml、yarn-site.xml、hive-site.xml配置文件。
- 认证注意事项:如果最终是hive用户认证的,那么生成的文件默认为hive的家目录;如果是hdfs用户认证的,生成的文件默认为hdfs的家目录。
properties工具类
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.util.Properties;
/**
* properties工具类
*/
public class PropertiesUtil {
private static Log log =LogFactory.getLog(PropertiesUtil.class);
private static Properties props=new Properties();
private static String propertyFileName = "/system.properties";
static {
try {
if (props.size() == 0) {
log.info("Start read the constv.properties file");
InputStream input = PropertiesUtil.class.getResourceAsStream(propertyFileName);
props.load(input);
input.close();
}
}catch (IOException ioe) {
log.error(ioe.getMessage());
log.debug(ioe);
}
}
public static Integer getRequiredIntegerProperty(String propertyName){
String str =getRequiredStringProperty(propertyName);
return Integer.parseInt(str);
}
public static String getRequiredStringProperty(String propertyName){
String str =getStringProperty(propertyName, null);
if (StringUtils.isBlank(str)){
throw new RuntimeException(propertyName+"not is property file"+ propertyFileName);
}
return str;
}
public static String getStringProperty(String propertyName,String defaultValue){
if (props.containsKey(propertyName) ==true){
return (String) props.get(propertyName);
}
return defaultValue;
}
public static String getIntegerProperty(String propertyName,String defaultValue, String encoding){
if (props.containsKey(propertyName) ==true){
//编码转换,从ISO8859-1转向指定的编码
String value= (String) props.get(propertyName);
try{
value = new String(value.getBytes("ISO8859-1"), encoding);
}catch (UnsupportedEncodingException e){
e.printStackTrace();
}
return value;
}
return defaultValue;
}
}
线程池调度工具类
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
public class ScheduledThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber =new AtomicInteger(1);
private final String namePrefix;
public ScheduledThreadFactory() {
SecurityManager s=System.getSecurityManager();
group = (s != null) ? s.getThreadGroup(): Thread.currentThread().getThreadGroup();
namePrefix = "Scheduled Pool-" + poolNumber.getAndIncrement()+"-Thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group,r,namePrefix+threadNumber.getAndIncrement());
/*
* 设置为守护进程,所在的jar执行完就退出,如果不是守护进程,在linux运行时,即使业务进程执行完成,这个认证进程也不会关闭。
* */
t.setDaemon(true);
//这个是线程默认的优先级 Thread.NORM_PRIORITY
if (t.getPriority() != Thread.NORM_PRIORITY){
t.setPriority(Thread.NORM_PRIORITY);
}
return t;
}
}
Kerberos认证工具类
import com.xxxx.utils.PropertiesUtil;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.IOException;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class KerberosAuthen {
private static ScheduledExecutorService scheduledExecutor = Executors.newScheduledThreadPool(1,new ScheduledThreadFactory());
public static void kerberosAuthen(){
krbAuth();
/*
* 每5分钟执行一次向kerberos进行认证的方法
* */
scheduledExecutor.scheduleAtFixedRate(()->krbAuth(),5L,5L, TimeUnit.MINUTES);
}
/*
向kerberos认证
* */
private static void krbAuth(){
String krbConf = PropertiesUtil.getRequiredStringProperty("krb.conf");
String krbKeytab = PropertiesUtil.getRequiredStringProperty("hive.krb.keytab");
String krbPrincipal = PropertiesUtil.getRequiredStringProperty("hive.krb.principal");
if (StringUtils.isEmpty(krbConf) || StringUtils.isEmpty(krbKeytab) || StringUtils.isEmpty(krbPrincipal)){
throw new RuntimeException("------------------------Kerberos认证文件不存在--------------------------");
}
//java 程序本身自带kerberos客户端,需要krbConf. 可以进行当前节点的kerberos认证
System.setProperty("java.security.krb5.conf",krbConf);
Configuration configuration = new Configuration();
configuration.set("hadoop.security.authorization","kerberos");
//指定keytab文件和principal,为当前java程序配置认证
configuration.set("keytab.file",krbKeytab);
configuration.setBoolean("hadoop.security.authorization",true);
configuration.set("kerberos.principal",krbPrincipal) ;
try {
UserGroupInformation.setConfiguration(configuration);
UserGroupInformation.loginUserFromKeytab(krbPrincipal,krbKeytab);
}catch (IOException ioe){
System.err.println(ioe.getMessage());
}
}
}
properties配置文件
- conf.properties示例:
krb.conf=/etc/krb5.conf
hive.krb.key=/opt/keytabs/hive.keytab
hive.krb.principal=hive@Example.COM
文章来源地址https://www.toymoban.com/news/detail-635132.html
文章来源:https://www.toymoban.com/news/detail-635132.html
到了这里,关于关于Java连接Hive,Spark等服务的Kerberos工具类封装的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!