本文包含如下内容:
① 通过图解+源码分析/A1/B1/node1和 /A1/B2/node2 这两个节点的网络距离怎么算出来的
② 客户端读文件时,副本的优先级。(怎么排序的,排序规则都有哪些?)
③ 我们集群发现的一个问题。
客户端读时,通过调用getBlockLocations RPC 获取文件的各个块。
在给客户端返回这些块信息之前,NameNode会对每个块的各个副本(例如默认的3副本)按照一定规则排序。
这些规则大概有:
① 把在decommissioned/stale/slow这些状态节点上的副本移到后面;
② 计算客户端与每个副本所在节点的网络距离,把距离小的放在前面;
③ 同时也会考虑 storage type、节点的load(Xceiver线程数)等因素。
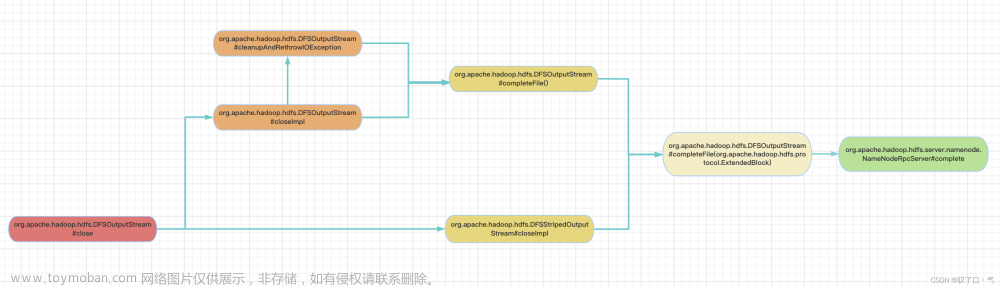
顺着 ClientProtocol#getBlockLocations 这个RPC方法往下找,最终找到相关的源码位置,
在org.apache.hadoop.hdfs.server.namenode.FSNamesystem#sortLocatedBlocks方法:文章来源:https://www.toymoban.com/news/detail-637407.html
此方法参数:文章来源地址https://www.toymoban.com/news/detail-637407.html
- clientMachine:代表客户端机器的字符串,一般是ip;
- blocks:客户端要读的文件的块的信息(LocatedBlocks对象里有LocatedBlock对象的列表)。
private 到了这里,关于【HDFS】客户端读某个块时,如何对块的各个副本进行网络距离排序?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!