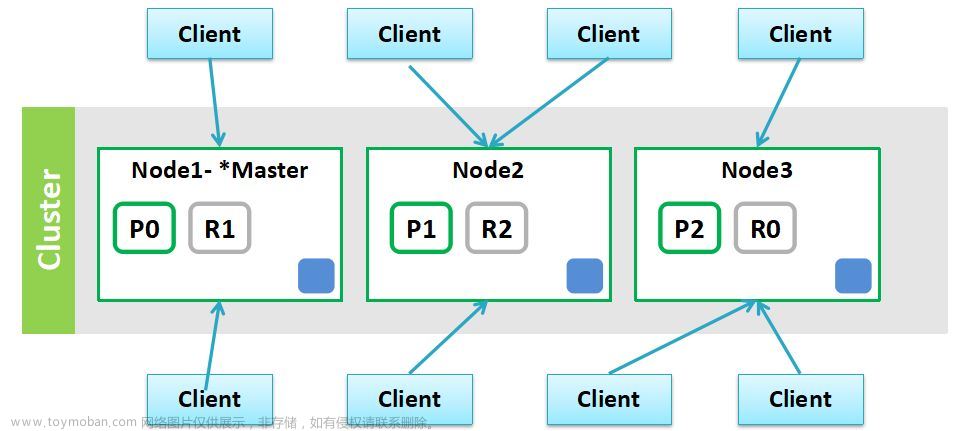
Elasticsearch-7.2.0+Logstash-7.2.0+Kibana-7.2.0+-Filebeat-7.6.0

第一台集群内网ip:10.0.0.223
ES配置文件:/es_data/es/elasticsearch-7.2.0/config/elasticsearch.yml
ES启动命令:/es_data/es/elasticsearch-7.2.0/bin/elasticsearch
cluster.name: es-search
node.name: node-machine-name
node.master: true
node.data: true
path.data: /es_data/data/es
path.logs: /es_data/log/es
transport.tcp.port: 9300
transport.tcp.compress: true
http.port: 9200
network.host: 10.0.0.223
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"
cluster.initial_master_nodes: ["10.0.0.223","10.0.1.9","10.0.1.10"]
discovery.seed_hosts: ["10.0.0.223", "10.0.1.10", "10.0.1.9"]
gateway.recover_after_nodes: 2
gateway.expected_nodes: 2
gateway.recover_after_time: 5m
action.destructive_requires_name: false
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 20gb
cluster.routing.allocation.disk.watermark.high: 10gb
cluster.routing.allocation.disk.watermark.flood_stage: 5gb
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# SecComp检测,是:true、否:false
bootstrap.system_call_filter: falseKibana配置文件:/es_data/es/kibana-7.2.0/config/kibana.yml
启动命令:/es_data/es/kibana-7.2.0/bin/kibana
server.port: 5601
server.host: "localhost"
server.basePath: ""
server.rewriteBasePath: false
elasticsearch.hosts:["http://10.0.0.223:9200","http://10.0.1.9:9200","http://10.0.1.10:9200"]
kibana.index: ".kibana"
i18n.locale: "zh-CN"Kibana nginx 代理配置文件
server {
listen 80;
server_name www.elasticsearch.com;
client_max_body_size 1000m;
location / {
proxy_read_timeout 300;
proxy_connect_timeout 300;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto http;
proxy_pass http://10.0.0.223:9200;
}
}第二台ES集群内网ip:10.0.1.10
ES配置文件:/es_data/es/elasticsearch-7.2.0/config/elasticsearch.yml
cluster.name: es-search
node.name: node-machine-name
node.master: true
node.data: true
path.data: /es_data/data/es
path.logs: /es_data/log/es
transport.tcp.port: 9300
transport.tcp.compress: true
http.port: 9200
network.host: 10.0.1.10
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"
cluster.initial_master_nodes: ["10.0.0.223","10.0.1.9","10.0.1.10"]
discovery.seed_hosts: ["10.0.0.223", "10.0.1.10", "10.0.1.9"]
gateway.recover_after_nodes: 2
gateway.expected_nodes: 2
gateway.recover_after_time: 5m
action.destructive_requires_name: false
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 20gb
cluster.routing.allocation.disk.watermark.high: 10gb
cluster.routing.allocation.disk.watermark.flood_stage: 5gb
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# SecComp检测,是:true、否:false
bootstrap.system_call_filter: false
Logstatsh 接收器配置
启动命令:/es_data/es/logstash-7.2.0/bin/logstash -f /es_data/es/logstash-7.2.0/conf.d/es_log.conf --path.data=/es_data/data/logstash/es_log/
配置文件:/es_data/es/logstash-7.2.0/conf.d/es_log.conf
input {
beats {
port => 5044
}
}
filter {
mutate {
split => ["message", "|"]
}
if [message][3] =~ '[0-9a-z]{40}' {
mutate {
add_field => { "log_time" => "%{[message][0]}"}
add_field => { "log_level" => "%{[message][1]}"}
add_field => { "log_process_id" => "%{[message][2]}"}
add_field => { "log_session" => "%{[message][3]}"}
add_field => { "log_file_name" => "%{[message][6]}"}
add_field => { "log_func_name" => "%{[message][7]}"}
add_field => { "log_line" => "%{[message][8]}"}
}
mutate {
update => { "message" => "%{[message][9]}" }
}
}
else if [message][2] =~ '[0-9a-z]+-[0-9a-z]+-[0-9a-z]+-[0-9a-z]+-[0-9a-z]' {
