目录
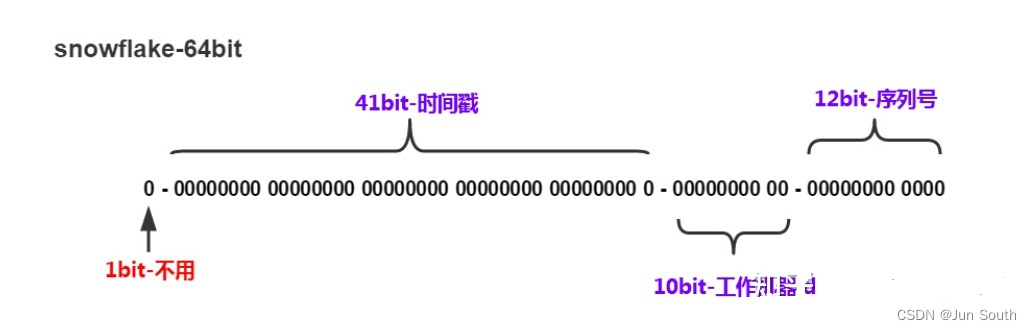
雪花id
tinyid
uuid
分布式id特点
业务编号
数据中心编号
当前时间
ip地址
当前序号
对于时钟回拨问题
发号器机器当期时间小于redis的时间
解决步骤
发号器机器当期时间等于redis时间
发号器机器当期时间大于redis最大的时间(相关的key不存在)
分布式id的单次获取和批次获取
在工作过程中接触了很多id生成策略,但是有一些问题
雪花id
强依赖时钟,对于时钟回拨无法很好解决
tinyid
滴滴开源,依赖mysql数据库,自增,无业务属性
uuid
生成是一个字符串没有顺序,数据库索引组织数据是按顺序处理,如果用于主键存储,对于数据库来说会造成频繁的索引页合并,增加数据库的负担,不建议。
还有其他的id生成策略,对于一些简单的应用可以
分布式id特点
个人考虑,分布式id需要具有的特点如下
唯一性
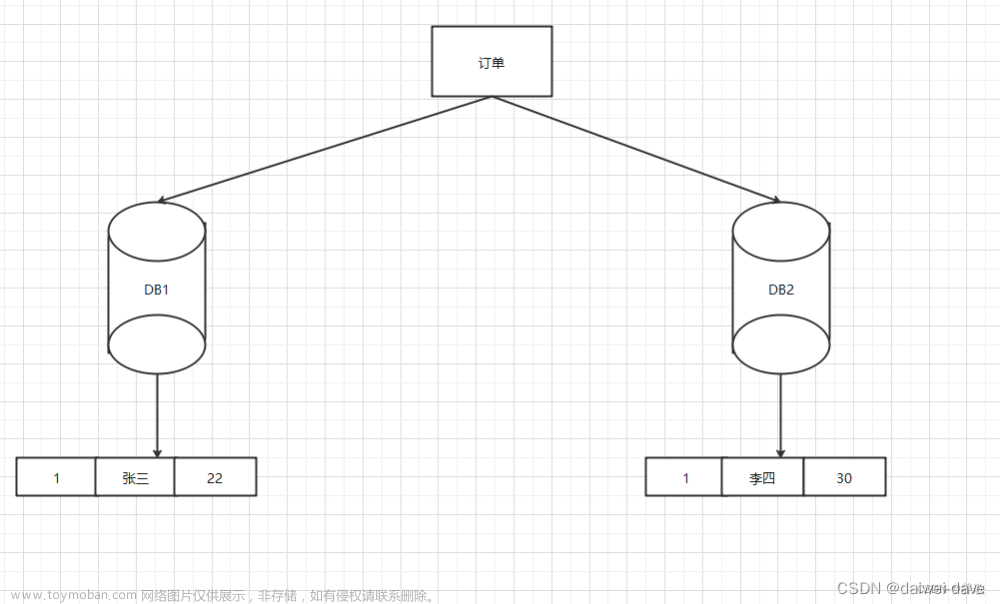
在所有的环境中都能确保唯一性,保证幂等,防止重复提交,存储时对应数据库主键。
业务编号
通过此信息可以确定此编号是用于干什么的
数据中心编号
对于大型的互联网项目,会有分区域部署的情况,分流、负载均衡
当前时间
当前时间精确到秒,可以到毫秒,例如雪花算法到毫秒
ip地址
对于集群使用,用于记录当前请求服务节点的ip,好知道是哪个节点发起的请求,需要将Ip转int进行处理
当前序号
从1开始,可以做成自增
拿经常使用的myql来说,索引中数据排序是按照主键来的,所以全部用数字来表示,考虑到上面的特点排序以及长度如下
业务标识(7位)+当前时间(年月日时分秒,yyyyMMddHHmmss,14位)+序号(19位)+数据中心编号(5位)+ip地址(10位)
当前id为55位,这样的id可读性强,看到这个id就知道哪个业务什么时候的数据,长度需要根据实际情况进行调整,核心是当前时间和序号,其他是辅助因素
业务标识,7位,最多代表9999999种业务,对于互联网公司一般来说足够了
当前时间,14位,精确到秒
数据中心,5位,一般足够
ip地址,对于地址进行int转换,10位
序号,19位,对应long类型的有符号最大值,与当前时间进行组合,一秒内生成19位id足够了
对于数据库分页查询来讲,查询的时候需要确保此id属于哪个业务,先按条件进行匹配最大的数据id,然后根据此id进行范围匹配,这样可以最大限度使用索引,防止过多数据加载到内存中通过偏移量只选其中一部分数据。
对于时钟回拨问题
使用redis存储当前时间和序号,对于redis做sentinel三节点高可用。如果访问量大的话,搭建redis集群。
对于高并发,需要调整对应的配置参数,节点无法访问后能快速切换。
发号器时间一般默认取当前程序部署所在的操作系统的时间。
在获取id之前,在redis中通过lua脚本判断发号器当前时间对应的key是否存在,不存在则创建,进行自增且返回自增id,否则对当前时间对应的key进行自增处理。
发号器机器当期时间小于redis的时间
即redis存储的时间在后,发号器当前时间在前,发号器当前时间滞后,如下
发号器当前时间
20230727121210
redis当前存储时间
20230727121211这种情况有可能是时钟回拨,是异常事件,会造成id重复导致插入数据库异常的情况。
解决步骤
- 为了不影响现有的数据,在现有的发号器当前时间对应的序号基础上进行自增
- 设置key的过期时间为60秒或者更长时间后防止时钟回拨对key进行自增操作key却找不到的情况
发号器机器当期时间等于redis时间
如下
发号器当前时间
20230727121211
redis当前存储时间
20230727121211如果key存在,说明当前时间已经使用了,属于正常操作。在现有的发号器当前时间对应的序号基础上进行自增。
发号器机器当期时间大于redis最大的时间(相关的key不存在)
如下
发号器当前时间
20230727121212
redis当前存储时间
