我们都知道C++其实就是C语言的升级,那么在“升级”最初阶段就是要对一些在C语言中不足的语法进行改进,这些改进能让我们省很多的力并且代码写起来也比较简洁。
一、命名空间
1、为什么要引入命名空间?
C++引入命名空间主要是为了弥补在C语言中不能存在同名变量或函数的这个语法漏洞。
我们知道在C语言中,相同名称或变量是不能同时存在的:
如上面的例子中,编译器就会报错。
2、命名空间的基本用法
为了解决这个问题,C++就引入了命名空间,命名空间的主要语法如下:
namespace _name {
// 成员
int a = 1;
// 成员
double b = 1.1;
}
命名空间使用,namespace这个关键自定义,在命名空间中我们可以定义各种成员,我们几乎可以定义所有的东西:变量、函数、结构体(类)、命名空间(嵌套定义)……
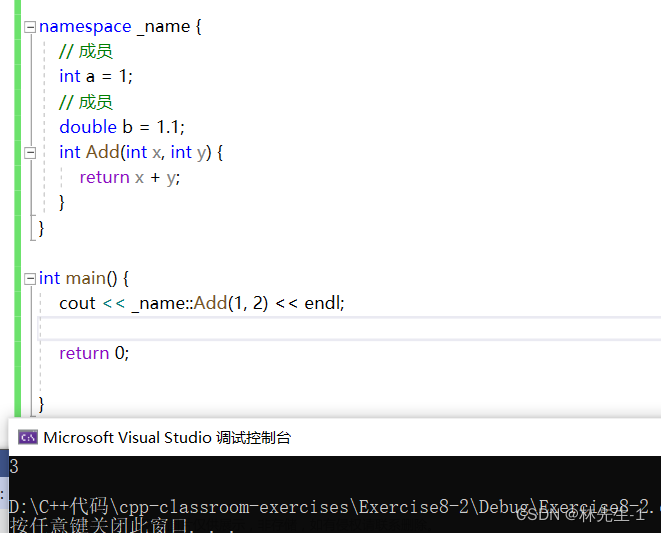
而当我们要在命名空间外使用这些成员时,我就必须得加上一个“域作用限定符”:
_name::
而如果不加上,就会报错: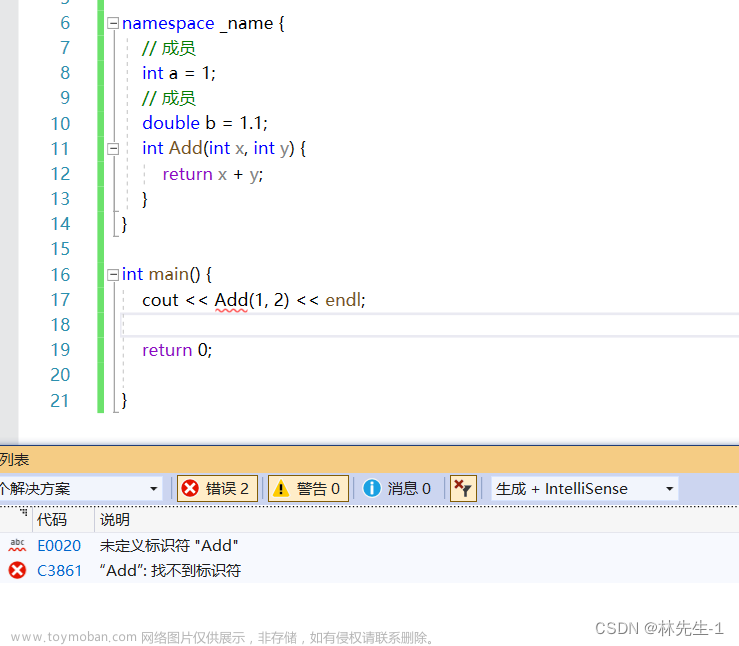
这是因为C++的编译器也和C语言的编译器一样默认只会在全局去寻找。
