背景
因为最近看到一个软件可以实现网页的识别,自动导入网页的内容,感觉这个功能很厉害(真心佩服设计那个软件的人)。但不清楚这个软件的网页识别的实现,也没有接触过相关的技术,就上网搜索并学习一些相关的技术,所以有了这篇文章。但是只能获取简单的请求,一些复杂的请求获取不了(会报错,说是解析不了获取的preflight ---> 好像是一个涉及跨域请求的东西)。ps:很希望有懂的大佬也可以在评论区解答一下(非常感谢!~~)
最后,虽然是刚入门,但分享这个的初衷,是用于帮助其他伙伴对一些软件功能的实现提供一些思路。
程序实现
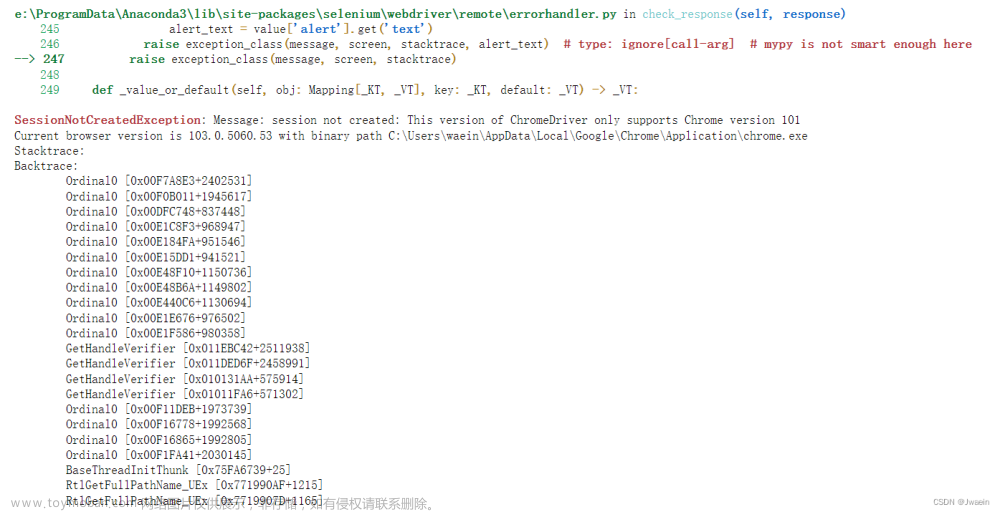
步骤一:就是要下载Chormedriver和对应版本的Chrome浏览器(要对应版本哦,一般你原先下载的浏览器都是最新版本的,很可能版本不对应)
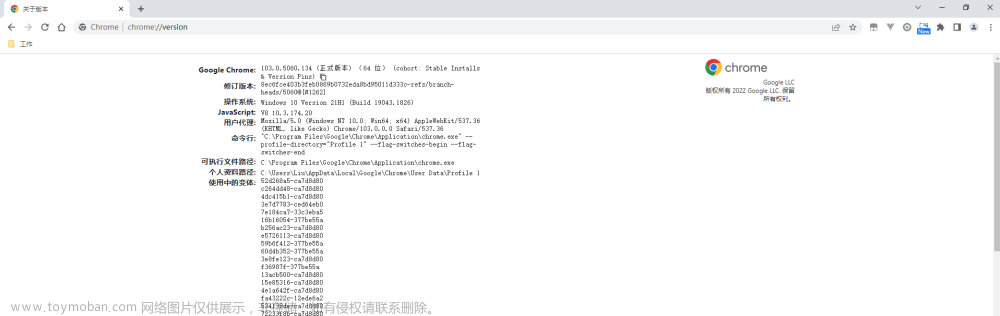
打开Chrome 测试可用性仪表板https://googlechromelabs.github.io/chrome-for-testing/在里面找到想下载Chrome,这里我是使用114.0.5735.133
打开https://chromedriver.storage.googleapis.com/index.html?path=114.0.5735.90/https://chromedriver.storage.googleapis.com/index.html?path=114.0.5735.90/
这个也是适配114版本的浏览器的Chormedriver
把它们下载解压到自己的电脑能找到的位置(下面是我存放的位置):


步骤二:
打开idea,导入需要的maven依赖
<dependencies>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.10.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chromium-driver</artifactId>
<version>4.10.0</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-devtools-v114</artifactId>
<version>4.10.0</version>
</dependency>
</dependencies>步骤三:
编写程序代码
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.devtools.DevTools;
import org.openqa.selenium.devtools.v85.network.Network;
import java.util.*;
public class Test {
public static void main(String[] args) {
// 设置 ChromeDriver 路径
System.setProperty("webdriver.chrome.driver", "D:\\Chromedriver_win32\\chromedriver.exe");
// 创建 ChromeOptions 实例并设置 User-Agent
ChromeOptions options = new ChromeOptions();
options.setBinary("D:\\Cho114\\Cho\\chrome-win64\\chrome.exe");
// 创建 ChromeDriver 并传入 ChromeOptions
WebDriver driver = new ChromeDriver(options);
// 启用 Chrome DevTools
DevTools devTools = ((ChromeDriver) driver).getDevTools();
devTools.createSession();
List<String> requests = new ArrayList<>();
List<String> responses = new ArrayList<>();
devTools.addListener(Network.requestWillBeSent(), request -> {
String requestType = String.valueOf(request.getType());
if (requestType.equals("Fetch") || requestType.equals("XHR")) {
requests.add(request.getRequest().getUrl());
}
});
devTools.addListener(Network.responseReceived(), response -> {
String requestType = String.valueOf(response.getType());
if (requestType.equals("Fetch") || requestType.equals("XHR")) {
responses.add(response.getResponse().getUrl());
}
});
// 启用监听器
devTools.send(Network.enable(Optional.empty(), Optional.empty(), Optional.empty()));
// 访问目标网页
driver.get("https://www.目标.com/");
// 关闭浏览器
driver.quit();
System.err.println(responses.size()+"----------分割线----------");;
requests.forEach(System.out::println);
System.err.println(responses.size()+"----------分割线----------");
responses.forEach(System.out::println);
}
}
(记得把目标网站换一下)
结果
ChromeDriver代码演示视屏
运行程序就可以了(上面也有一些,一些接口获取不了的报错)ui
最后,文章来源:https://www.toymoban.com/news/detail-638526.html
希望文章对你有所帮助!文章来源地址https://www.toymoban.com/news/detail-638526.html
到了这里,关于Java爬虫 通过Chromedriver+Chrome浏览器+selenium获取页面的请求和响应(未完全实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!