20230727121211说明发号器时间发生了变化,当前时间是新的,属于正常操作。按照发号器的时间处理,序号设置从0开始自增,需要事务锁定当前时间和序号,防止后面的请求造成争用。
对于redis的特性,单线程多个请求过来需要入队列、高并发,对应事务和lua脚本,事务多个命令执行,不保证原子性。基于lua脚本操作的原子性,可以考虑每次请求调用lua脚本进行序号自增。具体是否需要使用redis的分布式锁redlock,需要有待验证,分布式锁的原理也是借助于lua脚本来处理。
对应lua脚本判断逻辑如下
判断当前时间对应key是否存在
如果不存在 创建对应的key,对当前key进行自增操作
如果存在,对当前key进行自增操作
| 场景 | 发号器机器当期时间小于redis的时间 | 发号器机器当期时间等于redis时间 | 发号器机器当期时间大于redis最大的时间 |
| 对应redis中key的情况 | 可能对应的 key 不存在 | key存在 | key不存在 |
| 是否异常情况 | 是,时钟回拨 | 否,当前时间正常执行 | 否,新时间操作 |
| 解决办法 | 此种情况需要确保 redis 中 key 存在,可以设置对应的 key 过期时长为1天,防止夜里出现这个问题,为问题解决留了充足时间,防止对应的 key 找不到 id 获取异常的情况 | redis 中 key 存在,正常自增 | redis 中 key 不存在,先创建,再正常自增 |
lua脚本
local flag = redis.call('exists', KEYS[1]);
if (flag == 0) then
set KEYS[1] 0;
incrby KEYS[1] ARGV[1];
return get KEYS[1];
else
incrby KEYS[1] ARGV[1];
return get KEYS[1];
end;从redis 6 开始支持多线程,对于redis并发特性,做了一下测试
redis 5 单线程
redis-benchmark -t set,get -n 100000 -r 100000 -d 512 -c 500 -q
SET: 83472.46 requests per second
GET: 80971.66 requests per secondredis 6 两个线程
redis-benchmark -t set,get -n 200000 -r 200000 --threads 2 -d 1024 -c 500 -q
SET: 152788.39 requests per second
GET: 161681.48 requests per second可知,在两个线程下多了一倍吞吐。
上面这些可以做成一个web服务,在 k8s 中做成一个负载均衡服务,请求时传入当前节点所在的数据中心id和业务id,对服务进行压力测试,看看瓶颈在哪里再做调整。
分布式id的单次获取和批次获取
按照发号器获取id的可能性,分为单次获取和批次获取。
默认获取是单次,即在当前时间基础上自增。
对于批量插入数据的情况,使用批次获取,这样可以减少请求次数,效率更高。文章来源:https://www.toymoban.com/news/detail-638326.html
127.0.0.1:6379> set 20230805163025 0 ex 60
OK
127.0.0.1:6379> incrby 20230805163025 1
(integer) 1
127.0.0.1:6379> incrby 20230805163025 1000
(integer) 1001分布式id 如果在redis层次没有拦截住,加上数据库主键做约束,双重机制来确保此id在所有的数据中只有一份。文章来源地址https://www.toymoban.com/news/detail-638326.html
到了这里,关于对于现有的分布式id发号器的思考 id生成器 雪花算法 uuid的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!