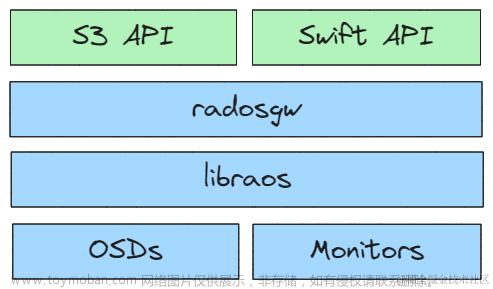
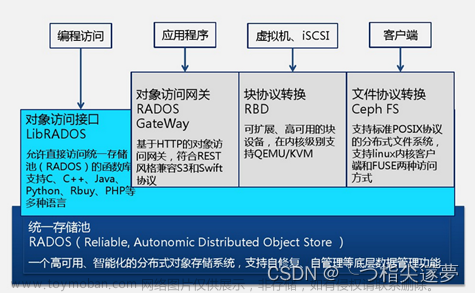
Ceph 可用于向云提供 Ceph 对象存储 平台和 Ceph 可用于提供 Ceph 块设备服务 到云平台。Ceph 可用于部署 Ceph 文件 系统。所有 Ceph 存储集群部署都从设置 每个 Ceph 节点,然后设置网络。
Ceph 存储集群需要满足以下条件:至少一个 Ceph 监控器,并且 至少一个 Ceph 管理器,以及至少与副本一样多的 Ceph OSD 存储在 Ceph 集群上的对象(例如,如果给定的三个副本 对象存储在 Ceph 集群上,则至少必须存在三个 OSD 那个 Ceph 集群)。
Ceph 元数据服务器是运行 Ceph 文件系统客户端所必需的。
CRUSH算法通过计算数据存储位置来确定如何存储和检索数据。CRUSH使Ceph客户机能够直接与OSDs通信,而不是通过集中的服务器或代理。通过算法确定的数据存储和检索方法,Ceph避免了单点故障、性能瓶颈和对其可伸缩性的物理限制。 #pic_center
#pic_center
Pools:Ceph 将数据存储在池中,池是用于 存储对象。存储池管理归置组的数量、 副本,以及池的 CRUSH 规则。要在池中存储数据,它是 必须是具有池权限的经过身份验证的用户。Ceph 是 能够制作池的快照。
Placement Groups:Ceph 将对象映射到归置组。放置 组 (PG) 是放置的逻辑对象池的分片或片段 对象作为一个组到 OSD 中。归置组可减少 Ceph 在 OSD 中存储数据所需的对象元数据。
CRUSH Maps:CRUSH 在允许 Ceph 扩展方面发挥着重要作用,而 避免某些陷阱,例如性能瓶颈、限制 可扩展性和单点故障。粉碎地图提供物理 将集群的拓扑转换为 CRUSH 算法,以便它可以确定两者 (1) 对象及其副本的数据应存储在哪里,以及 (2) 如何跨故障域存储该数据以提高数据安全性。
Balancer:平衡器是一项自动优化的功能 在设备之间分配归置组,以实现 平衡的数据分布,以最大化数据量可以 存储在集群中,以便均匀分配工作负载 跨 OSD。
部署方式:
Cephadm 安装并管理 Ceph 使用容器和 systemd 并与 CLI 紧密集成的集群 和仪表板图形用户界面。
CEPHADM 仅支援 Octopus 及更新版本。
cephadm 与编排 API 完全集成,完全支持 用于管理群集部署的 CLI 和仪表板功能。
cephadm 需要容器支持(以 Podman 或 Docker 的形式)和 蟒蛇 3.
