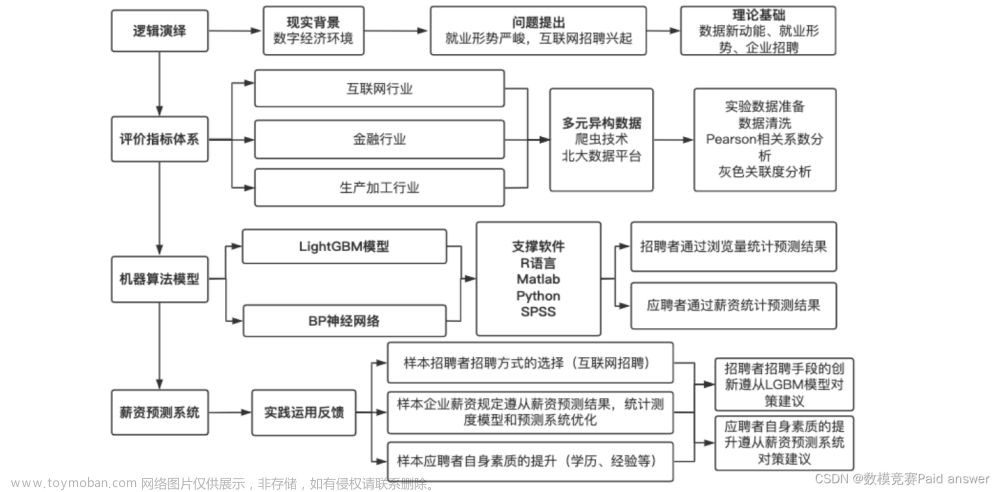
在本文中,我们将尝试实现一个机器学习模型,该模型可以预测在不同商店销售的不同产品的库存量。
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D阵列格式加载数据帧,并具有多种功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -这个库用于绘制可视化。
- Sklearn -此模块包含多个库,这些库具有预实现的功能,以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error as mae
import warnings
warnings.filterwarnings('ignore')
现在,让我们将数据集加载到panda的数据框中,并打印它的前五行。
df = pd.read_csv('StoreDemand.csv')
display(df.head())
display(df.tail())

如我们所见,我们有10家商店和50种产品的5年数据,可以计算得,
(365 * 4 + 366) * 10 * 50 = 913000
现在让我们检查一下我们计算的数据大小是否正确。
df.shape
输出:
(913000, 4)
让我们检查数据集的每列包含哪种类型的数据。
df.info()

根据上面关于每列数据的信息,我们可以观察到没有空值。
df.describe()

特征工程
有时候,同一个特征中提供了多个特征,或者我们必须从现有的特征中派生一些特征。我们还将尝试在数据集中包含一些额外的功能,以便我们可以从我们拥有的数据中获得一些有趣的见解。此外,如果导出的特征是有意义的,那么它们将成为显著提高模型准确性的决定性因素。
parts = df["date"].str.split("-", n = 3, expand = True)
df["year"]= parts[0].astype('int')
df["month"]= parts[1].astype('int')
df["day"]= parts[2].astype('int')
df.head()

无论是周末还是工作日,都必须对满足需求的要求产生一定的影响。
from datetime import datetime
import calendar
def weekend_or_weekday(year,month,day):
d = datetime(year,month,day)
if d.weekday()>4:
return 1
else:
return 0
df['weekend'] = df.apply(lambda x:weekend_or_weekday(x['year'], x['month'], x['day']), axis=1)
df.head()

如果有一个列可以表明某一天是否有任何假期,那就太好了。
from datetime import date
import holidays
def is_holiday(x):
india_holidays = holidays.country_holidays('IN')
if india_holidays.get(x):
return 1
else:
return 0
df['holidays'] = df['date'].apply(is_holiday)
df.head()

现在,让我们添加一些周期特性。
df['m1'] = np.sin(df['month'] * (2 * np.pi / 12))
df['m2'] = np.cos(df['month'] * (2 * np.pi / 12))
df.head()