这样我们就可以同时定义两个同名函数了,比如在全局也有一个同名的Add函数: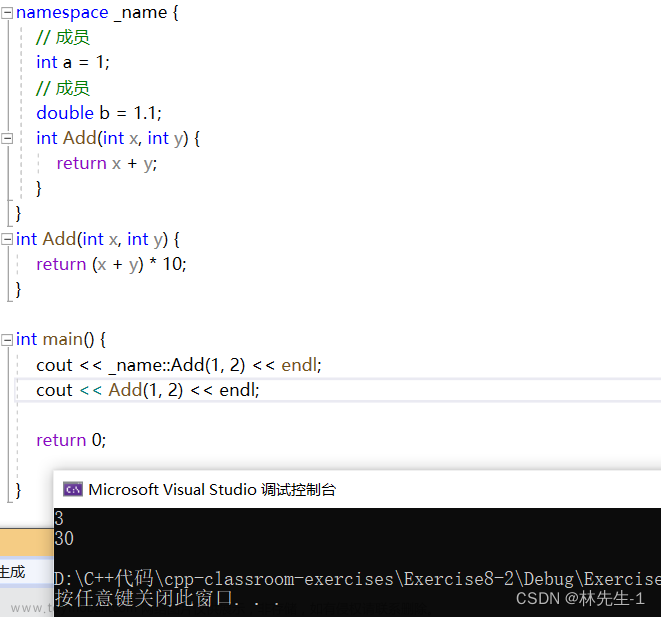
3、展开命名空间
而如果我们不想每次使用都要加上与作用限定符或者某一个成员被使用的次数太过频繁,我们就可以将命名空间进行展开:
全部展开
using namespace _name;

当然,当我们展命名空间后,也是不能存在同名函数的,因为编译器会依次在全局和命名空间中查找,如果找到两个同名函数,就会存在歧义:
上面展示的是将命名空间全部展开,而如果我们只是经常要用到命名空间中的某一个成员,而并不想展开其他成员,那我们就可以使用部分展开
using _name::Add;
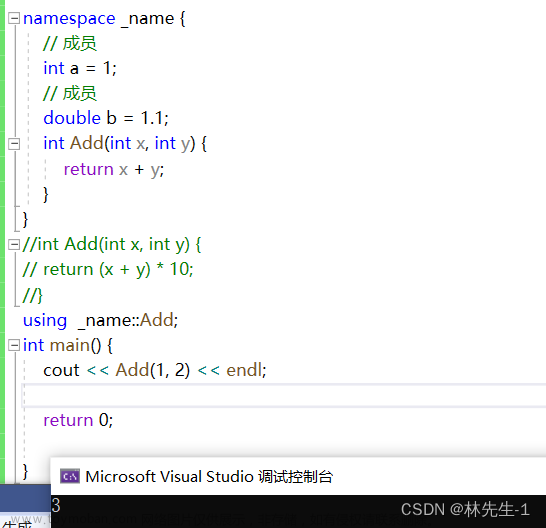
而对其他成员,我们依然要加上域作用限定符:
4、命名空间的套娃
在命名空间中也是可以再定义命名空间的:
这样,我们就可以再定义很多的同名变量和函数了。
在使用的时候其实也和C语言的指针解引用一样,再加上一个域作用限定符就行了:
理论上我们可以嵌套无数层的命名空间,但在实际应用中我们最多就嵌套两层就足够了。
5、命名空间的自动合并
那么问题来了,如果定义了同名的命名空间编译器会不会报错呢?
答案是不会的,当我们定义了多个命名空间,它们会自动合并:
二、缺省参数
1、为什么要引入缺省参数?
