The multimodal MRI brain tumor segmentation based on AD-Net
摘要
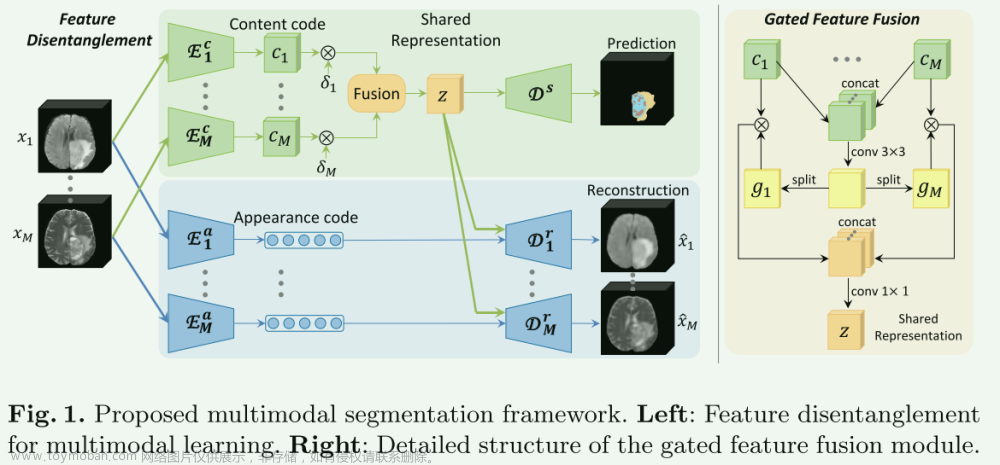
基于磁共振成像(MRI)的多模态胶质瘤图像提供了肿瘤边界的不同特征,其中多模态特征的提取对于深度学习分割方法来说往往具有挑战性。不同模态特征之间的干扰是制约多模态学习的重要因素。为了有效地提取多模态特征,我们提出了一种自动加权扩张卷积网络(AD-Net),通过通道特征分离学习来学习多模态脑肿瘤特征。
其中,自加权扩张卷积单元(AD单元)利用双尺度卷积特征映射获取信道分离特征。我们在编码层中采用两个可学习参数融合双尺度卷积特征映射,并随着梯度的反向传播自动调整两个可学习参数。我们采用Jensen-Shannon散度来约束其特征映射的分布,进而正则化整个下采样的权值。此外,我们采用深度监督训练技术来实现快速拟合。我们提出的方法在BraTS20数据集上对整个肿瘤(WT)、肿瘤核心(TC)和增强肿瘤(ET)的骰子得分分别为0.90、0.80和0.76。实验结果表明,该算法在AD-Net网络下具有良好的性能。
本文方法



