提要:本系列文章主要参考MIT 6.828课程以及两本书籍《深入理解Linux内核》 《深入Linux内核架构》对Linux内核内容进行总结。
内存管理的实现覆盖了多个领域:
- 内存中的物理内存页的管理
- 分配大块内存的伙伴系统
- 分配较小内存的slab、slub、slob分配器
- 分配非连续内存块的vmalloc分配器
- 进程的地址空间
内存管理实际分配的是物理内存页,因此,了解物理内存分布是十分必要的。
物理内存布局
在初始化阶段,内核必须建立一个物理地址映射来指定哪些物理地址范围对内核可用而哪些不可用(或者因为它们映射硬件设备I/O的共享内存,或者因为相应的页框含有BIOS数据)。
内核将下列页框记为保留:
- 在不可用的物理地址范围内的页框
- 含有内核代码和已初始化的数据结构的页框。
保留页框中的页决不能被动态分配或交换到磁盘上。
例如,MIT 6.828 Lab2 -> Part 1: Physical Page Management -> page_init() 方法的实现中,注释如下:
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
MIT 6.828中,主机的物理内存布局如下:
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
注释中的(1)(3)这两项就是不可用的物理地址范围内的页框,而(4)就指的是含有内核代码和已初始化的数据结构的页框。一般来说,Linux内核安装在RAM中从物理地址0x00100000(1MB)开始的地方(详见https://www.cnblogs.com/yanlishao/p/17557668.html),当然这只是一个固定的地址。那么为何内核没有安装在RAM的第一MB开始的地方呢?由上图可以看出,第一个MB中很多内存由BIOS和硬件使用,因此不是连续的,会被切分成很多小块。具体描述如下:
- 页框0由BIOS使用,存放加电自检(Power-On Self-Test,POST)期间检查到的系统硬件配置。因此,很多膝上型电脑的BIOS甚至在系统初始化后还将数据写到该页框。
- 物理地址从0x000a0000到0x000ffff的范围通常留给BIOS例程,并且映射ISA图形卡上的内部内存。这个区域就是所有IBM兼容PC上从640KB到1MB之间著名的洞:物理地址存在但被保留,对应的页框不能由操作系统使用。
- 第一个MB内的其他页框可能由特定计算机模型保留。例如,IBM Thinkpnd把0xa0页框映射到0x9f页框。
但是由于各种硬件和BIOS不同,因此,保留内存也有差异,因此新近的计算机中,内核调用BIOS过程建立一组物理地址范围和其对应的内存类型,最后映射成一张[start,end, TYPE]的表,TYPE表示内存是否可用。在系统启动时,找到的内存区由内核函数print_memory_map显示。形如下表:

最后,下图给出物理内存最低几M字节的布局:

前1MB的内存布局在前面已经介绍过,为了避免把内核装入一组不连续的页框里,Linux更愿跳过RAM的第一个MB。因此,内核会装载在物理地址0x00100000开始的地方。
- _text和 _etext是代码段的起始和结束地址,包含了编译后的内核代码。
- 数据段位于 _etext和 _edata之间,保存了大部分内核变量。
- 初始化数据在内核启动过程结束后不再需要(例如,包含初始化为0的所有静态全局变量的BSS段)保存在最后一段,从_edata到_end。在内核初始化完成后,其中的大部分数据都可以从内存删除,给应用程序留出更多空间。这一段内存区划分为更小的子区间,以控制哪些可以删除,哪些不能删除,但这对于我们现在的讨论没多大意义。
在运行内核时,可以通过/proc/iomem获得内核的相关信息:

共享存储型多处理机模型
本部分引用知乎大佬的文章,原链接
进行内存管理,一个很重要的因素就是CPU对内存的访问方式,所以难免要对此部分进行介绍。
共享存储型多处理机有两种模型:
- 均匀存储器存取(Uniform-Memory-Access,简称UMA)模型 (一致存储器访问结构)
- 非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型 (非一致存储器访问结构)
UMA模型
UMA模型将多个处理机与一个集中的存储器和I/O总线相连,物理存储器被所有处理机均匀共享,所有处理机对所有的存储单元都具有相同的存取时间。SMP(对称型多处理机)系统有时也被称之为一致存储器访问(UMA)结构体系。

UMA模型的最大特点就是共享。在该模型下,所有资源都是共享的,包括CPU、内存、I/O等。也正是由于这种特性,导致了UMA模型可伸缩性非常有限,因为内存是共享的,CPUs都会通过一条内存总线连接到内存上,这时,当多个CPU同时访问同一个内存块时就会产生冲突,因此当存储器和I/O接口达到饱和的时候,增加处理器并不能获得更高的性能。
NUMA模型
NUMA模型的基本特征是具有多个CPU模块,每个CPU模块又由多个CPU core(如4个)组成,并具有本地内存、I/O接口等,所以可以支持CPU对本地内存的快速访问。这里我们把CPU模块称为节点,每个节点被分配有本地存储器,各个节点之间通过总线连接起来,这样可以支持对其他节点中的本地内存的访问,当然这时访问远的内存就要比访问本地内存慢些。所有节点中的处理器都能够访问全部的物理存储器。