在C语言中,当我们要对完成某些功能的函数,进行传参时,总是会遇到不知道具体参数要传多少的情况,比如我们要写一个栈,我们想要在初始化接口中给栈分配一个空间,因为场景的不同,我们总不能具体知道要分配多少空间:
typedef struct Stack {
int* array;
int size;
int capacity;
} Stack;
void StackInit(Stack* pst) {
assert(pst);
pst->array = (int*)malloc((? ) * sizeof(int));
if (NULL == pst->array) {
perror("malloc fail!\n");
exit(-1);
}
pst->size = 0;
pst->capacity = ? ;
}
针对这种情况,C++就引入了缺省参数来解决。
2、缺省参数的基本用法
缺省参数就是在函数定义时,在形参部分给一个“缺省值”:
void StackInit(Stack* pst, int n = 4) {
assert(pst);
pst->array = (int*)malloc((?n) * sizeof(int));
if (NULL == pst->array) {
perror("malloc fail!\n");
exit(-1);
}
pst->size = 0;
pst->capacity = n ;
}
当我们使用时,可以显示给值或者不显示给值: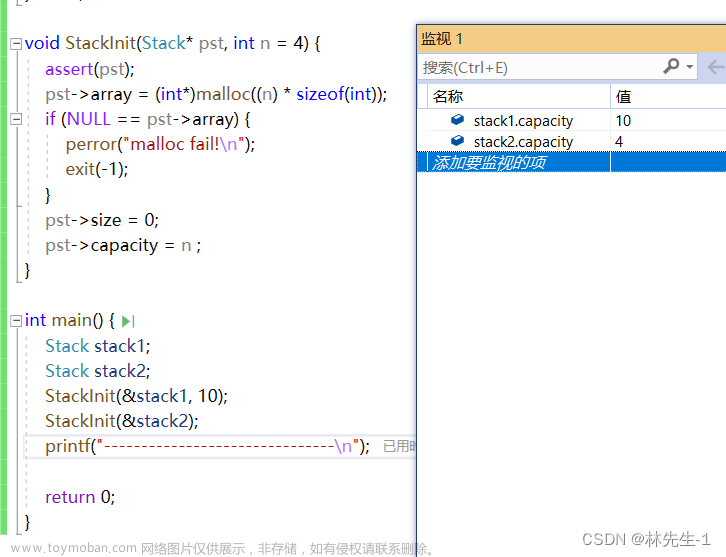
从结果中我们可以看出,当我们显示给值的时候,初始化用的n就是我们显示给的值,而当我们不显示给值的时候就是用的是默认的(缺省的)。
3、缺省的参数必须从右向左