这篇文章是基于输入融合的
损失函数



实验结果


max-vit - unet:多轴注意力医学图像分割
摘要
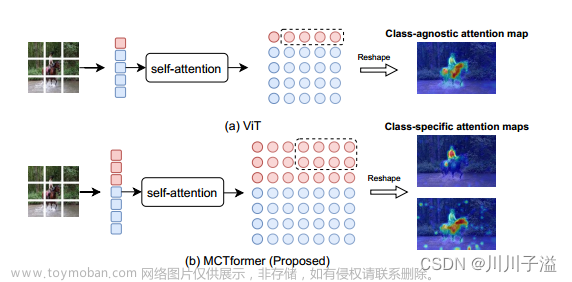
卷积神经网络(cnn)近年来在医学图像分析方面取得了重大进展。然而,卷积算子的局部性质可能会对cnn中捕获全局和远程相互作用造成限制。最近,transformer由于能够有效地处理全局特征而在计算机视觉社区和医学图像分割中得到了广泛的应用。自关注机制的可扩展性问题和缺乏类似cnn的归纳偏差可能限制了它们的采用。因此,利用卷积和自关注机制的优点的混合视觉变压器(CNN-Transformer)变得越来越重要。
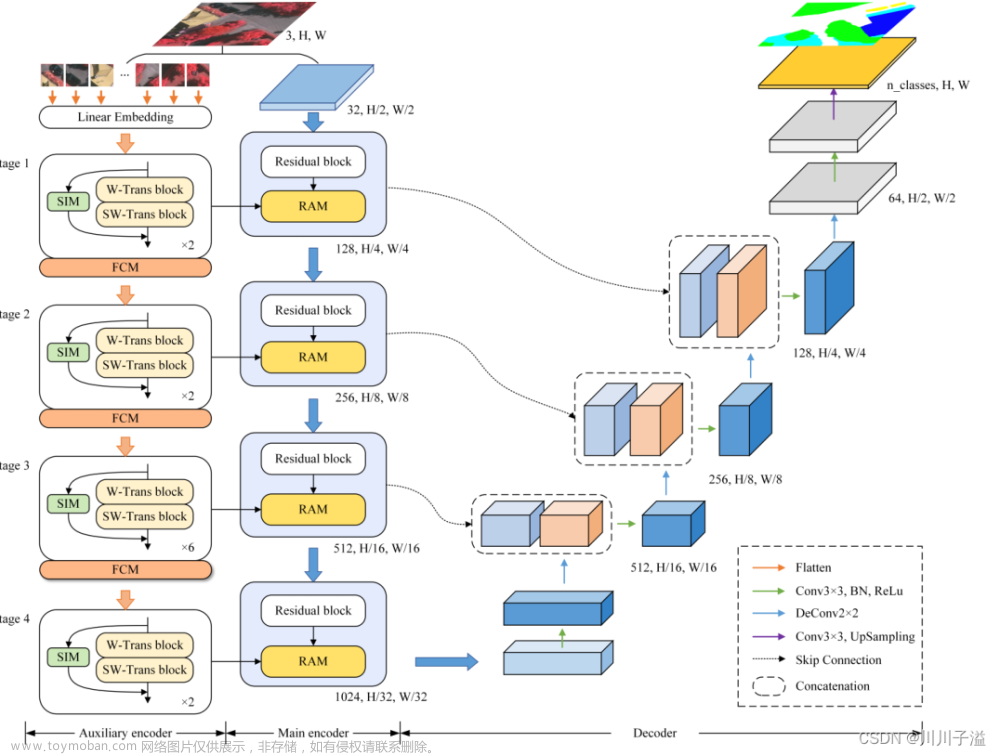
在这项工作中,我们提出了maxviti - unet,一种基于编码器-解码器的混合视觉转换器(CNN-Transformer),用于医学图像分割。
所提出的混合解码器,基于maxviti -block,设计利用卷积和自注意机制的力量,在每个解码阶段的计算负担很小。
在每个解码阶段中加入多轴自关注,显著增强了目标和背景区域的区分能力,从而有助于提高分割效率。
在混合解码器块中,融合过程开始于将通过转置卷积获得的上采样低电平解码器特征与从混合编码器获得的跳过连接特征进行整合。
随后,通过利用多轴注意机制对融合的特征进行细化。所提出的解码器块被重复多次以逐步分割核区域。在MoNuSeg18和MoNuSAC20数据集上的实验结果证明了该方法的有效性。我们的maxviti -UNet在两个标准数据集上都比之前基于cnn (UNet)和基于transformer (swan -UNet)的技术有相当大的优势。代码地址
本文方法

 文章来源:https://www.toymoban.com/news/detail-639571.html
文章来源:https://www.toymoban.com/news/detail-639571.html
实验结果
 文章来源地址https://www.toymoban.com/news/detail-639571.html
文章来源地址https://www.toymoban.com/news/detail-639571.html
到了这里,关于8.10论文阅读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[论文阅读]PANet(PAFPN)——用于实例分割的路径聚合网络](https://imgs.yssmx.com/Uploads/2024/02/751327-1.png)