Rook 部署和管理正在运行的 Ceph 集群 在 Kubernetes 中,同时还支持存储资源的管理和 通过 Kubernetes API 进行配置。我们推荐 Rook 作为运行 Ceph 的方式 Kubernetes 或将现有的 Ceph 存储集群连接到 Kubernetes。
Rook 仅支持 Nautilus 和较新版本的 Ceph。
Rook 是在 Kubernetes 上运行 Ceph 的首选方法,或者 将 Kubernetes 集群连接到现有(外部)Ceph 簇。
Rook 支持业务流程协调程序 API。CLI 中的管理功能和 完全支持仪表板。
Ceph-Ansible 被广泛部署。
ceph-ansible 但是仪表板集成不是 在通过 ceph-ansible 部署的 Ceph 集群中可用。
Ceph-Deploy 是一个 可用于快速部署集群的工具。它已被弃用

cephadm :
cephadm管理 Ceph 集群的整个生命周期。此生命周期开始 通过引导过程,当在 上创建一个微小的 Ceph 集群时 单个节点。此群集由一个监视器和一个管理器组成。 然后使用编排接口扩展集群,添加 主机和配置 Ceph 守护程序和服务。此生命周期的管理 可以通过 Ceph 命令行界面 (CLI) 或通过 仪表板 (GUI)
cephadm在 Ceph 版本 v15.2.0中引入 (centos7只能安装到15.2.17,更高版本要是用centos8)
安装依赖包和工具:
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
yum install net-tools wget lsof python3 bash-completion lvm2 -y
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
#安装docker
yum install -y docker-ce
下载cephadm:
CEPH_RELEASE=17.2.6 # replace this with the active release
curl --silent --remote-name --location https://download.ceph.com/rpm-${CEPH_RELEASE}/el9/noarch/cephadm
chmod +x cephadm
./cephadm add-repo --release quincy
./cephadm install
which cephadm 如果/usr/sbin/cephadm 就表示安装成功了
安装ceph-common ceph-fuse (可选,安装是为了直接使用ceph命令 当然也可以不安装使用后面的cephadm shell)
cephadm install ceph-common ceph-fuse
指定ceph安装使用的源
cat >/etc/yum.repos.d/ceph.repo <<EOF
[Ceph]
name=Ceph packages for \$basearch
baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/\$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.aliyun.com/ceph/rpm-octopus/el8/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
EOF
配置节点免密:
注意每个节点要配置hosts
172.16.88.13 ceph-1
172.16.88.14 ceph-2
172.16.88.15 ceph-3
for i in tail -n 4 /etc/hosts | awk '{print $1}'; do ssh-copy-id -i ~/.ssh/id_rsa.pub $i;done
初始化集群:
cephadm bootstrap --mon-ip *<mon-ip>* 然后你会看到该输出
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph-88-13:8443/
User: admin
Password: 3w0ujolsfi
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/788b7912-4ac8-11ed-bef2-005056bc091f/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
使用cephadm shell 然后ceph status 或者是ceph status命令可查看集群状态(注意cephadm shell是新启动一个容器然后调用ceph命令)
#查看所有组件运行状态
ceph orch ps
#查看某组件运行状态
ceph orch ps --daemon-type mon
ceph orch ps --daemon-type mgr
ceph orch ps --daemon-type mds
#查看集群状态
ceph status
#查看版本
ceph -v
ceph.conf
mon_osd_nearfull_ratio
告警水位,集群中的任一OSD空间使用率大于等于此数值时,集群将被标记为NearFull,此时集群将产生告警,并提示所有已经处于NearFull状态的OSD
默认值:0.85
mon_osd_full_ratio
报停水位,集群任意一个OSD使用率大于等于此数值时,集群将被标记为full,此时集群停止接受客户端的写入请求
默认值:0.95
mon_osd_backfillfull_ratio
OSD空间使用率大于等于此数值时,拒绝PG通过Backfill方式迁出或者继续迁入本OSD
默认值:0.90
ceph osd set-full-ratio 0.75
ceph osd set-backfillfull-ratio 0.75
ceph osd set-nearfull-ratio 0.75文章来源:https://www.toymoban.com/news/detail-637426.html
cephadm shell 然后ceph osd dump | grep full_ratio 查看具体的值文章来源地址https://www.toymoban.com/news/detail-637426.html
到了这里,关于ceph相关概念和部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!