NUMA模型的最大优势是伸缩性。与UMA不同的是,NUMA具有多条内存总线,可以通过限制任何一条内存总线上的CPU数量以及依靠高速互连来连接各个节点,从而缓解UMA的瓶颈。NUMA理论上可以无限扩展的,但由于访问远地内存的延时远远超过访问本地内存,所以当CPU数量增加时,系统性能无法线性增加。
内核处理
内核对一致和非一致内存访问系统使用相同的数据结构,因此针对各种不同形式的内存布局,各个算法几乎没有什么差别。在UMA系统上,只使用一个NUMA结点来管理整个系统内存。而内存管理的其他部分则相信它们是在处理一个伪NUMA系统。
根据对NUMA模型的描述,Linux将内存进行了如下划分:
- 存储节点(Node):是每个CPU对应的一个本地内存,在内核中表示为
pg_data_t的实例。因为CPU被划分为多个节点,内存被划分为簇,每个CPU都对应一个本地物理内存,即一个CPU Node对应一个内存簇bank,即每个内存簇被认为是一个存储节点。在UMA结构下,只存在一个存储节点。 - 内存域(Zone):由于硬件制约,每个物理内存节点Node被划分为多个内存域, 用于表示不同范围的内存, 内核可以使用不同的映射方式映射物理内存。
- 页面(Page):各个内存域都关联一个数组,用来组织属于该内存域的物理内存页(页帧)。页面是最基本的页面分配的单位

