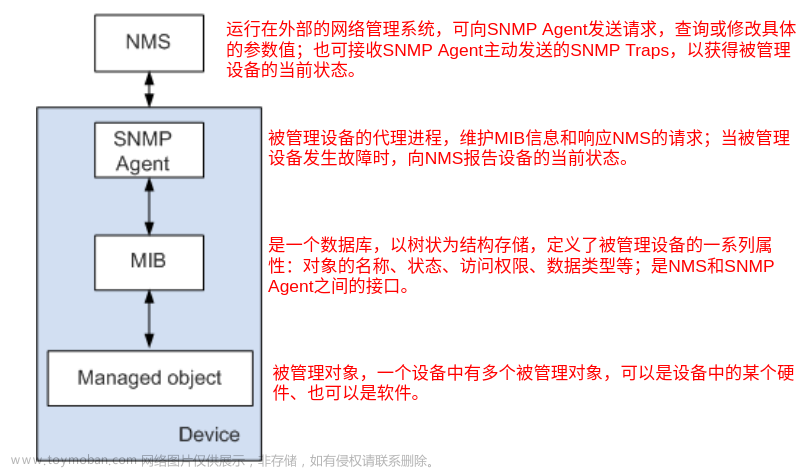
采集链路
dcgm-exporter
项目地址:https://github.com/NVIDIA/dcgm-exporter
dcgm-exporter主要用于将nvidia gpu的监控数据导出到prometheus里,符合prometheus的exporter规范。
deployment/templates/metrics-configmap.yaml定义了采集的指标名及具体含义,我们的场景下主要关注GPU和显存指标。
# Utilization (the sample period varies depending on the product) DCGM_FI_DEV_GPU_UTIL, gauge, GPU utilization (in %). -- GPU使用率(%) DCGM_FI_DEV_MEM_COPY_UTIL, gauge, Memory utilization (in %). -- 显存使用率(%) # Memory usage DCGM_FI_DEV_FB_FREE, gauge, Framebuffer memory free (in MiB). -- 空闲显存(MB) DCGM_FI_DEV_FB_USED, gauge, Framebuffer memory used (in MiB). -- 已用显存(MB)
部署
helm文档:https://helm.sh/zh/docs/
dcgm-exporter和prometheus-kafka-adapter都提供了helm部署方式,可以很方便的管理依赖。
部署dcgm-exporter前,需要对deployment/values.yaml的内容进行变更。
namespaceOverride: "kube-system" -- 重要组件部署在kube-system下
serviceMonitor:
enabled: true
interval: 60s -- 采集间隔,默认是15s(即每分钟采集4个点),为了处理方便,改为60s(也就是每分钟1个点)
honorLabels: false
additionalLabels: {}
#monitoring: prometheus
metricRelabelings:
- action: labelmap -- 配置一个labelmap规则,将exported_pod/exported_namespace这些tag转换为pod/namespace
regex: exported_(.*)
replacement: $1
nodeSelector:
nvidia-device-enable: enable -- 只对某些节点部署dcgm-exporter(按需添加)
#node: gpu
tolerations: [] -- nodeSelector所选的节点中可能存在taints导致部署不上去,此处按需添加tolerations
#- operator: Exists
kubeletPath: "/var/lib/kubelet/pod-resources" -- 如果集群内GPU机器对应目录下没有kubelet.sock文件,说明路径不对
注意事项
- 如果没有配置metricRelabelings,从prometheus拉取数据的时候,pod对应的是采集组件的pod名(也就是dcgm-exporter-xxx),namespace是kube-system。exported_pod和exported_namespace才是监控指标所属的pod和namespace。
- kubeletPath如果配置错误,会导致GPU的uuid无法关联到pod上,从prometheus拉取到的数据里就没有pod/namespace/exported_pod/exported_namesapce这些tag。且dcgm-exporter里会打印日志
No Kubelet socket, ignoring。
一些踩坑经验
网上一些部署教程发布的时间比较早,会建议使用https://github.com/NVIDIA/gpu-monitoring-tools来部署dcgm-exporter。
但是部署过程中,又需要部署pod-gpu-metrics-exporter,然而这个东西的部署脚本和镜像基本都找不到了。
所以最后只能单独部署一个低版本的dcgm-exporter。因为只能采集到GPU的uuid,没办法关联pod,又需要开发一个东西去做关联。
这里也卡住了我一两天,其实仔细下看gpu-monitoring-tools的readme,就能发现这个项目已经归档了,直接用NVIDIA/dcgm-exporter就行。
prometheus
部署方案就不写了(我是直接用的SAAS,实在是没部署经验。)
想验证GPU的监控正常采集到prometheus里,有两步检查过程。
- 首先可以看下dcgm-exporter有没有采集到相关指标。随便取一个dcgm-exporter pod,拿到容器ip,在集群内执行
curl ${pod_ip}:9400/metrics,如果能从返回值中看到DCGM_FI_DEV_GPU_UTIL这些指标,说明数据采集到了。这时候也可以看下pod/namespace/exported_pod/exported_namesapce这些tag是否都有(如果没有就看看kubeletPath是否设置正确),取值是否符合预期。 - 如果上一步没问题,再看看prometheus里的数据是否正常。
curl -H 'Authorization: xxx xxxxxx' -v -X GEThttp://${prometheus_ip}:9090/api/v1/query?query=DCGM_FI_DEV_GPU_UTIL。如果能拿到数据就说明没问题。
prometheus-kafka-adapter
项目地址:https://github.com/Telefonica/prometheus-kafka-adapter
这个组件主要是用于将Prometheus的数据导出到kafka,便于后续的数据处理(比如转存、归档)。
对于这类数据处理需求,也可以通过定时请求Prometheus去拉取数据。但是在集群内容器比较多的时候,拉取的数据量会非常大,延迟得不到保障,很容易出问题。
通过将数据导出到kafka,Prometheus就不再是性能瓶颈,从架构上也更低耦合。
部署
部署依旧使用helm,对helm/prometheus-kafka-adapter/values.yaml做一些修改即可。
environment:
# defines kafka endpoint and port, defaults to kafka:9092.
KAFKA_BROKER_LIST: "${your_broker_ips}" -- kafka broker列表
# defines kafka topic to be used, defaults to metrics.
KAFKA_TOPIC: "${your_topic}" -- kafka topic
service:
# To define a NodePort, overload in a custom values file
# type: NodePort
# nodeport: <value>
type: LoadBalancer -- 我用的是LoadBalancer,因为prometheus是单独申请的SAAS,需要保证集群外能访问这个service。
port: 80
annotations: {}
集群内部署好prometheus-kafka-adapter之后,还需要修改prometheus的配置,并重启Prometheus。主要是增加一条remote_write规则。文章来源:https://www.toymoban.com/news/detail-636237.html
remote_write:
- url: "http://${load_balancer_ip}:8080/receive"
总结
helm很好用,后续好好研究下。文章来源地址https://www.toymoban.com/news/detail-636237.html
到了这里,关于dcgm-exporter + prometheus + kafka-adapter采集GPU容器监控的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!