在给缺省参数时,缺省参数的顺序一定是从右向左的,也就是说,缺省参数一定实在参数列表的右端并且一定是连续的,例如: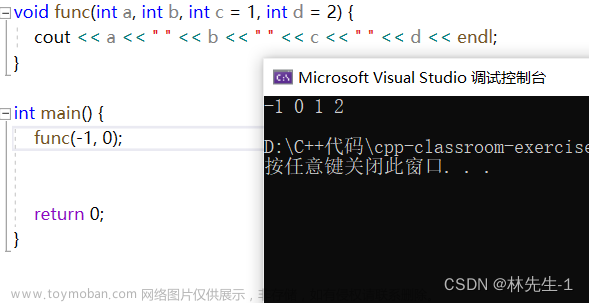
而不能出现下面这样的情况:
置于为什么要这样,只能说是“规定”,不要问为什么。
4、缺省参数不能声明和定义同时给
缺省参数还有一点需要注意的是,缺省参数不能声明和定义同时给: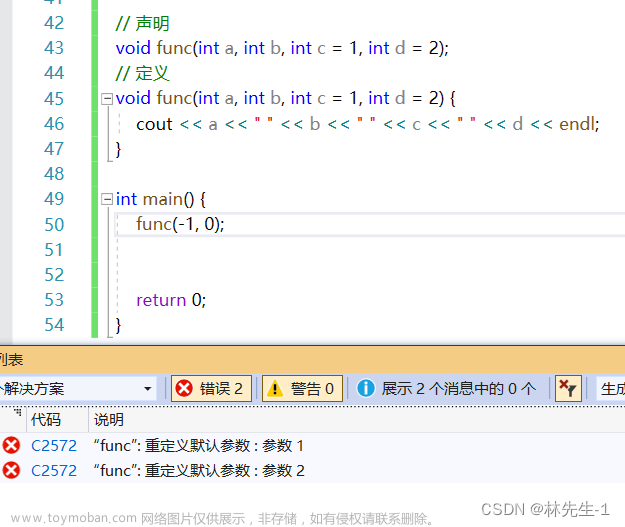
这样做的目的主要是为了防止声明和定义给的缺省值不一致,从而导致调用存在歧义。
但我们可以只在声明给,定义不给: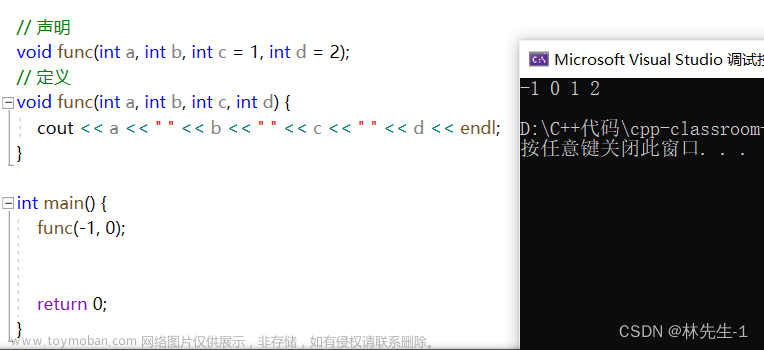
三、函数重载
1、为什么要引入函数重载?
我们在C语言中有时候会需要一些逻辑非常相似,但就是参数类型不同的函数,比如我们再排序中经常要使用到的交换两个变量的函数Swap,对于交换int和double类型,我们就必须写两个不同名的函数:
这样是不是很烦啊?
所以为了解决这个问题,C++就引入了函数重载。
2、函数重载的基本用法
有了函数重载,我们上面的这两个函数就可以同名了: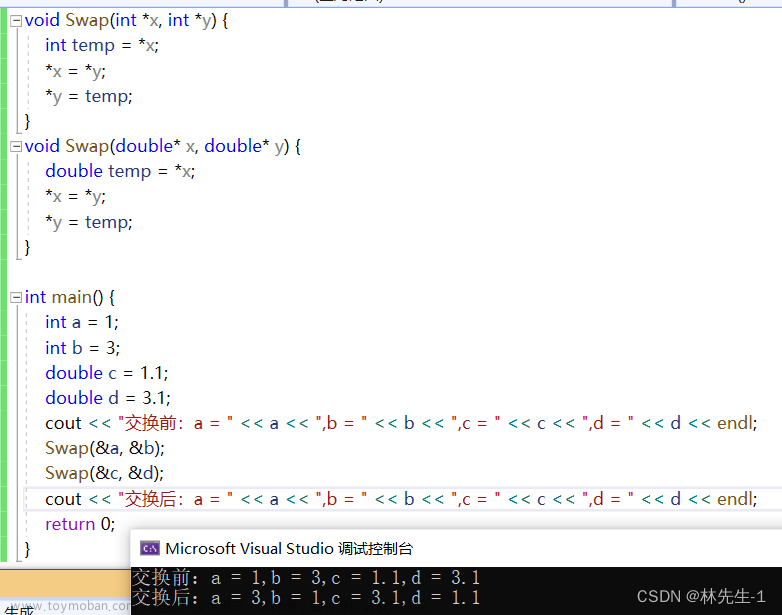
函数重载有三个要点:
1.参数的类型不同
2.参数的顺序不同(不同类型的参数的顺序不同)
3.参数的个数不同
上面的例子就是类型不同。
然后是参数的顺序不同,一定要是不同类型的参数的顺序不同,例如下面这个例子:
而如果只是参数名不同,而两个参数都是同一类型就会报错:
因为编译器是根据不同类型参数的位置来判断到底该调用哪一个函数的,这样做会让编译器存在歧义。
然后是个数不同:
这个祈其实就不用多说,编译器会根据参数的个数来判断到底该调用哪一个函数。
3、当函数重载跟缺省参数碰到一起
而如果函数重载跟缺省参数碰到一起,会发生什么呢?