接下来对这3层数据结构进行简单介绍。
Node — pg_data_t
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
struct page *node_mem_map;
struct bootmem_data *bdata;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* 物理内存页的总数 */
unsigned long node_spanned_pages; /* 物理内存页的总长度,包含洞在内 */
int node_id;
struct pglist_data *pgdat_next;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
int kswapd_max_order;
} pg_data_t;
| 属性名 | 描述 |
|---|---|
| node_zones | 包含了结点中各内存域的数据结构 |
| node_zonelists | 指定了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存(这个字段将在后面介绍页分配器时再提到) |
| nr_zones | 结点中管理区的个数 |
| node_mem_map | 指向page实例数组的指针,用于᧿述结点的所有物理内存页。它包含了结点中所有内存域的页。 |
| bdata | 在系统启动期间,内存管理子系统初始化之前,内核也需要使用内存(另外,还必须保留部分内存用于初始化内存管理子系统)。为解决这个问题,内核使用了自举内存分配(boot memory allocator)。bdata指向自举内存分配器数据结构的实例 |
| node_start_pfn | 该NUMA结点第一个页帧的逻辑编号。系统中 结点的页帧是依次编号的,每个页帧的号码都是全局唯一的(不只是结点内唯一)。node_start_pfn在UMA系统中总是0,因为其中只有一个结点,因此其第一个页帧编号总是0。 node_present_pages指定了结点中页帧的数目,而node_spanned_pages则给出了该结点以页帧为单位计算的长度。二者的值不一定相同,因为结点中可能有一些空洞,并不对应真正的页帧 |
| node_id | 全局结点ID。系统中的NUMA结点都从0开始编号 |
| pgdat_next | 连接到下一个内存结点,系统中所有结点都通过单链表连接起来,其末尾通过空指针标记。 |
| kswapd_wait | 交换守护进程(swap daemon)的等待队列,在将页帧换出结点时会用到。kswapd指向负责该结点的交换守护进程的task_struct。kswapd_max_order用于页交换子系统的实现,来定义需要释放的区域的长度(我们当前不感兴趣)。 |
注意:
- 所有结点的描述符存放在一个单向链表中,其首结点为pgdat_list。如果采用的是UMA模型,那么这唯一一个元素还会被放在contig_page_data变量中。
- 结点的内存域保存在node_zones[MAX_NR_ZONES]。该数组总是有3个项(这3个项是什么,看下一小节),即使结点没有那么多内存域,也是如此。如果不足3个,则其余的数组项用0填充
如果系统中结点多于一个,内核会维护一个位图,用以ᨀ供各个结点的状态信息。状态是用位掩码指定的,可使用下列值:
enum node_states {
N_POSSIBLE, /* 结点在某个时候可能变为联机 */
N_ONLINE, /* 结点是联机的 */
N_NORMAL_MEMORY, /* 结点有普通内存域 */
#ifdef CONFIG_HIGHMEM
N_HIGH_MEMORY, /* 结点有普通或高端内存域 */
#else
N_HIGH_MEMORY = N_NORMAL_MEMORY,
#endif
N_CPU, /* 结点有一个或多个CPU */
NR_NODE_STATES
};
Zone - zone
在之前讨论了,由于计算机体系结构有硬件的制约,这限制了页框可以使用的方式,尤其是,Linux内核必须处理80x86体系结构的两种硬件约束:
- ISA总线的直接内存存取(DMA)处理器有一个严格的限制:它们只能对RAM的前16MB寻址。
- 在具有大容量RAM的现代32位计算机中,CPU不能直接访问所有的物理内存,因为线性地址空间太小。
为了应对这两种限制,Linux2.6把每个内存节点的物理内存划分为3个管理区(zone),在80x86UMA体系结构中的管理区为:
| 名称 | 描述 |
|---|---|
| ZONE_DMA | 包含低于16MB的内存页框 |
| ZONE_DMA32 | 使用32位地址字可寻址、适合DMA的内存域。显然,只有在64位系统上,两种DMA内存域才有差别 |
| ZONE_NORMAL | 包含高于16MB且低于896MB的内存页框 |
| ZONE_HIGHMEM | 包含从896MB开始高于896MB的内存页框 |
enum zone_type {
#ifdef CONFIG_ZONE_DMA
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
ZONE_DMA32,
#endif
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
MAX_NR_ZONES
};
这里我们了解了16MB这个界限的来历,那么896MB这个界限是怎么回事呢??
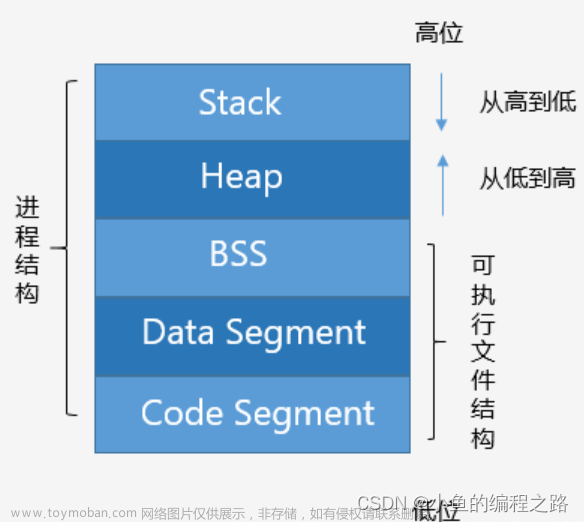
Linux默认按照3:1的比例将地址空间划分给用户态和内核态,32位操作系统上内核空间的大小就是1GB(4GB按照3:1划分),内核空间又分为各个段,如下图:

直接映射区域从0xC0000000到high_memory地址,high_memory通常为896MB。high_memory由下面的宏具体决定,该
//arch/x86/kernel/setup_32.c
static unsigned long __init setup_memory(void)
{
...
#ifdef CONFIG_HIGHMEM
high_memory = (void *) __va(highstart_pfn * PAGE_SIZE -1) + 1;
#else
high_memory = (void *) __va(max_low_pfn * PAGE_SIZE -1) + 1;
#endif
...
}
max_low_pfn指定了物理内存数量小于896 MiB的系统上内存页的数目。该值的上界受限于896 MiB可容纳的最大页数(具体的计算在find_max_low_pfn给出),因此high_memory通常为896MB。剩下的128MB通常用作如下用途(如下三种用途的具体介绍有机会会仔细讲解):
- 虚拟内存中连续、但物理内存中不连续的内存区,可以在vmalloc区域分配
- 持久映射用于将高端内存域中的非持久页映射到内核中
- 固定映射是与物理地址空间中的固定页关联的虚拟地址空间项,但具体关联的页帧可以自由选择。
可以看到直接映射的最大空间长度为896MB,如果物理内存超过896MB,则内核无法直接映射全部内存。
最后看一下内存中表示Zone的数据结构zone,其各个字段所代表的含义:
struct zone {
/*通常由页分配器访问的字段 */
unsigned long pages_min, pages_low, pages_high;
unsigned long lowmem_reserve[MAX_NR_ZONES];
struct per_cpu_pageset pageset[NR_CPUS];
/*
* 不同长度的空闲区域
*/
spinlock_t lock;
struct free_area free_area[MAX_ORDER];
ZONE_PADDING(_pad1_)
/* 通常由页面收回扫描程序访问的字段 */
spinlock_t ru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long pages_scanned; /* 上一次回收以来扫᧿ 过的页 */
unsigned long flags; /* 内存域标志,见下文 */
/* 内存域统计量 */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
int prev_priority;
ZONE_PADDING(_pad2_)
/* 很少使用或大多数情况下只读的字段 */
wait_queue_head_t * wait_table;
unsigned long wait_table_hash_nr_entries;
unsigned long wait_table_bits;
/* 支持不连续内存模型的字段。 */
struct pglist_data *zone_pgdat;
unsigned long zone_start_pfn;
unsigned long spanned_pages; /* 总长度,包含空洞 */
unsigned long present_pages; /* 内存数量(除去空洞) */
/*
* 很少使用的字段:
*/
char *name;
} ____cacheline_maxaligned_in_smp;
这里主要介绍内存管理的核心字段,将在后面比较频繁的出现,对于其他的字段,我们使用到的时候再进行介绍。
- pages_min、pages_high、pages_low是页换出时使用的
watermark,也就是一些界限。如果内存不足,内核可以将页写到硬盘。这3个成员会影响交换守护进程的行为。- 如果空闲页多于pages_high,则内存域的状态是理想的。
- 如果空闲页的数目低于pages_low,则内核开始将页换出到硬盘。
- 如果空闲页的数目低于pages_min,那么页回收工作的压力就比较大,因为内存域中急需空闲页。
- lowmem_reserve数组分别为各种内存域指定了若干页,
用于一些无论如何都不能失败的关键性内存分配。 - pageset是一个数组,
用于实现每个CPU的热/冷页帧列表。内核使用这些列表来保存可用于满足实现的“新鲜”页。但冷热页帧对应的高速缓存状态不同:- 有些页帧也很可能仍然在高速缓存中,因此可以快速访问,故称之为热的;
- 未缓存的页帧与此相对,故称之为冷的。
- free_area是同名数据结构的数组,用于实现伙伴系统
Page - page
由于我们现在讨论的都是对物理内存的管理,即页框的管理,那么记录页框的状态是无法避免的,因此,操作系统提供了页描述符用于完成该任务,即struct page结构体。
struct page {
unsigned long flags; /* 原子标志,有些情况下会异步更新 */
atomic_t _count; /* 使用计数,见下文。 */
union {
atomic_t _mapcount; /* 内存管理子系统中映射的页表项计数,
* 用于表示页是否已经映射,还用于限制逆向映射搜索。
*/
unsigned int inuse; /* 用于SLUB分配器:对象的数目 */
};
union {
struct {
unsigned long private; /* 由映射私有,不透明数据:
* 如果设置了PagePrivate,通常用于
buffer_heads;
* 如果设置了PageSwapCache,则用于
swp_entry_t;
* 如果设置了PG_buddy,则用于表示伙伴系统中的
阶。
*/
struct address_space *mapping; /* 如果最低位为0,则指向inode
* address_space,或为NULL。
* 如果页映射为匿名内存,最低位置位,
* 而且该指针指向anon_vma对象:
* 参见下文的PAGE_MAPPING_ANON。
*/
};
...
struct kmem_cache *slab; /* 用于SLUB分配器:指向slab的指针 */
struct page *first_page; /* 用于复合页的尾页,指向首页 */
};
union {
pgoff_t index; /* 在映射内的偏移量 */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* 换出页列表,例如由zone->lru_lock保护的active_list!
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* 内核虚拟地址(如果没有映射则为NULL,即高端内存) */
#endif /* WANT_PAGE_VIRTUAL */
};
这里我们介绍一些对我们讨论的内容比较重要的属性。
| 属性名 | 描述 |
|---|---|
| flags | 包含多达32个用来描述页框状态的标志 |
| _count | 页的引用计数器(这里两本参考书有分歧,不做具体描述) |
| _mapcount | 表示在页表中有多少项指向该页 |
| lru | 是一个表头,用于在各种链表上维护该页,以便将页按不同类别分组,最重要的类别是活动和不活动页。 |
| private | 指向“私有”数据的指针,虚拟内存管理会忽略该数据。根据页的用途,可以用不同的方式使用该指针 |
| virtual | l用于高端内存区域中的页,换言之,即无法直接映射到内核内存中的页。virtual用于存储该页的虚拟地址 |
在本部分的最后,给出一个flags标志中可选标志的表,方便后期查看。
 文章来源:https://www.toymoban.com/news/detail-639950.html
文章来源:https://www.toymoban.com/news/detail-639950.html
总结
本节主要讲解了物理内存的布局以及内存管理模块的主要数据结构,下一节我们会描述内核在启动时是如何初始化这些结构的,为后面讲解内存分配算法做准备。文章来源地址https://www.toymoban.com/news/detail-639950.html
到了这里,关于深入理解Linux内核——内存管理(2)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!