什么是 LRU
在计算机系统中,LRU(Least Recently Used,最近最少使用)是一种缓存置换算法。缓存是计算机系统中的一种能够高速获取数据的介质,而缓存置换算法则是在缓存空间不足时,需要淘汰掉部分缓存数据以腾出空间,使得后来需要访问数据能够有更多的缓存空间可用。
LRU 算法将缓存中的数据分为“热数据”和“冷数据”,热数据是经常使用的数据,而冷数据很少使用。当缓存满了并有新数据需要加入缓存时,我们就需要通过LRU算法从缓存中淘汰一些数据,那么就淘汰最久未被访问的数据,也就是“冷数据”,而把“热数据”保留在缓存中,因为“热数据”很可能还会被使用,这样就能有效地提高了缓存的命中率,减少了内存的使用量,优化了系统的性能。
用通俗的话来说就是最近被频繁访问的数据会具备更高的留存,淘汰那些不常被访问的数据。
LRU 核心思想
LRU 的核心思想是“时间局部性原理”。这个原理表明在一段时间内程序访问的数据,很大概率在不久的将来还会访问,因此很可能被缓存起来。而很长时间不被访问的数据,很可能在不久的将来也不会被访问,因此被淘汰掉的概率很大。基于这个原理,LRU 算法要在缓存不够用时,先把缓存中很久没有被使用的数据替换掉,以此保证更常用的数据在缓存中,提高缓存的命中率。
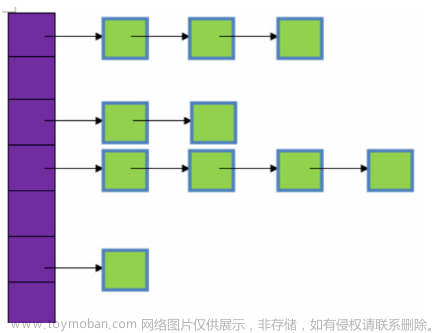
具体来说,在缓存对象中使用一个链表来维护缓存数据的顺序,每当缓存对象被使用时,将该数据从链表中移到链表末尾,每当缓存对象满时,将链表头部的数据淘汰。
这样保证了链表尾部的数据是最近被使用的数据,链表头部的数据是最久未被使用的,这样就可以通过移动链表节点来维护数据在缓存中的顺序,并淘汰链表头部的数据来保证缓存大小不大于某个限度,从而达到提高缓存命中率的目的。因此,LRU 算法的核心思想就是“淘汰最久未被使用的数据,保留近期最少使用的数据”,以此来优化系统的性能。
代码实现一:双向链表 + 哈希表
using System.Collections.Generic;
public class LRUCache<K, V>
{
private int capacity;
private Dictionary<K, LinkedListNode<Tuple<K, V>>> dict;
private LinkedList<Tuple<K, V>> linkedList;
public LRUCache(int capacity)
{
this.capacity = capacity;
this.dict = new Dictionary<K, LinkedListNode<Tuple<K, V>>>();
this.linkedList = new LinkedList<Tuple<K, V>>();
}
public V Get(K key)
{
if (!dict.ContainsKey(key))
{
return default(V);
}
var node = dict[key];
linkedList.Remove(node);
linkedList.AddLast(node);
return node.Value.Item2;
}
public void Put(K key, V value)
{
if (dict.ContainsKey(key))
{
var node = dict[key];
linkedList.Remove(node);
}
var newNode = new LinkedListNode<Tuple<K, V>>(Tuple.Create(key, value));
dict[key] = newNode;
linkedList.AddLast(newNode);
if (dict.Count > capacity)
{
var firstNode = linkedList.First;
linkedList.RemoveFirst();
dict.Remove(firstNode.Value.Item1);
}
}
}
// Usage:
var lruCache = new LRUCache<string, int>(2);
lruCache.Put("a", 1);
lruCache.Put("b", 2);
Console.WriteLine(lruCache.Get("a")); // Output: 1
lruCache.Put("c", 3);
Console.WriteLine(lruCache.Get("b")); // Output: 0 (not found)
分析
使用双向链表(双向链表节点具有指向前一个节点和后一个节点的指针)可以实现 O(1)时间删节点。在删除节点时,我们只需要更新它前一个节点的指针和后一个节点的指针,就可以把这个节点从链表中删除。
代码实现二:OrderedDictionary
using System.Collections.Specialized;
namespace Tools
{
public class LRUCache<K, V>
{
private OrderedDictionary dict;
private int capacity;
public LRUCache(int capacity)
{
this.capacity = capacity;
dict = new OrderedDictionary();
}
public V Pop(K key)
{
if (!dict.Contains(key))
{
return default(V);
}
var value = (V)dict[key];
dict.Remove(key);
dict.Add(key, value);
return value;
}
public void Push(K key, V value)
{
if (dict.Contains(key))
{
dict.Remove(key);
}
else if (dict.Count >= capacity)
{
dict.RemoveAt(0);
}
dict.Add(key, value);
}
}
}
分析
OrderedDictionary 是一个 C# 内置的数据结构,它是一个有序的键值对集合,支持按顺序获取和遍历键值对。
比较上一种实现方式的优点是:代码简洁,只使用一个数据结构。缺点是运行效率会慢。
OrderedDictionary与Dictionary类似,但是它具有以下不同之处:
- OrderedDictionary内部维护了一个按添加顺序排序的键列表。
- OrderedDictionary在内部使用了两个ArrayList,一个用于存储键,另一个用于存储与键相关联的值。这意味着OrderedDictionary的效率不如Dictionary高,因为每次检索或添加键值对时都需要额外的操作。
项目案例
在 Unity 开发中,我们很常用到对象池,所以我们可以使用 LRU 来对对象池进行优化,避免过多的内存占用。
预告
下一篇文章我们就来实战,实现一个 LRU 对象池。文章来源:https://www.toymoban.com/news/detail-637044.html
结尾
之前写过一篇关于对象池的文章,现在来看写的并不是很好,所以来考虑优化下。
Unity学习笔记–如何优雅简便地利用对象池生成游戏对象文章来源地址https://www.toymoban.com/news/detail-637044.html
到了这里,关于Unity学习笔记--使用 C# 开发一个 LRU的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!