例如下面这个例子: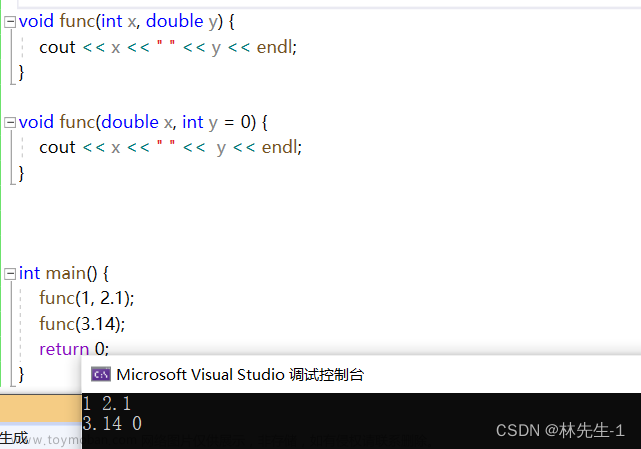
从结果我们可以看出是没问题的,因为它们之间符合了参数类型不同,而参数有没有缺省值是没有关系的。
但下面这个例子就不同了: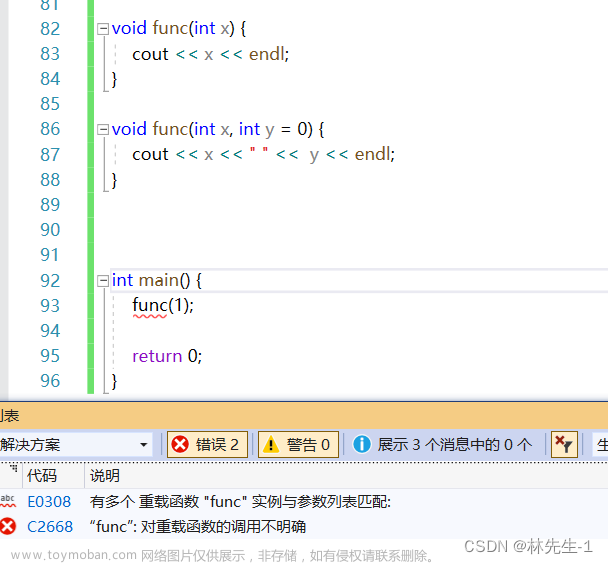
在这个例子中,虽然两个函数也满足了函数重载的条件只以——参数的个数不同,但是编译器在调用的时候可能会存在歧义,因为像上面这样只给一个参数的调用,对于两个函数来说都行得通,第一个函数本身就只有一个参数,而第二个有缺省值的函数只给一个参数也是能正常调用的。
所以如果在重载函数的时候想要给缺省参数,就一定要注意调用歧义的情况。
四、引用
1、为什么要引入引用?