mutate {
add_field => { "log_time" => "%{[message][0]}"}
add_field => { "log_level" => "%{[message][1]}"}
add_field => { "log_process_id" => "%{[message][3]}"}
add_field => { "log_session" => "%{[message][2]}"}
add_field => { "log_thread_id" => "%{[message][4]}"}
add_field => { "log_file_name" => "%{[message][5]}"}
add_field => { "log_func_name" => "%{[message][6]}"}
add_field => { "log_line" => "%{[message][7]}"}
}
mutate {
update => { "message" => "%{[message][8]}" }
}
}
else
{
mutate {
split => ["message", ","]
}
mutate {
add_field => { "log_time" => "%{[message][0]}"}
add_field => { "log_level" => "%{[message][1]}"}
add_field => { "log_process_id" => "%{[message][2]}"}
}
mutate {
update => { "message" => "%{[message][3]}" }
}
}
mutate {
strip => ["log_time"]
}
}
output {
elasticsearch {
hosts => ["10.0.0.223:9200","10.0.1.10:9200","10.0.1.9:9200"]
index => "supervisor-log-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
第三台ES集群内网ip:10.0.1.9
ES配置文件:/es_data/elasticsearch-7.2.0/config/elasticsearch.yml
cluster.name: es-search
node.name: node-machine-name
node.master: true
node.data: true
path.data: /es_data/data/es
path.logs: /es_data/log/es
transport.tcp.port: 9300
transport.tcp.compress: true
http.port: 9200
network.host: 10.0.1.9
# 增加新的参数,这样head插件可以访问es (5.x版本,如果没有可以自己手动加)
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
http.cors.allow-headers: "X-Requested-With, Content-Type, Content-Length, X-User"
cluster.initial_master_nodes: ["10.0.0.223","10.0.1.9","10.0.1.10"]
discovery.seed_hosts: ["10.0.0.223", "10.0.1.10", "10.0.1.9"]
gateway.recover_after_nodes: 2
gateway.expected_nodes: 2
gateway.recover_after_time: 5m
action.destructive_requires_name: false
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 20gb
cluster.routing.allocation.disk.watermark.high: 10gb
cluster.routing.allocation.disk.watermark.flood_stage: 5gb
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# SecComp检测,是:true、否:false
bootstrap.system_call_filter: false第四台具体生产日志的地方
Filebeat配置:/www/filebeat/filebeat.yml
启动命令:/www/filebeat/filebeat -e -c /www/filebeat/filebeat.yml
- type: log
enabled: true
document_type: "supervisor"
exclude_files: ["filebeat-out.log$"]
paths:
- /var/log/supervisor/*.log
fields:
type: supervisor
encoding: plain
input_type: log
multiline.pattern: '^\s\d{4}\-\d{2}\-\d{2}\s\d{2}:\d{2}:\d{2}'
multiline.negate: true
multiline.match: after
# Filebeat modules
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
# Elasticsearch template setting
setup.template.settings:
index.number_of_shards: 1
index.number_of_replicas: 0
setup.template.overwrite: true
setup.template.name: "machine-name"
setup.template.pattern: "machine-name*"
# 生命周期管理
setup.ilm.enabled: true
setup.ilm.rollover_alias: "machine-name"
setup.ilm.pattern: "{now/d}-000001"
setup.ilm.policy_name: "machine-name-policy"
# Logstash output
output.logstash:
enabled: true
hosts: ["10.0.1.10:5044"]
worker: 1
compression_level: 3
loadbalance: true
pipelining: 0
index: 'log_index'
# Processors
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~Kibana 配置:
设置-索引模式:创建索引模式 supervisor-log-*
上面的索引管理里面就可以看到已经匹配的索引了文章来源:https://www.toymoban.com/news/detail-636857.html
创建生命周期策略-操作匹配索引模版,自动移除周期外的日志,保证集群健康运行文章来源地址https://www.toymoban.com/news/detail-636857.html
到了这里,关于Elasticsearch 集群日志收集搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!