让我们有一个列,其值指示它是一周中的哪一天。
def which_day(year, month, day):
d = datetime(year,month,day)
return d.weekday()
df['weekday'] = df.apply(lambda x: which_day(x['year'],
x['month'],
x['day']),
axis=1)
df.head()

现在让我们删除对我们无用的列。
df.drop('date', axis=1, inplace=True)
可能还有一些其他相关的特征可以添加到这个数据集中,但是让我们尝试使用这些特征构建一个构建,并尝试提取一些见解。
探索性数据分析
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。
我们使用一些假设向数据集添加了一些功能。现在让我们检查不同特征与目标特征之间的关系。
df['store'].nunique(), df['item'].nunique()
输出:
(10, 50)
从这里我们可以得出结论,有10个不同的商店,他们出售50种不同的产品。
features = ['store', 'year', 'month',\
'weekday', 'weekend', 'holidays']
plt.subplots(figsize=(20, 10))
for i, col in enumerate(features):
plt.subplot(2, 3, i + 1)
df.groupby(col).mean()['sales'].plot.bar()
plt.show()

现在让我们来看看随着月末的临近,库存的变化情况.
plt.figure(figsize=(10,5))
df.groupby('day').mean()['sales'].plot()
plt.show()

让我们画出30天的表现。
plt.figure(figsize=(15, 10))
# Calculating Simple Moving Average
# for a window period of 30 days
window_size = 30
data = df[df['year']==2013]
windows = data['sales'].rolling(window_size)
sma = windows.mean()
sma = sma[window_size - 1:]
data['sales'].plot()
sma.plot()
plt.legend()
plt.show()

由于sales列中的数据是连续的,让我们检查它的分布,并检查该列中是否有一些离群值。
plt.subplots(figsize=(12, 5))
plt.subplot(1, 2, 1)
sb.distplot(df['sales'])
plt.subplot(1, 2, 2)
sb.boxplot(df['sales'])
plt.show()

高度相关的特征
plt.figure(figsize=(10, 10))
sb.heatmap(df.corr() > 0.8,
annot=True,
cbar=False)
plt.show()

正如我们之前所观察到的,让我们删除数据中存在的离群值。
df = df[df['sales']<140]
模型训练
现在,我们将分离特征和目标变量,并将它们分为训练数据和测试数据,我们将使用这些数据来选择在验证数据上表现最好的模型。
features = df.drop(['sales', 'year'], axis=1)
target = df['sales'].values
X_train, X_val, Y_train, Y_val = train_test_split(features, target,
test_size = 0.05,
random_state=22)
X_train.shape, X_val.shape
输出:
((861170, 9), (45325, 9))
在将数据输入机器学习模型之前对其进行标准化,有助于我们实现稳定和快速的训练。
# Normalizing the features for stable and fast training.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
我们将数据分为训练数据和验证数据,并对数据进行了归一化。现在,让我们训练一些最先进的机器学习模型,并使用验证数据集从中选择最佳模型。文章来源:https://www.toymoban.com/news/detail-639530.html
models = [LinearRegression(), XGBRegressor(), Lasso(), Ridge()]
for i in range(4):
models[i].fit(X_train, Y_train)
print(f'{models[i]} : ')
train_preds = models[i].predict(X_train)
print('Training Error : ', mae(Y_train, train_preds))
val_preds = models[i].predict(X_val)
print('Validation Error : ', mae(Y_val, val_preds))
输出:文章来源地址https://www.toymoban.com/news/detail-639530.html
LinearRegression() :
Training Error : 20.902897365994484
Validation Error : 20.97143554027027
[08:31:23] WARNING: /workspace/src/objective/regression_obj.cu:152:
reg:linear is now deprecated in favor of reg:squarederror.
XGBRegressor() :
Training Error : 11.751541013057603
Validation Error : 11.790298395298885
Lasso() :
Training Error : 21.015028699769758
Validation Error : 21.071517213774968
Ridge() :
Training Error : 20.90289749951532
Validation Error : 20.971435731904066
到了这里,关于基于机器学习的库存需求预测 -- 机器学习项目基础篇(12)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!