我们都知道C语言有指针,但C++的祖师爷在使用指针的时候发现:C语言这个指针,用起来也太不方便了吧。例如我们要写一个交换函数Swap: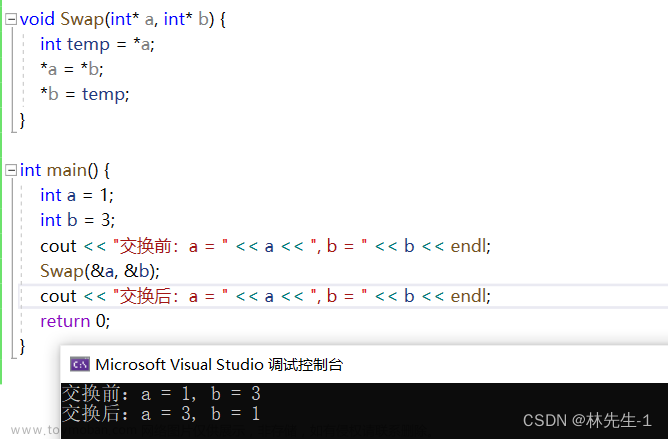
如上面这个例子,祖师爷觉得有两个地方很麻烦,一是在Swap函数内想要拿到数据就必须得对指针解引用,二是在调用的时候要对变量取地址。
所以祖师爷为了解决这两个问题,在C++中引入了引用。
2、引用的基本用法
引用如果按底层来理解,其实它也使用指针来实现的,只不过它较之指针使用起来更方便。
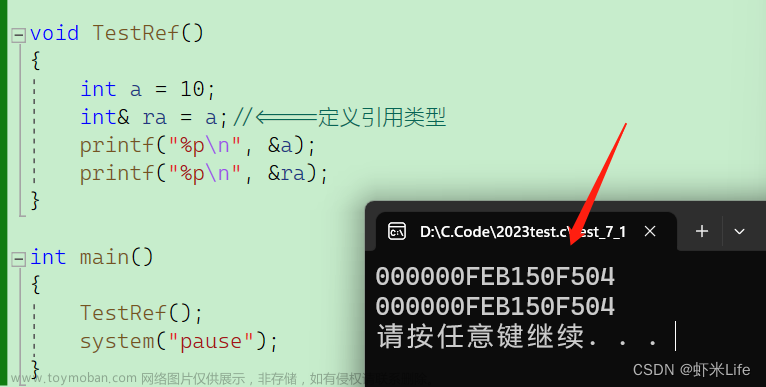
引用可以理解为是某一个变量的别名:
引用的定义形式如下:
int a = 1;
int& b = a;
以前在C++中的取地址操作符“&”,现在到了C++中就有了另一个功能,将其放在类型后面就表示某个类型的引用。
之所以称为“别名”是因为,引用基本可以当做被它引用的对象来使用,对引用进行自加自减,对象本身也会发生变化:
在使用引用时候需要注意的一点是引用必须在定义的时候初始化,所以也就不存在什么“野引用”的说法。
还有一点是引用的只想不能改变,也就是说一个引用只能做一个变量的别名,而不像指针一样能改变其指向。
3、引用做输出型参数
由于引用的特性,所以我们日后会经常使用引用来做输出型参数,比如我们现在实现一个简单的自加函数:
4、在引用的过程中权限不能放大
怎样理解这一点呢?先看下面这个例子:
报错的原因就是,引用将原本变量的权限放大了,我们知道const修饰的变量是只能读不能写的(不能改变),但引用默认是能读能写的,这样就是权限放大了。文章来源:https://www.toymoban.com/news/detail-635981.html
想要消除报错,就可以对引用也加上const: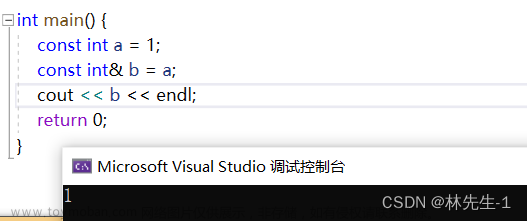
这成为“权限的平移”。
权限不仅可以“平移”,也可以“缩小”: 文章来源地址https://www.toymoban.com/news/detail-635981.html
文章来源地址https://www.toymoban.com/news/detail-635981.html
到了这里,关于【C++笔记】C++启航之为C语言填坑的语法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!