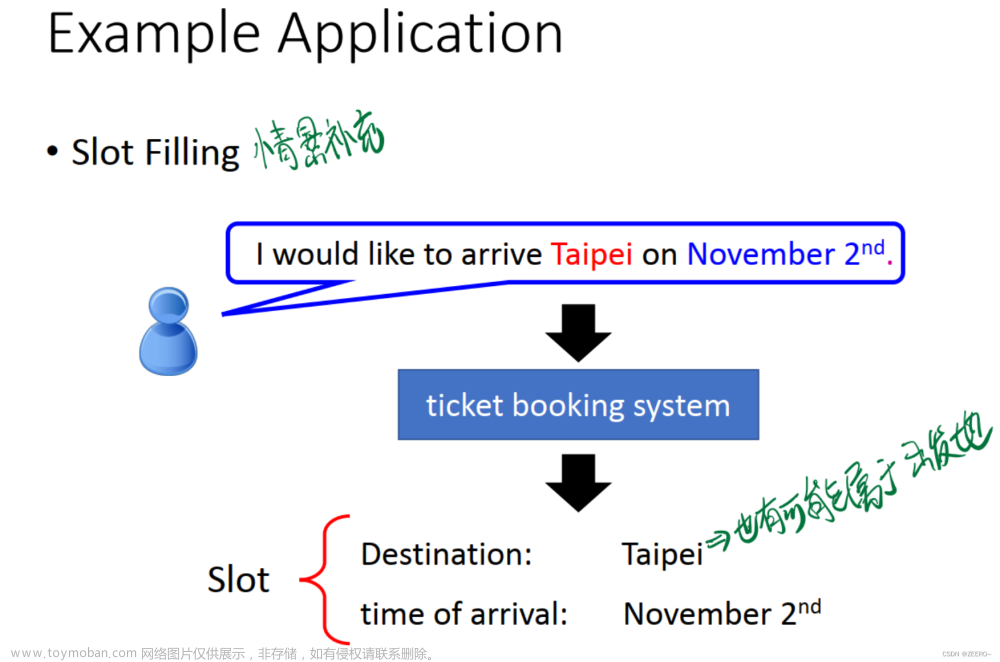
1 策略1 “各个击破”——autoregressive model
“各个击破”——一个一个生成出来

2 策略2 : “一次到位”——non-autoregressve model
一步到位,全部生成出来

2.1 non-autoregressive model 如何确定长度?

- 两种策略
- 策略1:始终生成固定长度(比如100),如果出现end,那么end后面的部分直接扔掉
- 策略2:首先输出一个数字n,表示之后我们要输出多长,然后输出n长度的句子
3 二者的对比

3.1 生成速度

- 一般文字相关的任务考虑“各个击破”,而影像相关的任务考虑“一次到位”
- 因为影像每一帧都有很多的像素,如果“各个击破”,那么效率太慢了
3.2 生成品质

- “各个击破”的话是先根据概率生成“老”,然后将“老”放入输入,生成下一个字的概率分布,再sample,这样得到“老师”的概率会很大
- “一次到位”的话同时生成所有字的概率,同时sample,得到有问题的词组的概率会很大
4 二者的结合
4.1 语音合成
 文章来源:https://www.toymoban.com/news/detail-635370.html
文章来源:https://www.toymoban.com/news/detail-635370.html
4.2 类diffusion model的思路
- 好多次“一次到位”联合使用
- 每经过一次“一次到位”,图像就会更清楚一点
- ——>图像会越来越清楚
视频来源:李宏毅讲解生成式AI(大模型,文本,图像)_哔哩哔哩_bilibili文章来源地址https://www.toymoban.com/news/detail-635370.html
到了这里,关于机器学习笔记:李宏毅ChatGPT:生成式学习的两种策略的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!